- Apologies if this isn’t the correct channel for this but this to me a complete head-scratcher
- I’m attempting to build a radiology report classifier, I have 900 annotated reports which I’ve stratified by label and split 50/50 (train/validation). The classification task is whether the patient has micro-calcifications (think of it as a visual artefact present in the imaging data which is noted by the reporting clinician).
- I’ve trained two classifiers:
- an AWD-LSTM, without fine-tuning on the radiology reports i.e. only pretrained on the wikitext103 data and straight onto the classification step, as a baseline.
- fine-tuning a Radiology BERT model, which was trained on 4 million radiology reports here (HuggingFace)
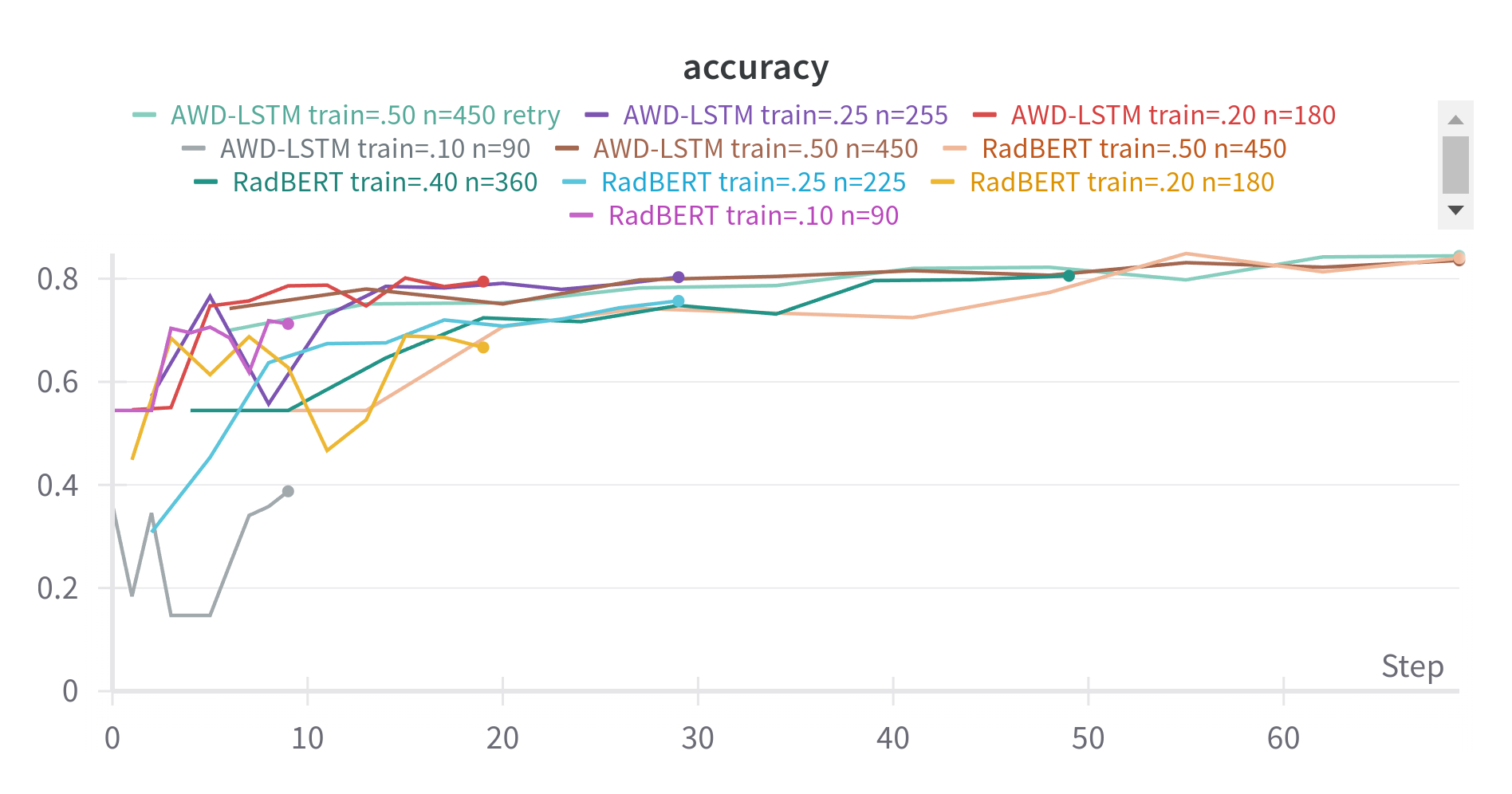
- Below are my results, how the hell are both models performing similarly?!
- I should note that I’ve adapted the tutorial from the fastai docs to use the HuggingFace transformer library alongside fastai. Perhaps I screwed up the code implementation, please see snippets below:
tokenizer = AutoTokenizer.from_pretrained(mn)
mdl = AutoModelForSequenceClassification.from_pretrained(mn, num_labels=3, id2label=id2label, label2id=label2id)
...
class DropOutput(Callback):
def after_pred(self): self.learn.pred = self.pred[0]
class TransformersTokenizer(Transform):
def __init__(self, tokenizer): self.tokenizer = tokenizer
def encodes(self, x):
toks = self.tokenizer.tokenize(x, max_length=512, truncation=True)
return tensor(self.tokenizer.convert_tokens_to_ids(toks))
def decodes(self, x): return TitledStr(self.tokenizer.decode(x.cpu().numpy()))
# reports are in a L(tuples) i.e. [('radiology report', 'label')]
tfms = [[ItemGetter(0),TransformersTokenizer(tokenizer)],[ItemGetter(1), Categorize()]]
cut = int(len(df_stratified.loc[df_stratified['is_valid'] == False]))
...
reports = L(
(df_stratified.to_records(index=False))
.tolist()
)
splits = [list(range(cut)), list(range(cut, len(reports)))]
dsets = Datasets(reports, tfms, splits=splits)
dls = dsets.dataloaders(dl_type=SortedDL, before_batch=pad_input)
learn = Learner(dls, mdl, loss_func=CrossEntropyLossFlat(), cbs=[DropOutput, WandbCallback(log_preds=False)], metrics=[accuracy, Perplexity()])
learn.fine_tune(4, 1e-4)
learn.fine_tune(4, 1e-4)
...
I’d be very grateful for any insight.