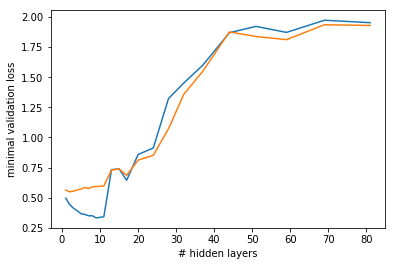
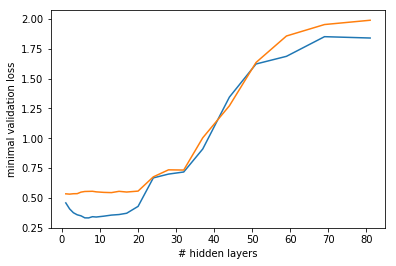
Applying LSUV
In the most recent lesson of the course (11), in a perfect timing for our progress here, Jeremy introduced his version of LSUV implementation. I guess he also decided to skip the orthonormal thing…
His function is the following:
def lsuv_module(m, xb):
h = Hook(m, append_stat)
while mdl(xb) is not None and abs(h.mean) > 1e-3: m.bias -= h.mean
while mdl(xb) is not None and abs(h.std-1) > 1e-3: m.weight.data /= h.std
h.remove()
return h.mean,h.std
Some preliminary remarks about LSUV:
- At first I didn’t understand why the iteration is necessary - by definition, anything you divide by its own STD will have an STD=1 after that division. But the reason for the iteration here is that we want the std=1 to apply to activations after the nonlinearity layer. The nonlinearity causes the mean and std to become less predictable and an easy solution here (which i’m not sure is guaranteed to work every time) is to iterate until we are close to what we want.
- Jeremy’s code iterates on the first level modules in the model. Our model is currently flat: all the layers, non-linearities, etc. are on the same level. Since, as I wrote above, we are interested in normalizing the activation only after the nonlinearity, (and also to keep our business working with the lesson’s code) I have to aggregate the layers in the model to [Linear, ReLU]. Each pair will then be initialized as one module, resulting in normalizing the activations only after the non linearity.
I made my adaptation of Jeremy’s code, so it will apply the LSUV to our deep FC network. It included importing the data as before, into notebook 7. I also made the following additions/replacements:
class FCLayer(nn.Module):
def __init__(self, ni, no, sub=0.0, **kwargs):
super().__init__()
self.linear = nn.Linear(ni, no)
self.relu = GeneralRelu(sub=sub, **kwargs)
def forward(self, x): return self.relu(self.linear(x))
@property
def bias(self): return -self.relu.sub
@bias.setter
def bias(self,v): self.relu.sub = -v
@property
def weight(self): return self.linear.weight
def get_fc_model(data, layers):
model_layers = []
for k in range(len(layers)-2):
model_layers.append(FCLayer(layers[k], layers[k+1], sub=0))
model_layers.append(nn.Linear(layers[-2], layers[-1])) # last layer is without ReLU
return nn.Sequential(*model_layers)
def init_fc_(m, f, nl, a):
if isinstance(m, nn.Linear):
f(m.weight, a=0.1, nonlinearity=nl)
if getattr(m, 'bias', None) is not None: m.bias.data.zero_()
for l in m.children(): init_cnn_(l, f) # recursively proceed into all children of the model
def init_fc(m, uniform=False, nl='relu', a=0.0):
f = init.kaiming_uniform_(nonlinearity=nl, a=a) if uniform else init.kaiming_normal_
init_fc_(m, f, nl, a)
def get_learn_run(layers, data, lr, cbs=None, opt_func=None, uniform=False):
model = get_fc_model(data, layers)
init_fc(model, uniform=uniform)
return get_runner(model, data, lr=lr, cbs=cbs, opt_func=opt_func)
and the actual model initialization happens here (using the same config as before):
sched = combine_scheds([0.3, 0.7], [sched_cos(0.003, 0.6), sched_cos(0.6, 0.002)])
cbfs = [Recorder,
partial(AvgStatsCallback,accuracy),
partial(ParamScheduler, 'lr', sched)]
layers = [m] + [40]*10 + [c]
opt = optim.SGD(model.parameters(), lr=0.01)
learn,run = get_learn_run(layers, data, 0.01, cbs=cbfs)
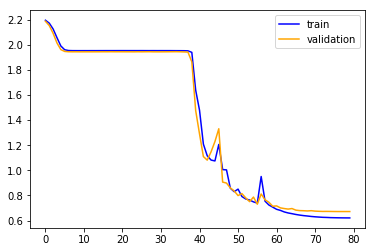
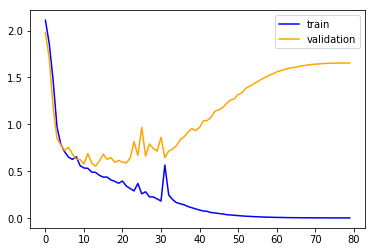
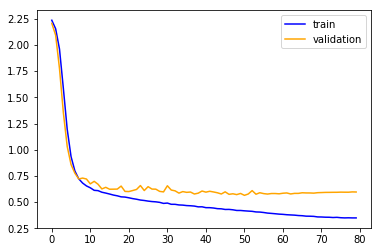
this is the loss evolution when training the model in the usual way (with the default Kaiming init):
and these are the metrics after 80 epochs:
train: [0.560090118024993, tensor(0.7870)]
valid: [0.6289463995033012, tensor(0.7657)]
The LSUV module just worked (after I made all the changes). Here are the means and stds before the LSUV init:
0.20017094910144806 0.37257224321365356
0.10089337080717087 0.16290006041526794
0.030267242342233658 0.05773892626166344
0.04704240337014198 0.05144619196653366
0.0308739822357893 0.051715634763240814
0.03219463303685188 0.047352347522974014
0.02379254810512066 0.041318196803331375
0.031485360115766525 0.04568878561258316
0.04652426764369011 0.05621001869440079
0.04491248354315758 0.06492853164672852
and after the LSUV:
(0.3296891152858734, 0.9999774694442749)
(0.3093450665473938, 0.9999678134918213)
(0.3306814730167389, 0.9998359680175781)
(0.2864744961261749, 1.0004031658172607)
(0.2594984173774719, 0.9999544024467468)
(0.23850639164447784, 1.0)
(0.20919467508792877, 0.9999997019767761)
(0.2371777594089508, 0.9999346137046814)
(0.16776584088802338, 0.9999942779541016)
(0.17556752264499664, 0.9999728202819824)
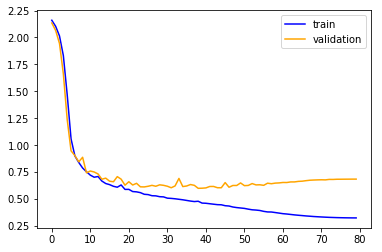
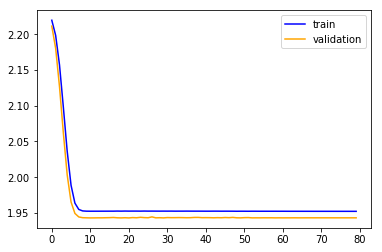
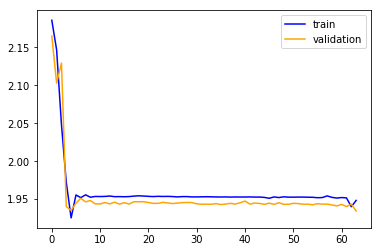
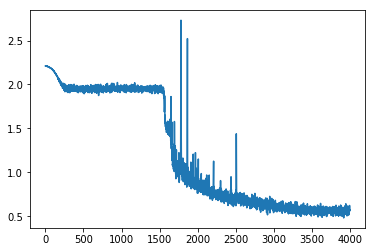
A significant improvement. Let’s train it:
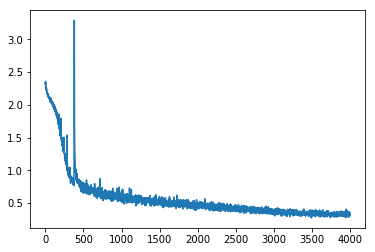
Wow, still slightly bumpy but much much better. Its faster and more stable (the original init sometimes didn’t converge after 80 epochs). The plateau is gone…
And the final metrics are much better for the training, and less good for validation:
train: [0.3298365177516958, tensor(0.8721)]
valid: [0.6690512438988577, tensor(0.7803)]
According to Jeremy, we have 2 stages in training a model:
- overfit.
- reduce overfitting.
I didn’t put a good figure for that here, but I can tell you that now (unlike before) the validation dives to around 0.60 before going up again so we managed to pass the first of the two stages: overfit.
Next i’ll try to show more detailed stats of what is going on in each layer, and then I’ll try to reduce the overfitting to improve validation score!