I understand how to train an autoencoder with data that is only continuous, but what do you do if you have categorical variables mixed with continuous variables in your input data. For continuous data, you simply have to have MSE loss to compare how close each of your variables are from the input variables. But for categorical variables, do you have to use cross-entropy for each of the categorical variables and somehow blend the losses for the continuous and categorical variables?
I have a similar problem where I am trying to combine text and categorical variables. For categorical variables I believe you can use swap noise as a way of adding noise to the input and augmenting the data. The loss used is the reconstruction loss so the network learns how to reconstruct the input from the noise.
This has been bugging me as well for a long time. In the end I’m just using MSE for both categorical and continuous variables. This might be completely wrong though.
I have been working on a notebook I want to share eventually, but basically I reconstruct all categorical variables by using cross entropy on all of them. This is the loss function I used:
def loss(preds, cat_targs, cont_targs):
cats,conts = preds
CE = cats.new([0])
pos=0
for i, (k,v) in enumerate(total_cats.items()):
CE += F.cross_entropy(cats[:, pos:pos+v], cat_targs[:, i], reduction='sum')
pos += v
norm_cats = cats.new([len(total_cats.keys())])
norm_conts = conts.new([conts.size(1)])
total = (F.mse_loss(conts, cont_targs, reduction='sum')/norm_conts) + (CE/norm_cats)
return total / cats.size(0)
The variable total_cats here is a dictionary of all categorical variables and how much unique element they have. In my model, for each categorical variable, I have a linear layer outputing the # of unique values for this categorical variable. So if a categorial variable has 3 possible values, I output 3 numbers. F.cross_entropy then apply the log_softmax to that to basically decide which category value to predict.
So the variable CE here accumulate the cross-entropy for all categorical variables (sum). Then normalize that by the number of categorical variables to predict. Same thing for the MSE loss for the continuous variables.
So far this seems to be working very well. When evaluating I check the accuracy of all categorical using the reconstructed values compared to the target. And I calculate the R2 for all continuous variables. It seems to be reconstructing the input quite well.
But my notebook is a mess and I am using a private dataset so I need to clean it up and use a public dataset before sharing.
For anyone interested I published on github a notebook where I do an autoencoder for tabular data and I reconstruct categorical data using crossentropy. Thanks a lot for @muellerzr for cleaning up the notebook further since I gave him permission to adapt it for a Walk with fastai post that should be really interesting!
Wow @muellerzr@etremblay this looks super impressive! I’d love to try and understand how you implemented the swap noise and reconstruction loss. I’m trying to build a denoising autoencoder across text and categorical data for my use case. I’ve built most of it out in Pytorch with Pytorch lightning but would be keen to compare notes and implementations.
For the categorical outputs, I’m simply taking the average of the cross entropy loss across the different categorical fields and the network seems to be learning how to reconstruct the noised input.
How did you settle on the 1024 nodes and the 128-dimension hidden representation for the encoder?
@etremblay can better comment on the first parts, but 128 just seemed to do the job enough. I tried 64 and that wasn’t doing the trick and 256 was much too large to me given the task. 1024 was because it seemed like a big enough initial representation No real magic on my end when playing with it
For the 1024 nodes and 128 dimension hidden representation I just tried things until it seemed to work ok. Your mileage may vary. Those are hyper parameters you can probably play with for your own datasets.
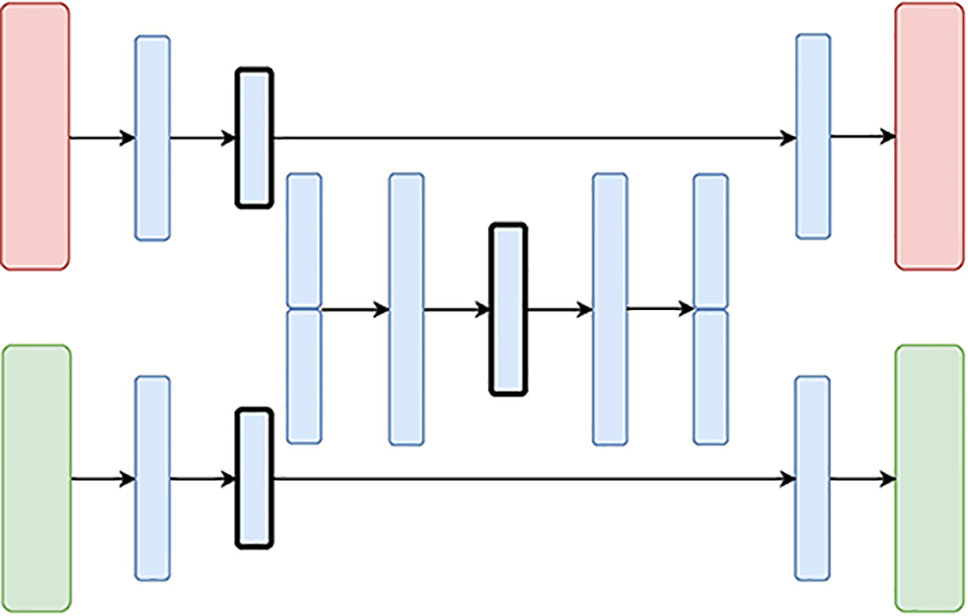
If you are doing an auto-encoder for multiple kind of data sources (tabular with text) I would explore hierarchical auto-encoders because what can happen is that one type of data dominate completely your representational space. I recently listened to this video where the go into more details about it: https://www.youtube.com/watch?v=HLZ36ZJ9GmQ
Basically what they propose is having two auto encoder path, one for each of your data type (for example the top path would be tabular, the bottom path could be text).
The top and bottom paths could be normal auto-encoders trying to reconstruct their input. But then you have a separate autoencoder in the middle where you concatenate the hidden representation from both auto-encoder, then make it pass into a separate auto-encoder network that tries to reconstruct the concatenated representation. This seems to be working well to balance two types of data sources in one hidden representation.
Thanks for sharing the paper. It looks like they tried out a few different architectures for combining between input data of different modalities. I read they used Binary Cross Entropy Loss as the loss function over the categorical data while you guys use Categorical Cross Entropy.
In your implementation are you using a separate output layer for each categorical field, or are you using a single layer with the outputs for the different categorical fields concatenated?
Also, in your implementation you are applying dropout alongside noising the input? Do the two work together to improve performance or do they cancel each other out.
And whats the reasoning behind performing a BatchNorm operation at each layer in the autoencoder?
I’m fairly inexperienced with autoencoders so your insights would be super helpful.
I am far from an expert myself, but I enjoy reading about auto-encoders!
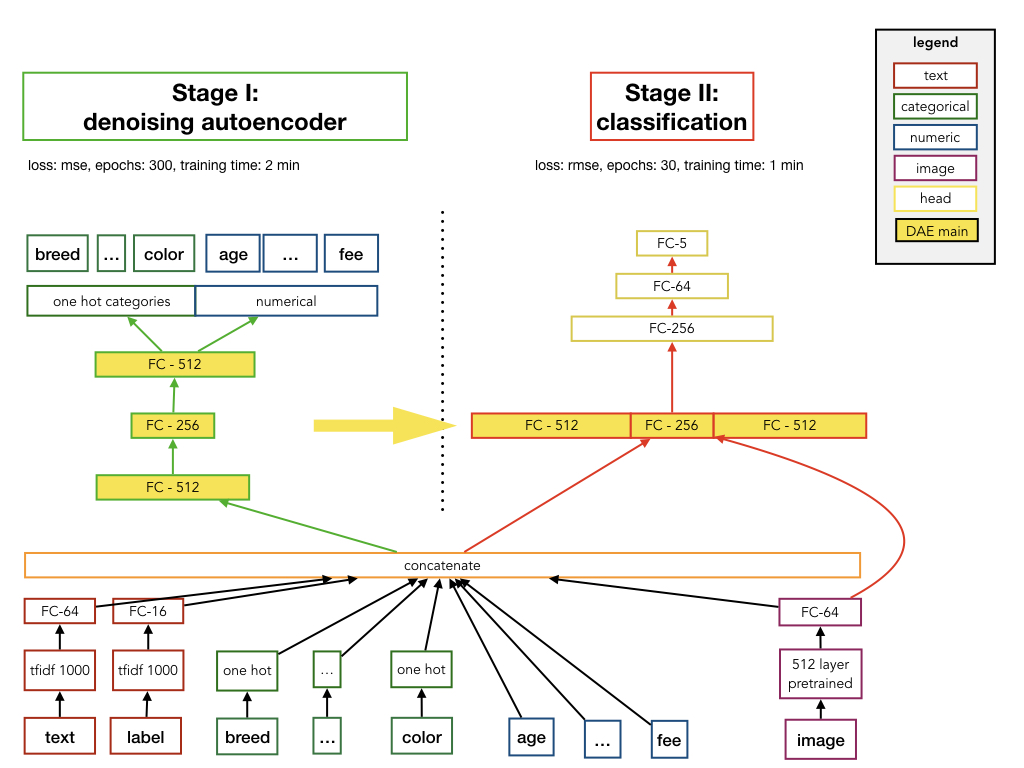
We used categorial cross-entropy because we made the code reusable in the context of any dataset. We don’t know in advance the # of distinct values each categorical variable is going to have depending on your dataset, so categorical cross-entropy is safer. When you only have two possible values for your categorical variable it basically becomes binary cross-entropy.
In the model for the categorical variables, we generate one big output vector of the size of the sum of all distinct values for each categorical variables. So if column Cat1 has 10 possible values, Cat2 has 2 possible values, we would output a vector of size 12. Then in the loss, we loop through this vector and apply cross-entropy in subset of it. So for output[:, 0:10] apply cross-entropy for Cat1, for output[:, 10:] apply cross-entropy for Cat2 etc.
From what I have read elsewhere, having dropout in the encoder seems to make the performance worse for the encoded vector… But having dropout in the decoder seems to be fine.
BatchNorm is there only to prevent the network from having super huge activations (which could happen without BatchNorm), keeping the network well behaved basically, speeding up training.