I am running Mac OS X Big Sur on Apple macbook air m1
with python 3.8 (the python provided by Apple on BigSur)
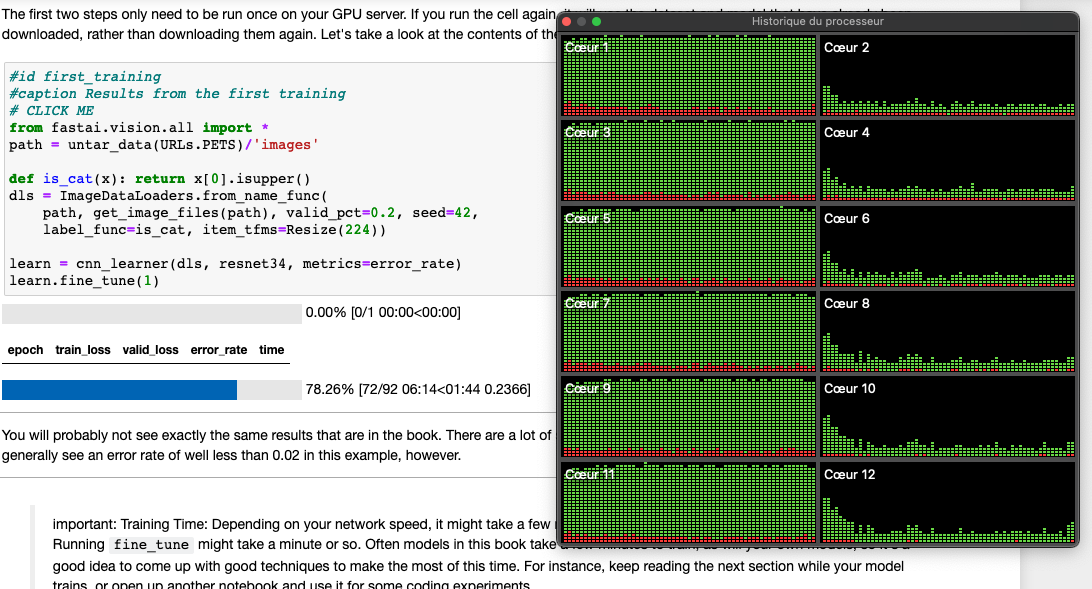
learn.fine_tune(1)
can not be done with Apple Silicon on 01_intro jupyter notebook
i have this log message
[W NNPACK.cpp:80] Could not initialize NNPACK! Reason: Unsupported hardware.
[W ParallelNative.cpp:206] Warning: Cannot set number of intraop threads after parallel work has started or after set_num_threads call when using native parallel backend (function set_num_threads)
the only solution i found is to
export OMP_NUM_THREADS=1
just before starting
jupyter notebook
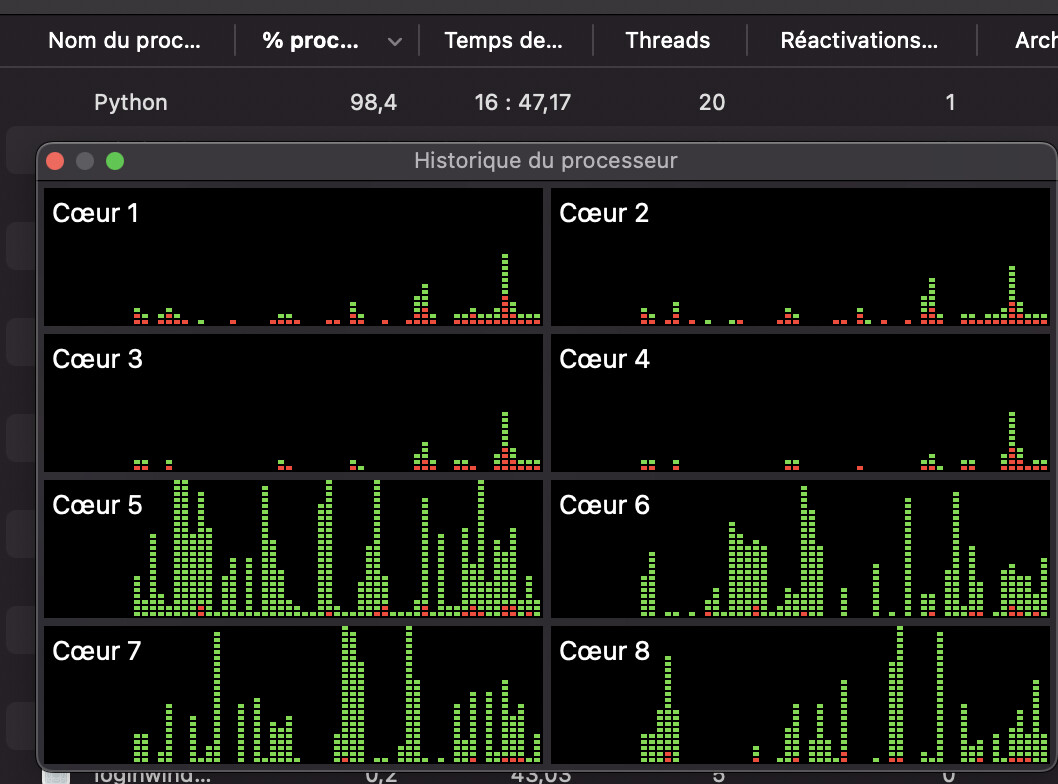
but this is not a good solution because the CPU is only < 100%
Yeah it’s just running on the CPU. You aren’t going to get the speedups you see with TensorFlow because TensorFlow has GPU support for M1 Mac. If you were to run both PyTorch/fastai and TensorFlow on just CPU, they would likely be comparable.
@ilovescience : this is not the reason why i wrote this post.
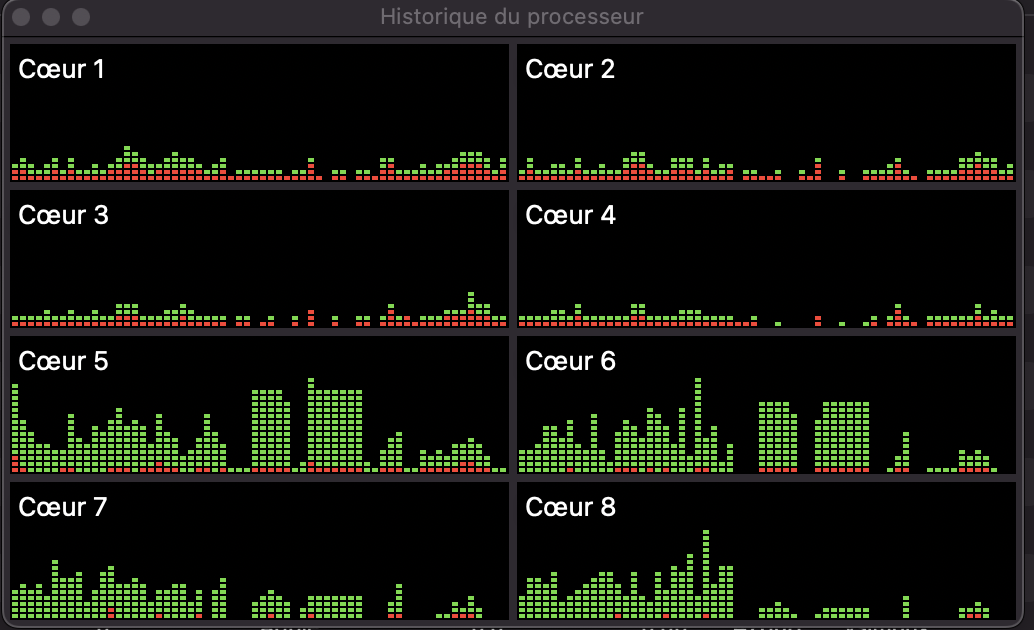
On my Macbook Pro, INTEL version, the fast.ai script runs well without any GPU support, with 6 processes.
On my Macbook Air, M1 version, without Rosetta, the same script can not be run with 2 processes or more, I had to force the export OMP_NUM_THREADS=1