In the previous version of fastai I used this to balance a highly imbalanced dataset:
class ImbalancedDatasetSampler(torch.utils.data.sampler.Sampler):
"""Samples elements randomly from a given list of indices for imbalanced dataset
Arguments:
indices (list, optional): a list of indices
num_samples (int, optional): number of samples to draw
"""
def __init__(self, dataset, indices=None, num_samples=None):
# if indices is not provided,
# all elements in the dataset will be considered
self.indices = list(range(len(dataset))) \
if indices is None else indices
# if num_samples is not provided,
# draw `len(indices)` samples in each iteration
self.num_samples = len(self.indices) \
if num_samples is None else num_samples
#FOR MULTICATEGORY
# # distribution of classes in the dataset
# label_to_count = {}
# for idx in self.indices:
# label = self._get_label(dataset, idx)
# for l in label:
# if l in label_to_count:
# label_to_count[l] += 1
# else: label_to_count[l]=1
# single category
# distribution of classes in the dataset
label_to_count = {}
for idx in self.indices:
label = self._get_label(dataset, idx)
if label in label_to_count:
label_to_count[label] += 1
else: label_to_count[label]=1
# label_to_count["Normal"] = label_to_count["Normal"] + int(.1*label_to_count["Normal"])
print(label_to_count)
# #Multicategory
# # weight for each sample
# weights = [1.0 / min([label_to_count[l] for l in self._get_label(dataset, idx)])
# for idx in self.indices]
weights = [1.0 / label_to_count[self._get_label(dataset, idx)] for idx in self.indices]
self.weights = torch.DoubleTensor(weights)
def _get_label(self, dataset, idx):
return dataset.y[idx].obj #for category obj
def __iter__(self):
return (self.indices[i] for i in torch.multinomial(
self.weights, self.num_samples, replacement=True))
def __len__(self):
return self.num_samples
src = (ImageList.from_df(df, path=path)
.split_from_df(col="valid")
.label_from_df("dog_breed")
.transform(tfms, size=224))
bs=24
sampler_train = ImbalancedDatasetSampler(src.train)
train_dl = DataLoader(src.train, bs, sampler=sampler_train, num_workers=16)
val_dl = DataLoader(src.valid, 2*bs, False, num_workers=16)
data = ImageDataBunch(train_dl=train_dl, valid_dl=val_dl)
I’m not sure how I would do something similar in the latest version of fastai. Any ideas?
I think it should be something similar because your sampler isn’t depending on fastAI src, we just need to figure out how to pass it to the V2 version now, right?
It’s worth thinking about imbalanced classes before going ahead and correcting it.
As far as I’m aware it’s not always an issue. In particular if the balance of classes in your test/production data is the same as the training data then I think that “correcting” class imbalance may actually be a bad thing. E.g. in your training AND production data Class 1 is 80% of the data and Class 2&3 are 10% each. Then if you balance this out artificially then surely your model is more inclined to predict the wrong class in a production scenario.
There’s a good chance I’m talking bollocks, but at least that’s my understanding of the situation, i.e. your model will become misaligned by balancing it out. If that’s not the case then I would quite like to be corrected
That’s sometimes true and sometimes not. In my specific example it doesn’t work. The network starts predicting everything as the most common class and stops learning.
This is an open question I have always had. When is it appropriate to balance an inherently unbalanced data set? Does this vary from case to case and should I just try out various options to see what works?
I would also like a concrete answer to this. Certainly if you think of it as a binary classification problem, e.g. predicting if somebody will pay a bill or not, then you want your model to be aligned to the ground-truth because you’ll be making business decisions off the back of it. However if you were predicting anomalies for instance, e.g. credit card fraud, then it’s probably beneficial to have a misaligned model because you probably don’t mind a few false positives providing it catches more of the actual fraud i.e. the balance between precision and recall. Remember with a binary outcome a model might be great at separating the classes, but not great at predicting the right probabilities.
I don’t know how this translates to things like image classification with multiple classes though. I suspect it’s the same though. E.g. if you have a pet classifier of dog, cat, hamster but you have loads of pictures of cats and a few of dogs but hardly any of hamsters. Intuitively I’d want to balance it to the ground truth probability e.g. if there’s a 0.2 probability of hamster and a 0.4 each of dog and cat then that’s how I’d balance my data though use of sample weights. But I just don’t know!
I guess one reason for balancing it when you don’t care about alignment might be that if you only have a small number of samples of a class in your training data then the gradients might be drowned out by the majority class. Just a guess. Equally though up-sampling could be a bad thing because your might just overfit if it keeps seeing the same data repeatedly.
You’re on the right track. The goal of over/under sampling is to give your minority classes (those that are underrepresented compared to the largest) more opportunities to be trained on per epoch. This allows your model to get more used to the class and trains on it more (even though it’s just the same data over and over for that class). It can have drawbacks (such as I’m over sampling 100 samples to match up with 1,000 samples) but you could also try a mixture of over/undersampling here as well for instance. Does this make more sense?
Let’s say I have Class A, which has 5,000 samples, and Class B with 2,500 samples. If we trained normally (split by rand pct, etc) we would assume that our validation data would get 1,000 samples of Class A, and 500 samples of Class B. This should not change really. If you know about the data, you can build a custom validation set that takes into account each class, but we’ll go with the prior assumption.
Now, how would oversampling work here? Let’s say I oversample my training data so Class A has the same amount of samples as Class B. I’ll be randomly sampling Class B until we have the 4,000 samples needed (so now my training dataset has 8,000 samples). What does that look like during training? We can now say the following:
Every one epoch we train on Class A for one complete iteration of it’s set, and Class B four iterations of its set during each epoch
Does this explain the idea a bit better? Essentially now we are training magnitudes more on the same data on our under-represented data, thus allowing the model to “get used to a underrepresented class” more. Let me know if it’s still not quite clear
I also have my own notebook discussing over/under/balance sampling too here, granted it’s fastaiv1 but if needed I can port it to v2
So, with the greatest respect because I appreciate your help here. What you’ve done in that notebook is not correct. For binary classification it’s not usually appropriate to use accuracy as a metric. Usually what you care about is discrimination i.e. how well can you separate the two classes. I’ve run the notebook using AUC and each of the models is almost identical - about 87.3. What you’ve done in each case is change the alignment of the model, and you’ve made it worse. The original was the most aligned. I’ll try and put an example together to demonstrate…
Perfectly okay with that (not the it’s wrong, the opportunity to learn and fix it)! I haven’t dived my head much into the best practices for binary classification, so I greatly appreciate this opportunity to learn
Yeah, it took a while for me to get my head round! I mostly used to work with binary classification and I had to have it drilled into my head multiple times before I understood why it matters
You should always oversample the less common class, never visa-versa. You can then post-process predictions or use a different threshold, to handle the change in frequency that results in.
Accuracy is an excellent metric to report for binary classification. You can do so under a few different thresholds, or find the best threshold. AUC is also useful, but is much harder to intuitively understand - understand-ability is one of the key factors you want in a metric.
Hah, hi @jeremy nice of you to get involved! I don’t agree though! I think accuracy is only good when you have balanced classes. Take for instance a model where 90% of the data belongs to one class. You could get a 90% accurate model by just predicting that everything is the same. Also, in the example notebook, there’s 3 models with apparently different accuracy, but I’ve tested it and all 3 have the same discrimination power, but they just have different levels of alignment.
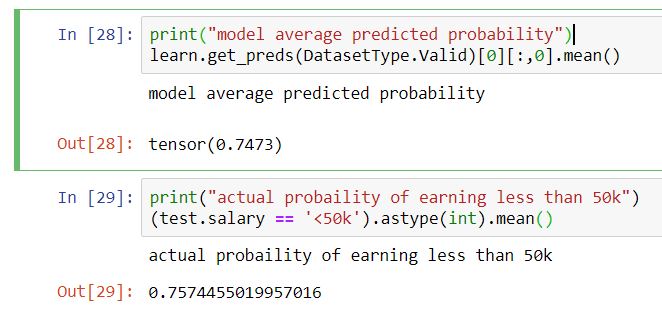
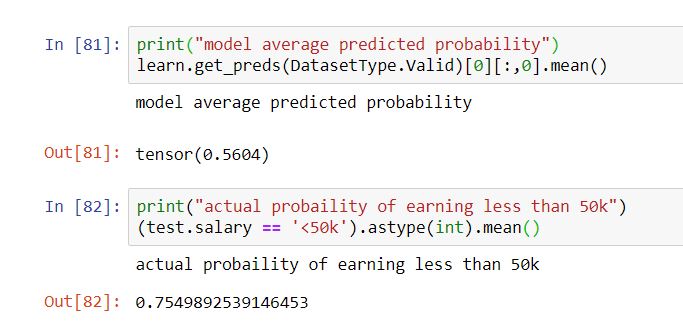
For my point on model alignment, let’s just say we we’re predicting probability of having cancer then you wouldn’t want your model to give you an average of 50% probability if you’ve balanced your data that way, when the actually probability was only 5%.
From the example notebook, take a look at the average predicted probability with no change of class balance, vs the one with under-sampling.
To me, this is where careful consideration of how to build a good validation set to look at is important. One that perhaps has equal amounts of both classes, and further examining the confusion matrix is extremely important. (Aka where good practice comes in)