@aychang - Just came across this thread and am wondering if the function posted back on April 20 is still the most current version?
Also, has this more automated learning rate finder been added to the fastai library?
@aychang - Just came across this thread and am wondering if the function posted back on April 20 is still the most current version?
Also, has this more automated learning rate finder been added to the fastai library?
This should work on the most current fastai version and recent feedback seems to show that it still works, but I want to double check and run some tests to make sure nothing has gone awry since April.
This has not been added to the fastai library. @sgugger would you deem this method of finding a suggested lr okay enough to replace/add with the current min-loss-gradient*10-1 suggester? I went through the contributing.md specifics and could submit a PR that I’ve tested in editable mode. It would be pretty non-invasive, just a value suggested and set as the object attribute resulting from the bool parameter in {learner_name}.recorder.plot(). Any input is much appreciated as well
There is alread a suggested value when you pass along suggestion=True to learn.recorder.plot.
While I do agree there, I’ve noticed you need to narrow down your window pretty well else it won’t grab a decent learning rate.
I didn’t say it was good. There are no real good options to automatically pick a learning rate IMO apart from looking at the curve, which is why the flag is False by default.
Yes I was thinking in addition to the current suggester, I can add the automated LR suggester from this post which would also be flagged as False by default. It would essentially “narrow down” the window with the sliding interval technique and only involve a few lines of code. I feel like it should be a good enough option for those who are running many experiments for empirical results, and again it would be tagged as False by default along with the currently implemented suggested value we mentioned in learner.recorder.plot.
Hi @aychang
could you please answer this two questions :
by lr_finder
when we are at the bottom of loss curve of val_set , we find biggest Lr that times by slope of the point (some where at the bottom)does not over_shoot us
like this link {https://www.google.com/imgres?imgurl=https%3A%2F%2Fwingshore.files.wordpress.com%2F2014%2F11%2Falpha3.png%3Fw%3D662&imgrefurl=https%3A%2F%2Fwingshore.wordpress.com%2F2014%2F11%2F19%2Flinear-regression-in-one-variable-gradient-descent-contd%2F&docid=xAjpT4vjhawiCM&tbnid=ehi30eMGO0YUiM%3A&vet=10ahUKEwiyqNvkpOTkAhV15eAKHYxQBvsQMwhTKAcwBw..i&w=577&h=415&bih=754&biw=1536&q=overshooting%20by%20high%20learning%20rate&ved=0ahUKEwiyqNvkpOTkAhV15eAKHYxQBvsQMwhTKAcwBw&iact=mrc&uact=8}
but , after finding lr , when we are gonna use fit function
we can be over_shooted , because we have bigger slope , this time , because we are not at the bottom
and another question is
in using that Lr for SGD with restart
for each restart , how is it posible to be shooted in another non_spiky valley ?
in picking Lr in Lr_finder, we were sopoused to choose the biggest lr which can not over_shoot us
after using the learning rate suggester after a while, it works very well, although …
sometimes I get an error that says :
local variable ‘local_min_lr’ referenced before assignment
Does anyone know what that means?
Apologies for the tardiness of my reply! It’s been a crazy past month on my end, and I wish I could have replied sooner. Hopefully things have been sorted out…
@MahdiRezaei
For your first question if I understand correctly, the suggester is giving you too high of a learning rate value so it’s “overshooting” any local/global loss minima. There are a couple of ways to avoid this issue with the learning rate suggester: one method being to increase your lr_diff parameter which increases the slide interval, another method is to outright decrease the proposed LR by decreasing the adjust_value param approaching zero (I’d start with 0.5->0.01->0.05). These all ultimately decrease the LR value to prevent the “over-shooting” you are concerned with.
For your second question, the suggester may need a little tuning with the lr_diff param depending on dataset size and the model architecture you are using. However, once that’s done it usually seems to generalize across each fitting whether you’re fine-tuning or training a classifier and ideally provide you with that biggest LR without overshooting any loss minima. Anything further than that would require at least some empirical analysis when training.
@LuisAnayaTan
Hmm it seems like the while loop invariants in the suggester seem to be breaking. I assume it’s because the initial condition of (abs(loss_grad[r_idx] - loss_grad[l_idx]) > loss_threshold) is false which is curious behavior. It seems like the loss/LR values are not being correctly outputted by the learner’s recorder.losses calls. I hope this helps and feel free to post additional info that I could help out with (hopefully this time in a more timely manner on my part haha)
Hi all,
Here at Esri, we’ve been using fast.ai to develop a library to train geospatial deep learning models.
We performed a few experiments and found that picking a learning rate about midway or 2/3rd of the way in the section of the loss curve where loss is going down worked best for us.
Here’s the code we used, in case others want to try it out:
def find_lr(losses, lrs):
import matplotlib.pyplot as plt
losses_skipped = 5
trailing_losses_skipped = 5
losses = losses[losses_skipped:-trailing_losses_skipped]
lrs = lrs[losses_skipped:-trailing_losses_skipped]
n = len(losses)
max_start = 0
max_end = 0
# finding the longest valley.
lds = [1] * n
for i in range(1, n):
for j in range(0, i):
if losses[i] < losses[j] and lds[i] < lds[j] + 1:
lds[i] = lds[j] + 1
if lds[max_end] < lds[i]:
max_end = i
max_start = max_end - lds[max_end]
sections = (max_end - max_start) / 3
final_index = max_start + int(sections) + int(sections/2) # pick something midway, or 2/3rd of the way to be more aggressive
fig, ax = plt.subplots(1, 1)
ax.plot(
lrs,
losses
)
ax.set_ylabel("Loss")
ax.set_xlabel("Learning Rate")
ax.set_xscale('log')
ax.xaxis.set_major_formatter(plt.FormatStrFormatter('%.0e'))
ax.plot(
lrs[final_index],
losses[final_index],
markersize=10,
marker='o',
color='red'
)
plt.show()
return lrs[final_index]
Let us know if you’d like to see this is in a PR.
Hello,
I have been following and thread and found this youtube video for trying to find the best learning rate: https://www.youtube.com/watch?v=q8G8Tfgyr2I&list=WL&index=107&t=0s
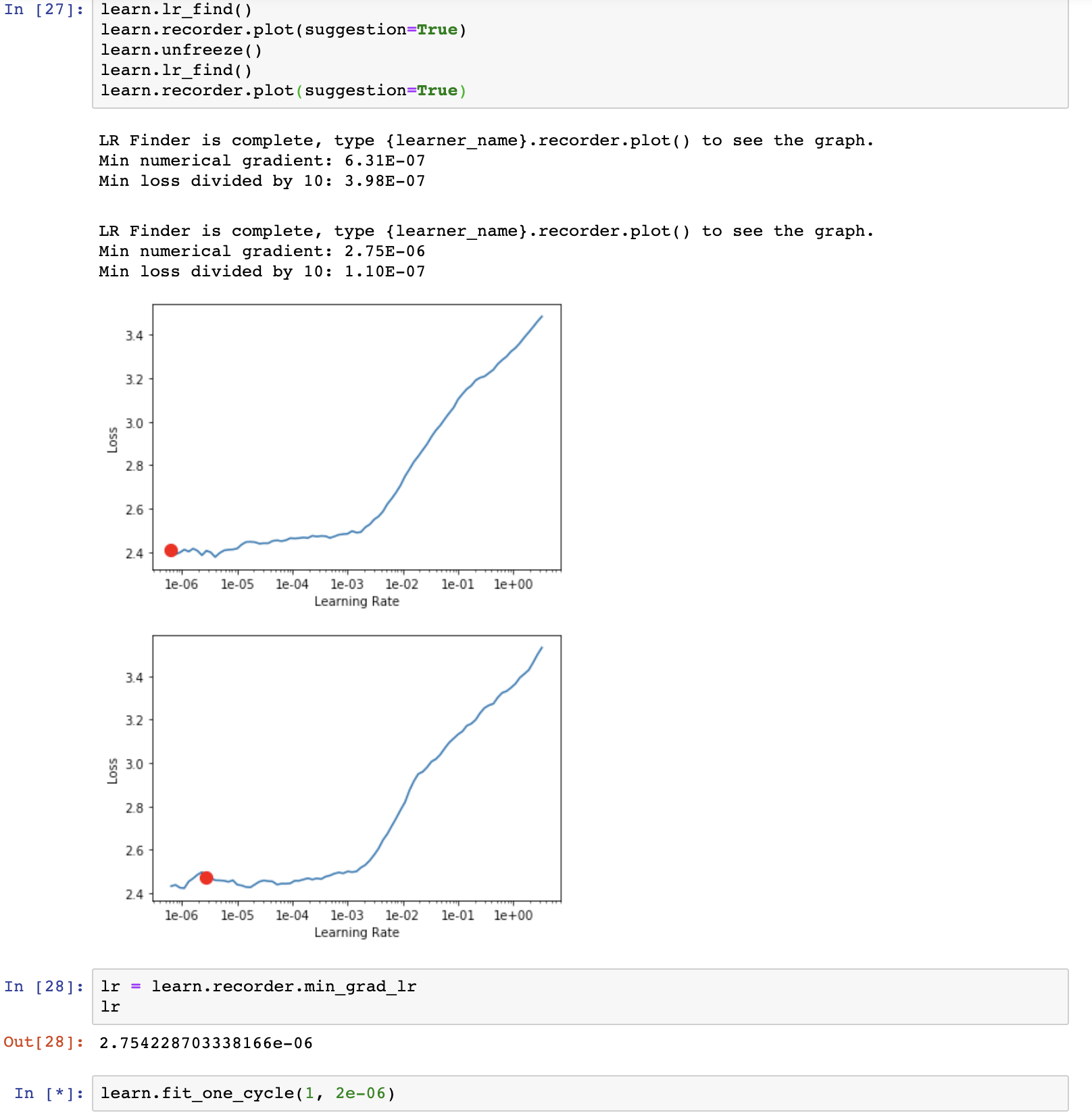
I am trying to understand the different between the plots of the value of learn.recorder.min_grad_lr. Can anyone help me with understanding the lr rage from output lr_find()?
Min numerical gradient: 2.75E-06
Min loss divided by 10: 1.10E-07
What would be a suitable learning rate here? My understanding is that I should use 1e-06 or 2e-06 here.
Thanks
The recommended red dot only shows you the point at which you have the lowest gradient from loss and learning rate values, so it is not the most reliable learning rate to use at all times. Typically you want to use the learning rate that is large enough to optimally converge but small enough to not produce undesirable divergent behavior.
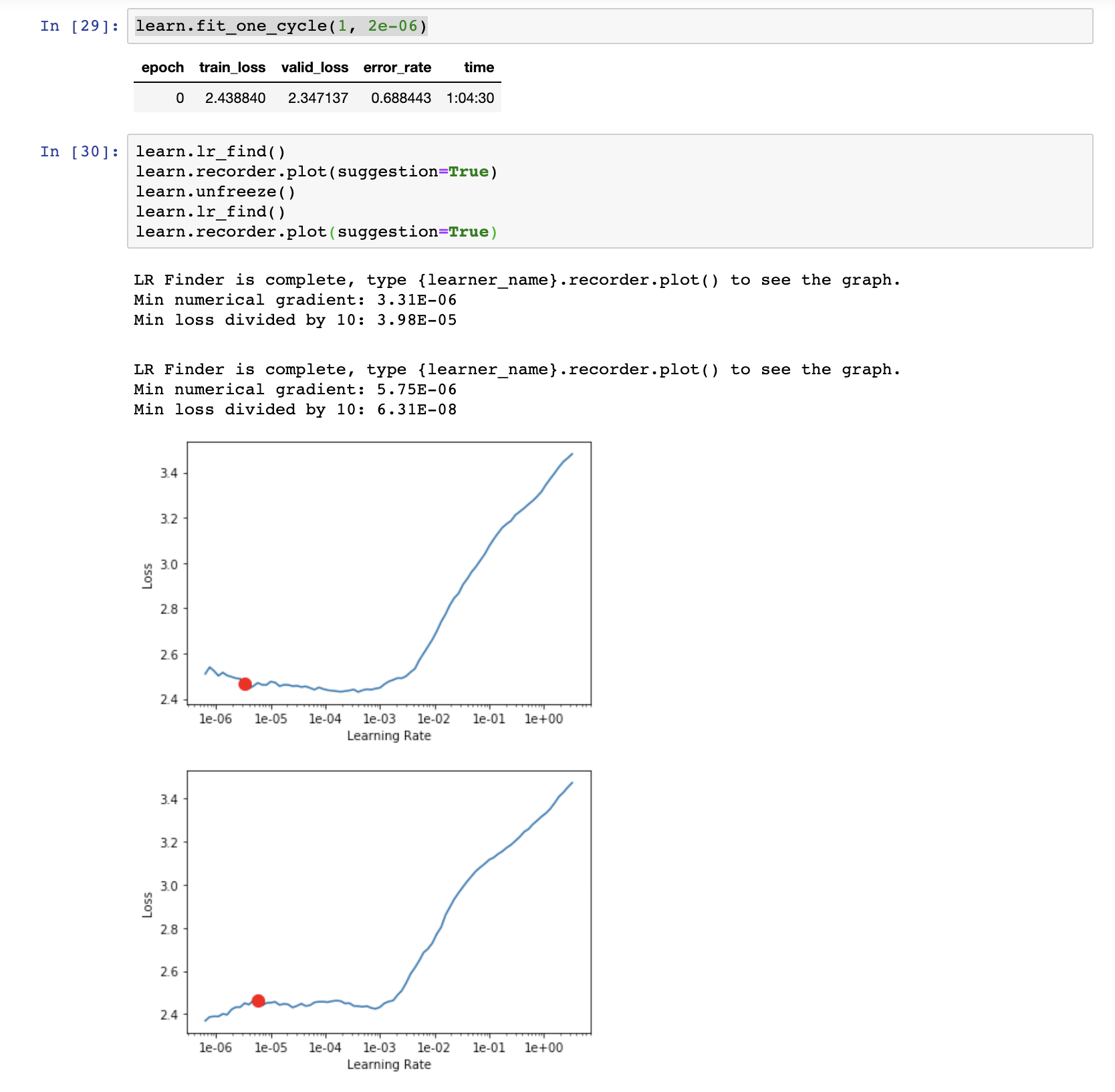
For the last two plots above, I would choose a LR of 8e-04 and 1e-03 respectively. Those points are where loss decreases more slowly…and right before loss shoots up.
If you want you could also try the find_appropriate_lr() method outlined in above in the initial post of this thread which should automate this process and hopefully give you and okay result!
Time to revive an old thread 
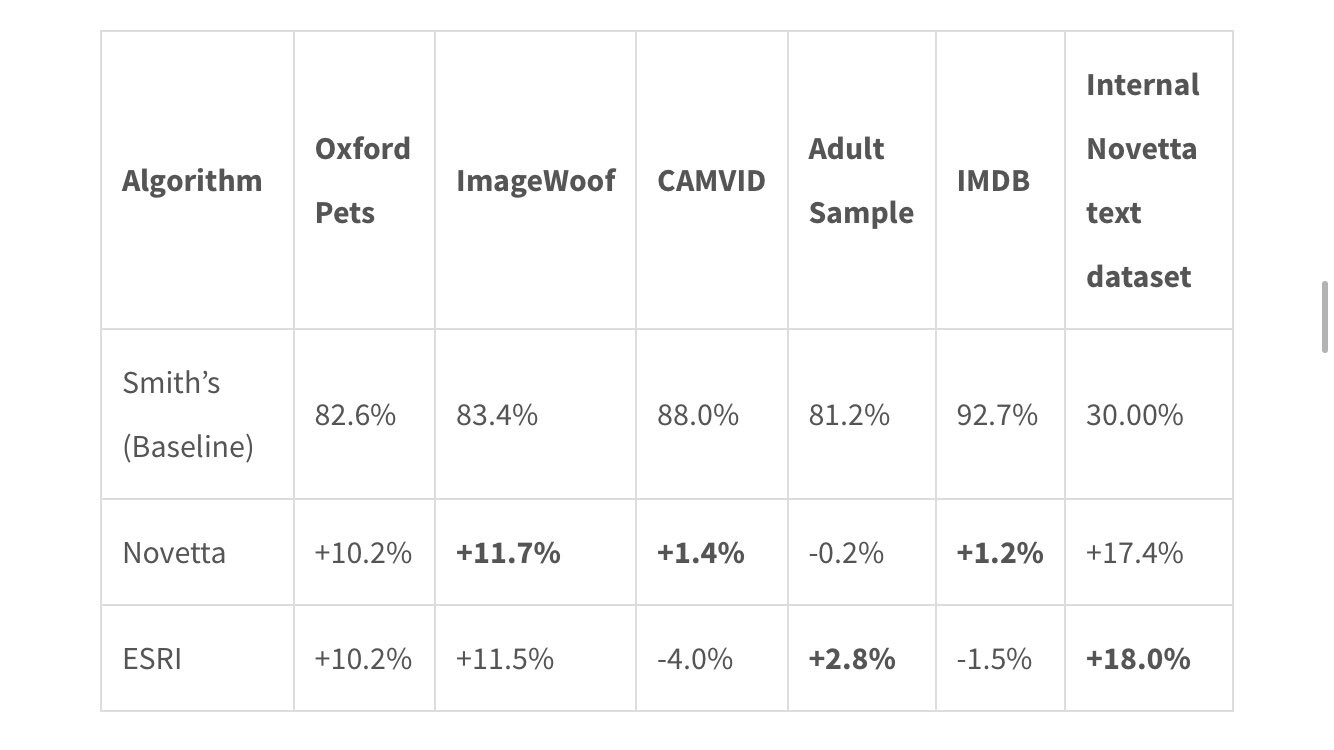
I recently did some work along with Andrew on just figuring out who’s algorithm is the best? The answer: both, depending on the problem.
Andrew’s suggester works great when calling a single .fit or fine_tune, but if you want to search for learning rates multiple times (such as fit, unfreeze, lr_find, fit), then @rohitgeo’s algorithm is the way to go. Below you can see our results and the exact article is linked below. Soon I’ll be doing a PR to fastai to include both suggestors, and you can pick and choose which to use
(Sneak preview):
Link to our article: https://www.novetta.com/2021/03/learning-rate/
Hi,
How did this ended up? I’m using fastai2 and don’t see the red dot when doing lr_find(suggestion=True). I only see a print like
SuggestedLRs(lr_min=0.03630780577659607, lr_steep=0.0691830962896347)
which I guess are two of the methods explained above. How can I access to those programatically? I would like to automate this
Thanks!
The PR has not been made yet, these last few months have been quite busy with school, I’m aiming for beginning of May to finalize and submit the PR
Thanks for your quick answer. Is there any way to get lr_steep after doing learner.lr_find() ?
ok, this was trivial, but for some reason didn’t think about it 
simply
lr_suggestion = learner.lr_find()
lr_suggestion.lr_steep
@marc.torsoc (and anyone else interested), I have a mockup gist of roughly what my PR will look like, and you can play with it:
Thanks! I’m working on something else right now, but will let you know when I use it
Sorry for taking so long to answer. This works great, thank you so much @muellerzr
{kind=link}