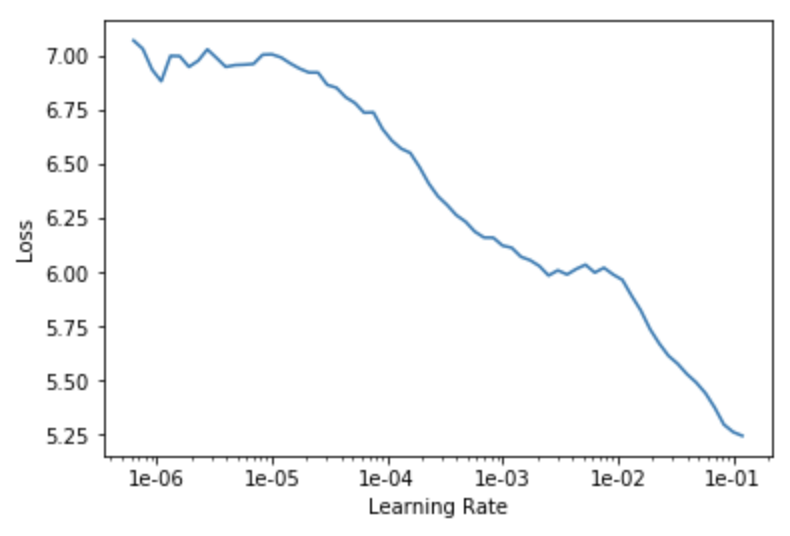
Currently in Fast.ai’s learning rate (LR) finder for its 1cycle learning policy, the best way to choose the learning rate for the next fitting is a bit of an art. Recommended methods include choosing the LR at the steepest decline of loss or 10x prior to the minimum loss. Like others, while I have found the LR finder very useful, I have had trouble automating the selection of a “good” learning rate. Fast.ai’s current suggestion in the LR finder, the point at which the gradient of the losses in respect to the LR is at its lowest, didn’t work well for me in some cases. When training classifiers on unstructured text, this approach hasn’t worked well as I unfreeze more layers.
However, I am looking to automate the training of dozens of models on different datasets, so this is a problem that needs to be solved. To address this, I came up with a method that automates the selection of a LR in Fast.ai, and so far it’s been working pretty well.
Here is the code:
def find_appropriate_lr(model:Learner, lr_diff:int = 15, loss_threshold:float = .05, adjust_value:float = 1, plot:bool = False) -> float:
#Run the Learning Rate Finder
model.lr_find()
#Get loss values and their corresponding gradients, and get lr values
losses = np.array(model.recorder.losses)
assert(lr_diff < len(losses))
loss_grad = np.gradient(losses)
lrs = model.recorder.lrs
#Search for index in gradients where loss is lowest before the loss spike
#Initialize right and left idx using the lr_diff as a spacing unit
#Set the local min lr as -1 to signify if threshold is too low
r_idx = -1
l_idx = r_idx - lr_diff
while (l_idx >= -len(losses)) and (abs(loss_grad[r_idx] - loss_grad[l_idx]) > loss_threshold):
local_min_lr = lrs[l_idx]
r_idx -= 1
l_idx -= 1
lr_to_use = local_min_lr * adjust_value
if plot:
# plots the gradients of the losses in respect to the learning rate change
plt.plot(loss_grad)
plt.plot(len(losses)+l_idx, loss_grad[l_idx],markersize=10,marker='o',color='red')
plt.ylabel("Loss")
plt.xlabel("Index of LRs")
plt.show()
plt.plot(np.log10(lrs), losses)
plt.ylabel("Loss")
plt.xlabel("Log 10 Transform of Learning Rate")
loss_coord = np.interp(np.log10(lr_to_use), np.log10(lrs), losses)
plt.plot(np.log10(lr_to_use), loss_coord, markersize=10,marker='o',color='red')
plt.show()
return lr_to_use
This function takes in your Learner model and parameters that can allow for tuning of the LR selection as needed. Taking advantage of the fact that the loss skyrockets at some point when the learning rate gets high enough, I used an “interval slide rule” technique that shifts right to left on a flatter loss gradient plot of the learning rate finder, progressing until the loss value of the right interval bound comes within a close-enough distance to the left interval bound. The left interval bound is then taken as the selected learning rate, with adjustment implementable as a multiplier argument.
The plots below provide some visualizations.
Parameters:
- lr_diff provides the interval distance by units of the “index of LR” (log transform of LRs) between the right and left bound
- loss_threshold is the maximum difference between the left and right bound’s loss values to stop the shift
- adjust_value is a coefficient to the final learning rate for pure manual adjustment
- plot is a boolean to show two plots, the LR finder’s gradient and LR finder plots as shown below
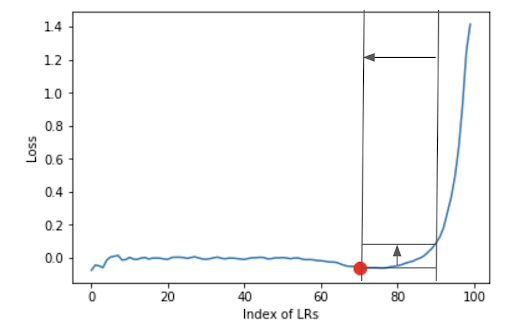
The plot below is the loss gradient plot showing the interval slide rule iterating along the LR curve from right to left until the difference in loss at the left and right bounds goes below the threshold and the interval slide rule hits the optimal LR, indicated by the red dot. This plot is output by the find_appropriate_lr() method if the plot parameter is set to true.
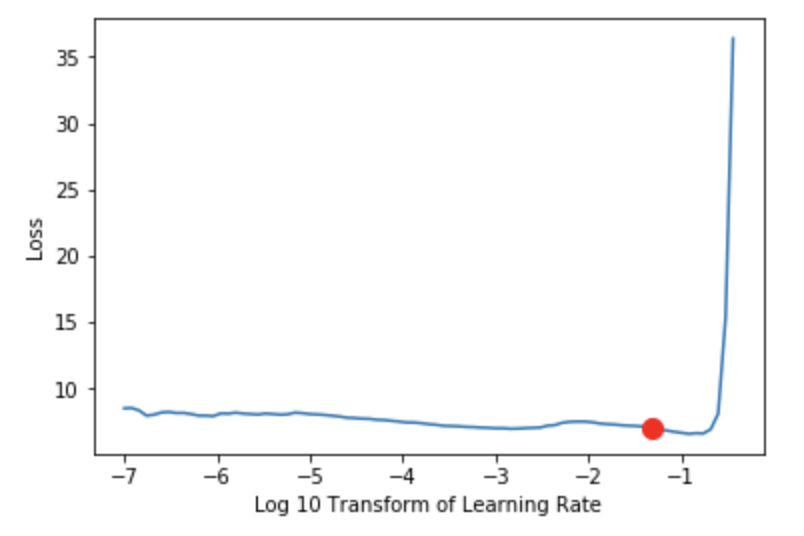
The plot below shows the same result from the Learner’s LR plot, with the new learning rate suggestion plotted as a red dot after it is adjusted (if the adjust_value parameter is anything other than 1).
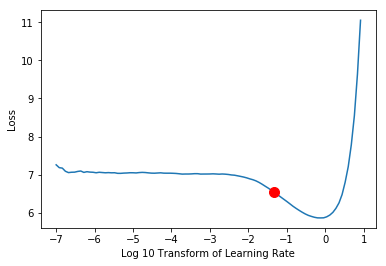
The plot below shows Fast.ai’s current learning rate finder graph obtained from the model/learner recorder object’s plot method. The red dot is Fast.ai’s built-in minimum numerical gradient value suggestion.
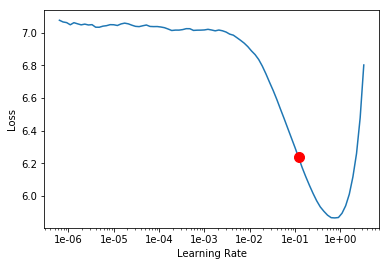
The current Fast.ai suggestion of the lowest gradient loss value generates a value of 0.12, whereas our interval slide rule method generates a more robust value, 0.0479. The interval slide rule technique generates a smaller LR value than Fast.ai’s suggestion and what I would normally use. This is done because I will be automating the training of many models, and I have opted to be a little conservative in my selection methodology.
While the interval slide rule method works well for training and fine-tuning text models, the next step is to look into its performance when training different types of text models, as well as image and tabular models on Fast.ai. I am curious to see what pitfalls will be encountered when trying to select the best learning rate across different training environments.
Feedback, improvements, and discussion on alternative methods are welcome!