Multiple ways to go about this, so you’ll end up getting a lot of different-but-similar advice from different people. So, I’m just going to write down how I personally approach this. (WALL OF TEXT ALERT, sorry ! this is usually easier to demo than to write down about.)
Fastai + Jupyter live inspection method
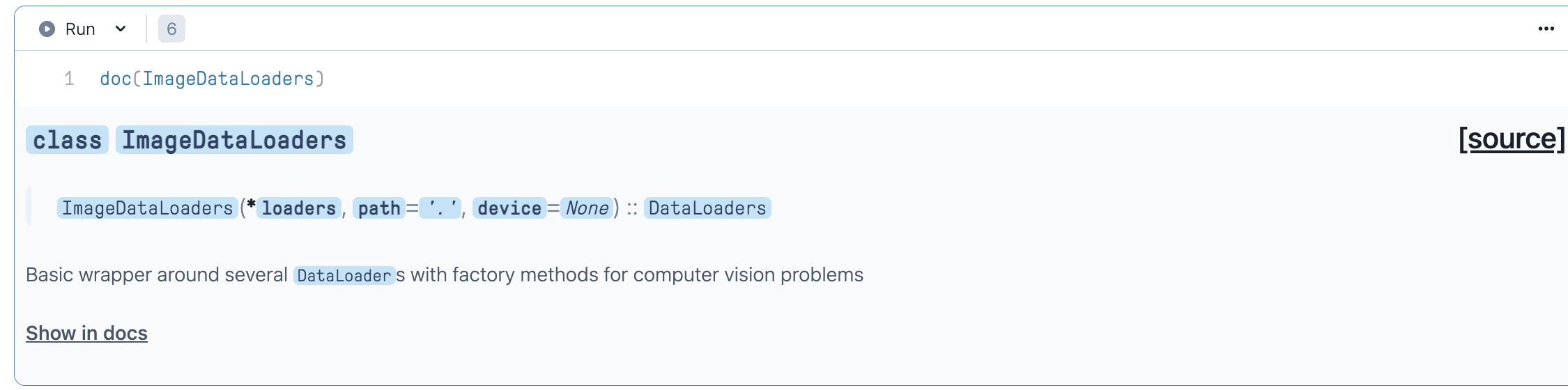
One thing Jeremy has already demo-ed is the usage of ?, ?? & doc in the Jupyter environment. These provide a pretty good place to start, so a good idea to get comfortable with those. Calling the doc on a python object can actually point you to the source in fastai repositories directly. Try running the following in your jupyter environment. ( after importing from fastai.vision.all import * )
?get_image_files??get_image_files-
doc(get_image_files)← This points you to the exact lines in the fastai repo
Searching in a codebase via editor / command line method
The other method (in my case) is to approach the codebase like I do with any other one. There’s usually two main stages (and appropriate tools for them)
Stage 1. Searching for a keyword / idea
In this phase, I use tools that can quickly find all entries of a text/pattern I’m looking for. I use a tool called rg, but the idea is similar to other tools like ag & grep, or search built-in to the editor you use.
You use this tool to narrow down your search space and find things you might be looking for. If you don’t know the codebase at all, there’ll be some guessing involved. (eg. rg adam, rg Adam, rg optimizer, rg opt and so on…)
Your editor might already have built in support for searching for keywords. So, you can just start with that, no need for external tools really. As long as it’s fast, it’ll work fine. For eg. Search across files in vscode.
NOTE : For the fastai repo, you want your searches to be done not at the top level, but inside the fastai folder. That way you exclude results from other than the pure python files.
Stage 2. Load the file in your editor and start “jumping” to definitions
In this phase I open the corresponding file in my editor, get to the line/col where I was searching the above term. Now I just try to “walk” the codebase.
When there’s a new function/variable that I want to know more about, I try to “jump to” where it was defined. Once I understand it, I “jump back” to where I came from. This has to be supported by your editor. If you’re using vscode, Go To Definition & Go Back is what you’re looking for. I don’t use VSCode a lot yet, so hopefully somebody else can chime in more on that.
Either ways, taking the time to
a) learn how to find the keywords, and
b) learn how to “jump in” and “jump back out” using your editor+language
can be really useful if you plan to have an easier time browsing a codebase.
I hope this was somewhat helpful. ![]()