Hi,
Main idea behind this AWS Cloud Formation template was to stay under free tier whenever is possible, but have ability to quickly provision and switch between frameworks, on-demand and spot instances without copying datasets and notebooks.
Also it allows to run several different types of instances simultaneously while sharing the same data and notebooks on Elastic File System.
When stack is deleted it reverts all resources in AWS account back, except EFS file system. That allows you to keep data and notebooks and attach it to any other instance, stack or docker containers.
Elastic File system is NFS like file system and it is more flexible from pricing perspective than EBS: you pay for amount of used space, rather than allocated space. And it grows and shrinks automatically.
There are two choices in the template:
ubuntuBootstrapAMI - uses Ubuntu 16.04 image and bootstraps it to full DL environment. At the end it launches Jupyter.
EBS root volume is 16Gb, and fast.ai notebooks are downloaded into /home/ubuntu/efs
Since bootstrapping uses modified version of install-gpu.sh script - it can run fast.ai notebooks out of the box.
awsDeepLearningAMI - uses Amazon Linux image with June version of AWS DL Image.
Both choices mounts the EFS under ~/efs path.
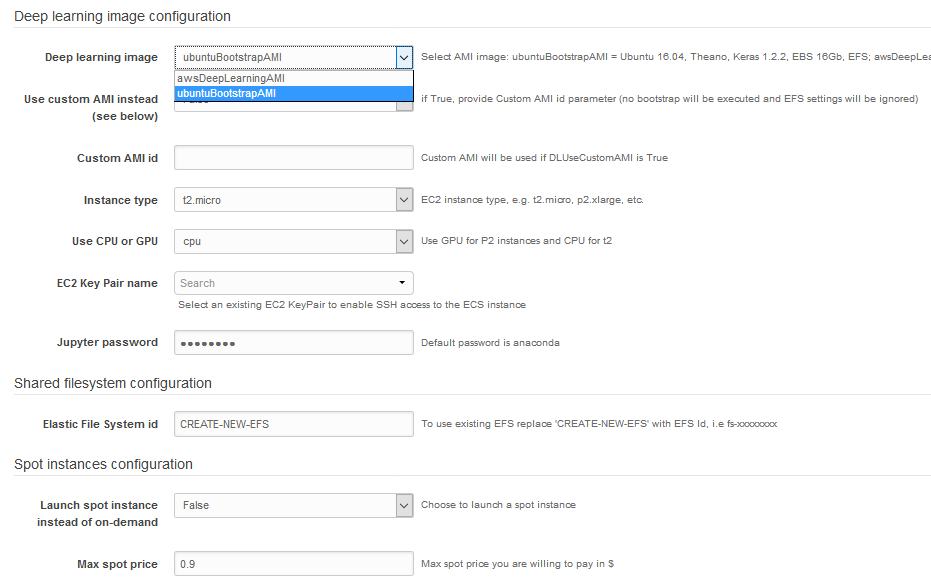
In order to create the stack you need at least one EC2 Key Pair.
To start: download cloud formation template deeplearning-sandbox-cfn.json
In AWS account go to Services -> CloudFormation and click Create a Stack

Then you need to browse and upload template deeplearning-sandbox-cfn.json:
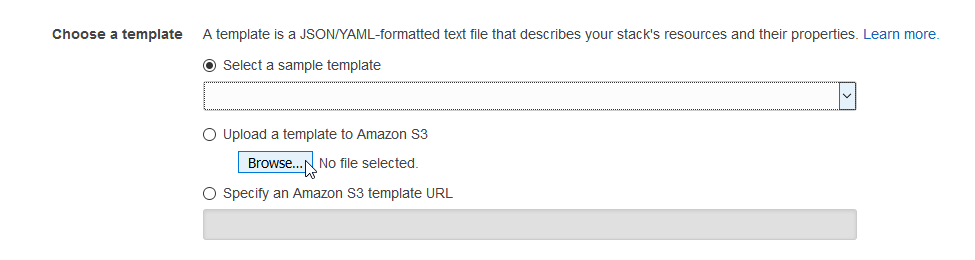
After filling in parameters and clicking though confirmation screens the creation will begin.
It takes approximately 26 minutes to bootstrap instance on t2.micro. After that you can stop and start instance through EC2 console or aws cli.
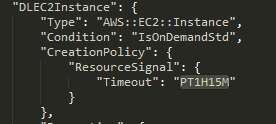
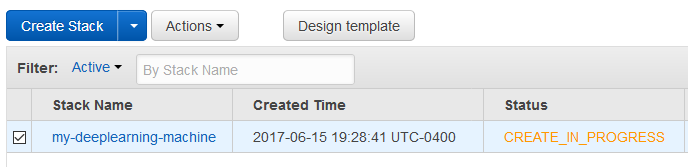
After creation and bootstrapping is completed you will see status: CREATE_COMPLETE.
Note that when using spot instances CREATE COMPLETE will appear earlier than bootstrapping is finished.
You can follow bootstrapping process by tailing /var/log/bootstrap.log
I would recommend to perform first initial creation using t2.micro and after you try to run notebooks - create an AMI from the bootstrapped instance, which later can be used as Custom AMI parameter to start spot and/or p2 instances.
If you chose to CREATE-NEW-EFS, you can manage your file system under Services - > EFS

P.S. Big thanks to @jeremy and @rachel for running fast.ai project!