Trying to apply what i learned in tabular data lesson for American Express - Default Prediction kaggle competition.
to = TabularPandas(df, procs, cat, cont, y_names=dep_var, splits=splits,reduce_memory=True)
returns this error
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
/tmp/ipykernel_222/4108166279.py in <module>
----> 1 to = TabularPandas(df, procs, cat, cont, y_names=dep_var, splits=splits,reduce_memory=True)
/opt/conda/lib/python3.7/site-packages/fastai/tabular/core.py in __init__(self, df, procs, cat_names, cont_names, y_names, y_block, splits, do_setup, device, inplace, reduce_memory)
164 self.cat_names,self.cont_names,self.procs = L(cat_names),L(cont_names),Pipeline(procs)
165 self.split = len(df) if splits is None else len(splits[0])
--> 166 if do_setup: self.setup()
167
168 def new(self, df, inplace=False):
/opt/conda/lib/python3.7/site-packages/fastai/tabular/core.py in setup(self)
175 def decode_row(self, row): return self.new(pd.DataFrame(row).T).decode().items.iloc[0]
176 def show(self, max_n=10, **kwargs): display_df(self.new(self.all_cols[:max_n]).decode().items)
--> 177 def setup(self): self.procs.setup(self)
178 def process(self): self.procs(self)
179 def loc(self): return self.items.loc
/opt/conda/lib/python3.7/site-packages/fastcore/transform.py in setup(self, items, train_setup)
190 tfms = self.fs[:]
191 self.fs.clear()
--> 192 for t in tfms: self.add(t,items, train_setup)
193
194 def add(self,ts, items=None, train_setup=False):
/opt/conda/lib/python3.7/site-packages/fastcore/transform.py in add(self, ts, items, train_setup)
194 def add(self,ts, items=None, train_setup=False):
195 if not is_listy(ts): ts=[ts]
--> 196 for t in ts: t.setup(items, train_setup)
197 self.fs+=ts
198 self.fs = self.fs.sorted(key='order')
/opt/conda/lib/python3.7/site-packages/fastai/tabular/core.py in setup(self, items, train_setup)
222 super().setup(getattr(items,'train',items), train_setup=False)
223 # Procs are called as soon as data is available
--> 224 return self(items.items if isinstance(items,Datasets) else items)
225
226 @property
/opt/conda/lib/python3.7/site-packages/fastcore/transform.py in __call__(self, x, **kwargs)
71 @property
72 def name(self): return getattr(self, '_name', _get_name(self))
---> 73 def __call__(self, x, **kwargs): return self._call('encodes', x, **kwargs)
74 def decode (self, x, **kwargs): return self._call('decodes', x, **kwargs)
75 def __repr__(self): return f'{self.name}:\nencodes: {self.encodes}decodes: {self.decodes}'
/opt/conda/lib/python3.7/site-packages/fastcore/transform.py in _call(self, fn, x, split_idx, **kwargs)
97 "A `Transform` that modifies in-place and just returns whatever it's passed"
98 def _call(self, fn, x, split_idx=None, **kwargs):
---> 99 super()._call(fn,x,split_idx,**kwargs)
100 return x
101
/opt/conda/lib/python3.7/site-packages/fastcore/transform.py in _call(self, fn, x, split_idx, **kwargs)
81 def _call(self, fn, x, split_idx=None, **kwargs):
82 if split_idx!=self.split_idx and self.split_idx is not None: return x
---> 83 return self._do_call(getattr(self, fn), x, **kwargs)
84
85 def _do_call(self, f, x, **kwargs):
/opt/conda/lib/python3.7/site-packages/fastcore/transform.py in _do_call(self, f, x, **kwargs)
87 if f is None: return x
88 ret = f.returns(x) if hasattr(f,'returns') else None
---> 89 return retain_type(f(x, **kwargs), x, ret)
90 res = tuple(self._do_call(f, x_, **kwargs) for x_ in x)
91 return retain_type(res, x)
/opt/conda/lib/python3.7/site-packages/fastcore/dispatch.py in __call__(self, *args, **kwargs)
121 elif self.inst is not None: f = MethodType(f, self.inst)
122 elif self.owner is not None: f = MethodType(f, self.owner)
--> 123 return f(*args, **kwargs)
124
125 def __get__(self, inst, owner):
/opt/conda/lib/python3.7/site-packages/fastai/tabular/core.py in encodes(self, to)
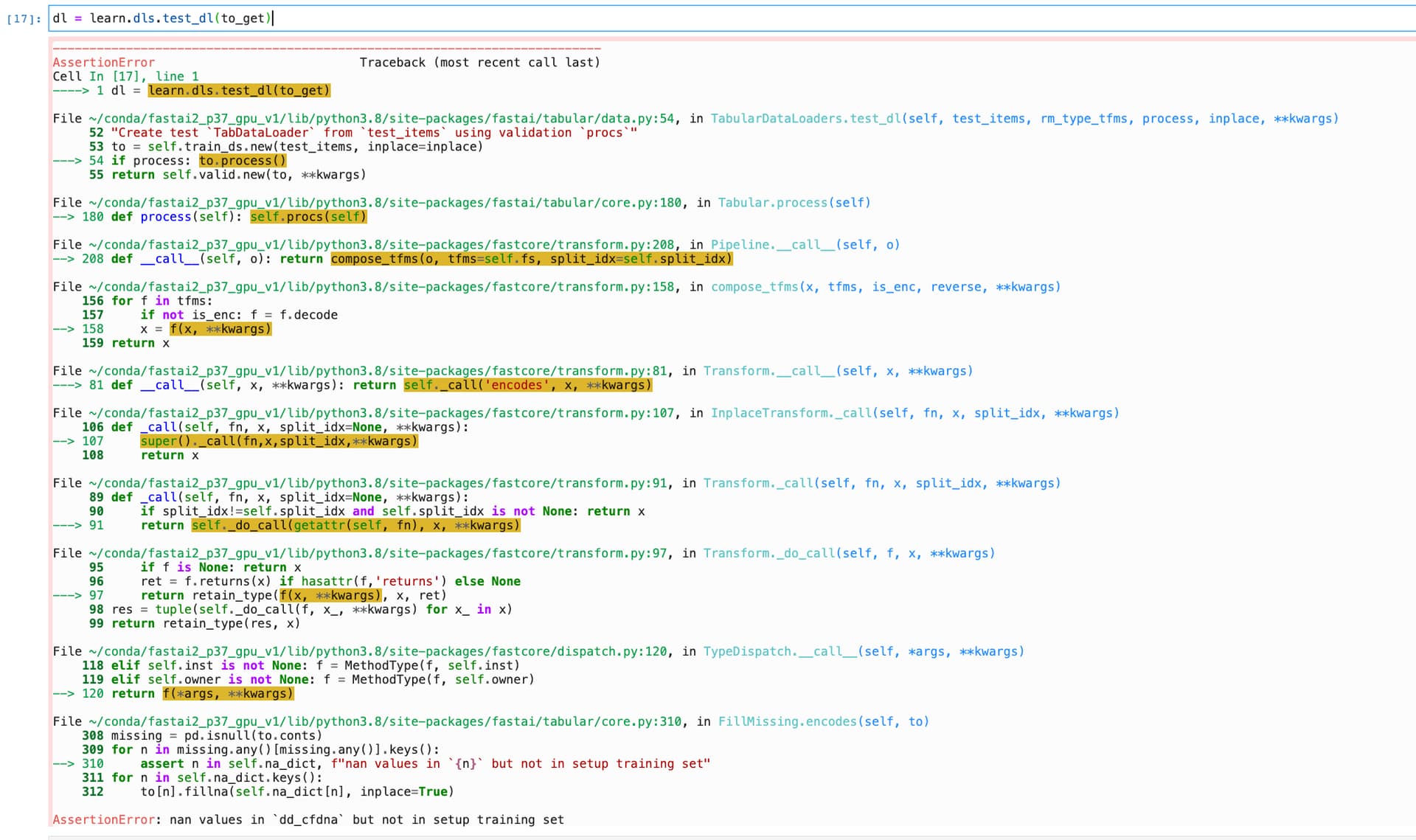
306 missing = pd.isnull(to.conts)
307 for n in missing.any()[missing.any()].keys():
--> 308 assert n in self.na_dict, f"nan values in `{n}` but not in setup training set"
309 for n in self.na_dict.keys():
310 to[n].fillna(self.na_dict[n], inplace=True)
AssertionError: nan values in `P_2` but not in setup training set
I believe i have accounted for nan values here.
# Making use of the GPU library. This only works for integer only features at present.
def read_file_int(path = '', usecols = None):
# LOAD DATAFRAME
if usecols is not None: df = cudf.read_feather(path, columns=usecols)
else: df = cudf.read_feather(path)
# REDUCE DTYPE FOR CUSTOMER AND DATE
# df['customer_ID'] = df['customer_ID'].str[-16:].str.hex_to_int().astype('int64')
df.S_2 = cudf.to_datetime(df.S_2)
# CREATE OVERALL ROW MISS VALUE
features = [x for x in df.columns.values if x not in ['customer_ID', 'target']]
df['n_missing'] = df[features].isna().sum(axis=1)
# FILL NAN
df = df.fillna(NAN_VALUE)
# KEEP ONLY FINAL CUSTOMER ID UNTIL FUTURE TIME SERIES WORK BEGINS
df_out = df.groupby(['customer_ID']).tail(1).reset_index(drop=True)
print('shape of data:', df_out.shape)
del df
return df_out
# To ensure that the categorical features are imported only using CPU
def read_file_cpu(path = '', usecols = None):
# LOAD DATAFRAME
if usecols is not None: df = pd.read_feather(path, columns=usecols)
else: df = pd.read_feather(path)
# REDUCE DTYPE FOR CUSTOMER AND DATE
# df['customer_ID'] = df['customer_ID'].str[-16:].str.hex_to_int().astype('int64')
df.S_2 = pd.to_datetime(df.S_2)
# CREATE OVERALL ROW MISS VALUE
#features = [x for x in df.columns.values if x not in ['customer_ID', 'target']]
#df['n_missing'] = df[features].isna().sum(axis=1)
# FILL NAN
#features_num = [x for x in df._get_numeric_data().columns.values if x not in ['customer_ID', 'target']]
#df = df[features_num].fillna(NAN_VALUE)
# KEEP ONLY FINAL CUSTOMER ID UNTIL FUTURE TIME SERIES WORK BEGINS
df_out = df.groupby(['customer_ID']).tail(1).reset_index(drop=True)
print('shape of data:', df_out.shape)
del df
return df_out
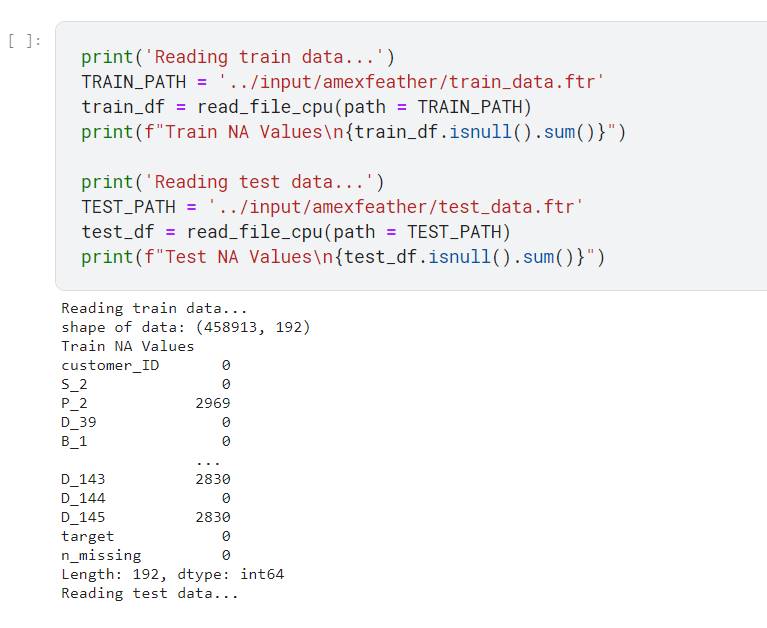
print('Reading train data...')
TRAIN_PATH = '../input/amexfeather/train_data.ftr'
train_df = read_file_cpu(path = TRAIN_PATH)
print('Reading test data...')
TEST_PATH = '../input/amexfeather/test_data.ftr'
test_df = read_file_cpu(path = TEST_PATH)