cap_rogers, I’m no expert, but 19K images sounds pretty big. I think I’ve seen advice to work on smaller sub-batches to start with (but I’m not clear on how to do that). Do you have hundreds of different flower categories?
About 100 different classes
Actually that doesn’t seem all that excessive then, and 900KB is pretty reasonable. (My last project had 4K images and took up 1GB of space.) Perhaps someone else will have more experience than I do…
@cap_rogers if you’re having ram issues building your databunch, could you Maybe work with random subsets at a time and continue training? EG 30% at a time, save that Learner, make a new databunch, and load it in? 19k images is a lot for something like colab. When I worked with language models I had the same issue and reducing the amount I was training on was the only fix.
Hello all, I am also taking the course right now.
My repeated biggest difficulties are figuring out how to load my data, and figuring out how to work with different loss functions.
Loading data I think is a deficit in my programming. Can anybody recommend good resources for practical data manipulation? ie working with csvs, dataframes, images
Can anybody recommend the right way to improve my understanding of how to connect the output of fastai’s learners to different loss functions?
The recommended study time is 10 hours per lesson. I spend more like 10 hours per day trying to apply these lessons to anything which diverges from the provided & conveniently formatted datasets. I’m doubtful that I’m spending my time well, but unsure of what else I should be doing.
Does anyone know how to rectify this?
Hello all, I am currently on Lesson-1 and I was trying to practice Image Classification using Kaggle Dataset, I am using Google Colab, so I set up my notebook, downloaded this dataset, here I have a training.zip, validation.zip and a label.txt file, in the video/homework section. it was not discussed as to how to read .txt label file and use ImageDataBunch. How should I assign labels from txt files to training examples ?
Your reply is truly appreciated
I am in the same boat as you, I wasted 5 hours today trying to work my hands on a kaggle dataset for lesson-1 and stuck, the biggest hurdle for me is also as to how to load my data
Hi @y14uc220,
I am also in the same boat, actually i am getting easily distracted with lot of content.
I have completed the Workshop video for setup and Lesson-1 videos. I was playing with the google colab and the next thing i will be doing is to put the lesson-1 in practise.
I see recent posts from @chandresh and @jianjye on completion of Lesson-1, please wait for their response.
People here are very helpful.
Thanks.

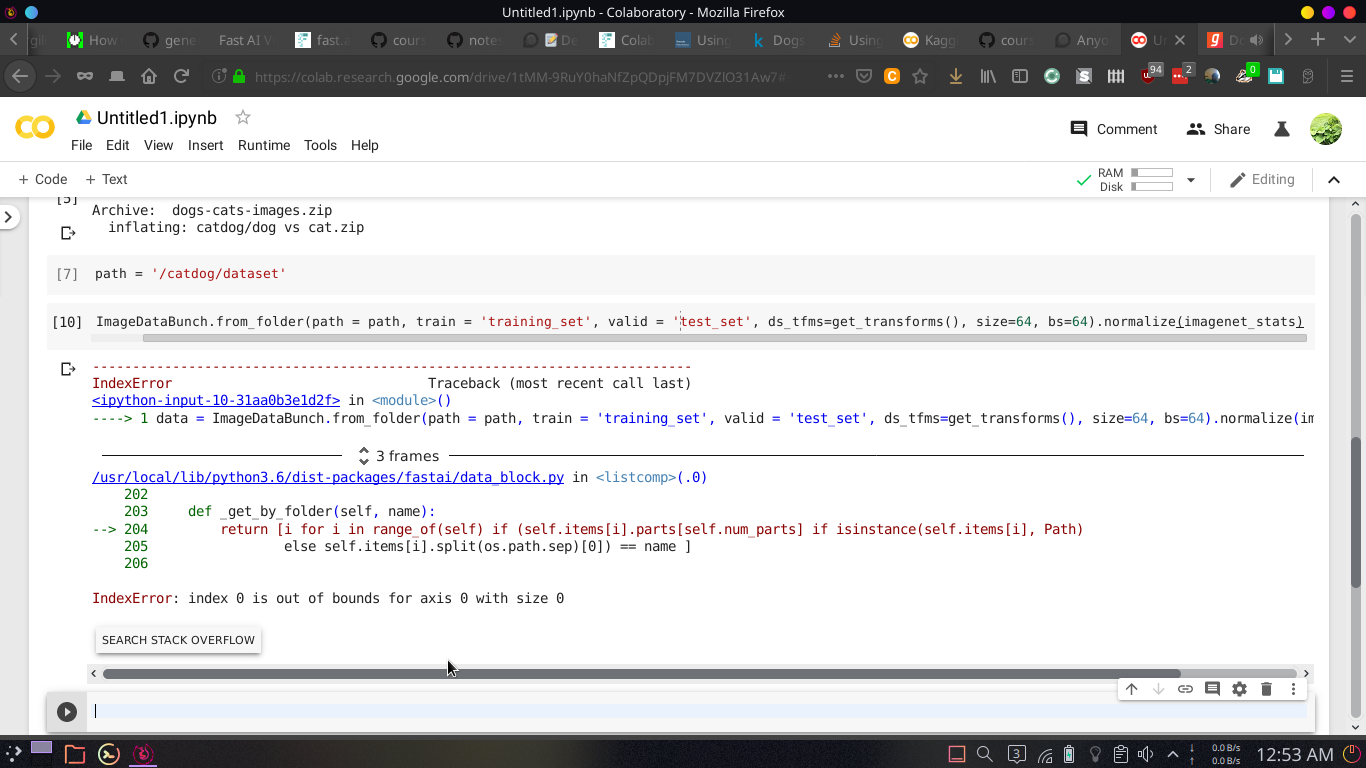
if you can help me, if I have a dataset having test-set and training-set as two folders and if I have to use ImageDataBunch.from_folder, how to set train = training-set and valid = test-set
I think usually the test data won’t be labelled and it is not a good idea to validate on test data.Instead ,you could adjust the validation split using ‘valid_pct’.
I tried it and got the same error
my pwd is /content, I extracted my dataset to /catdog/dataset which contains two folders test_set and training_set,
I did what you said and set valid_pct = 0.2 and got this error, can you help me ?
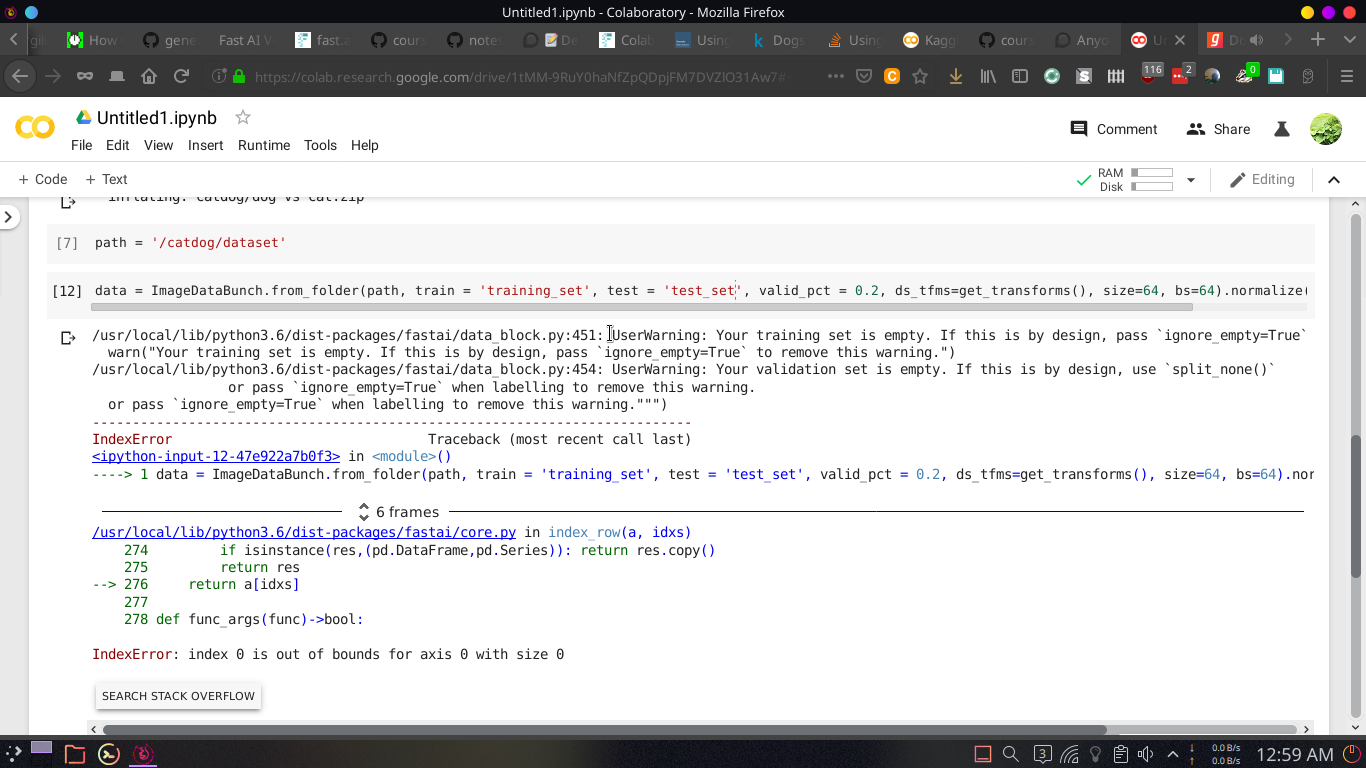
Have you tried using the data block api? It seems like the idiomatic way FastAI is developing.
data = (ImageList.from_folder(path) #Where to find the data? -> in path and its subfolders
.split_by_rand_pct() #How to split in train/valid? -> use rand split
.label_from_folder(train='training_set') #How to label? -> depending on the folder of the filenames
.add_test_folder('test_set') #Optionally add a test set (here default name is test)
.transform(get_transforms(), size=64) #Data augmentation? -> use tfms with a size of 64
.databunch(bs=64)) #Finally? -> use the defaults for conversion to ImageDataBunch
1 Like
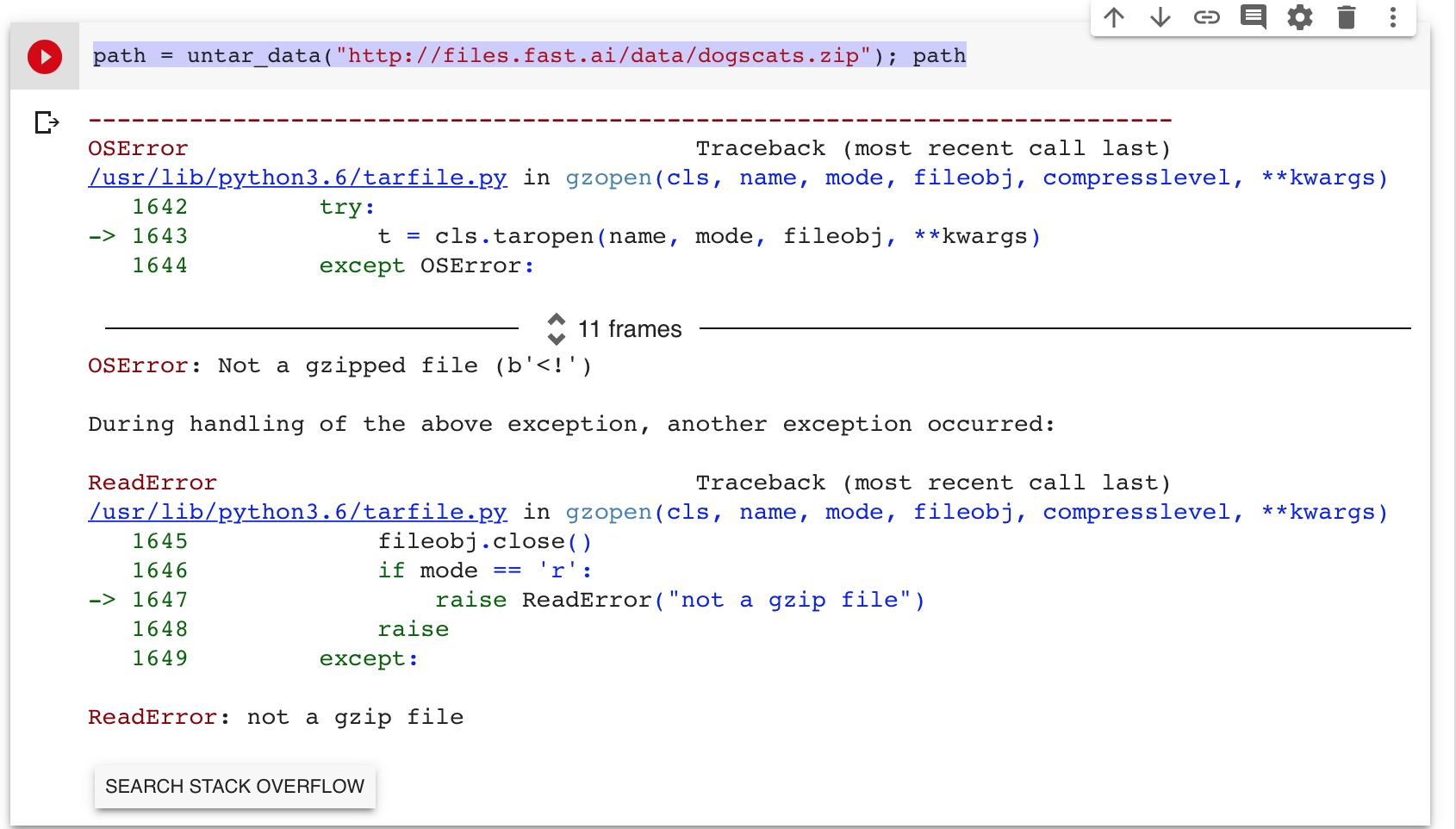
untar_data() can be used only for gzip or bz2 files. You can try !unzip
Hi Kuruvam,
I’m at lesson 3. Willing to help and collaborate. I’m using google Colab, making a copy of the notebooks, working through it, and then using new data on what I learnt. I also know some Pytorch. Here is FLowerApp I made : https://whispering-fortress-34008.herokuapp.com/
It’s a bad model, but i just wanted to code an end-to-end system. We can learn together.
1 Like
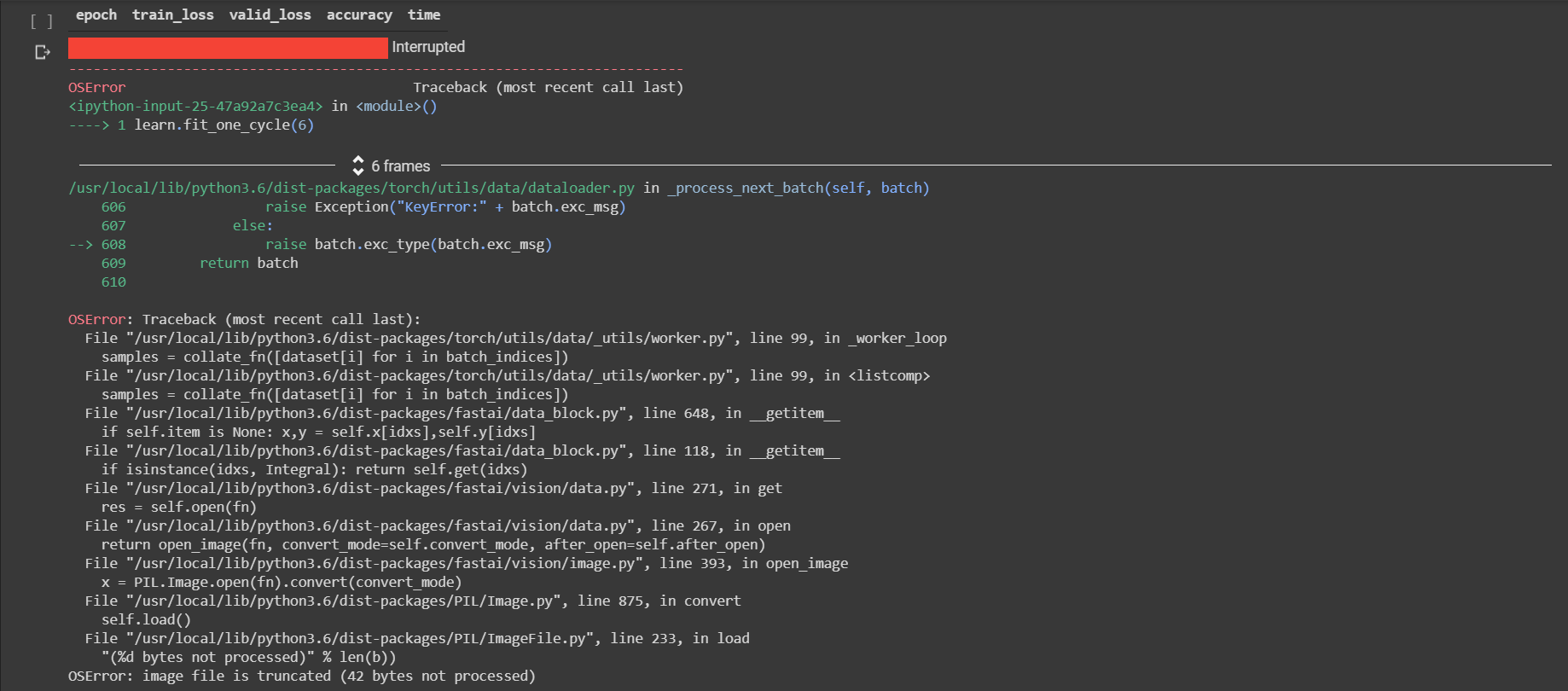
Hi there,
I am also new here and currently on lesson 7
have you tried to change the runtime type to GPU?
that way you could have more space.
I’ve started the part 1 2019 course not long ago. while following along, i noticed that when i run the learn.fit_one_cycle method, it doesn’t display the loss and error figures as they do in the course videos. i am using spyder from anaconda rather than jupyter, but other things (such as progress bars, show batch) are displaying correctly. doesn’t feel like there should be any reasons why the losses/errors don’t display. does any one have any ideas as to the cause of this and how to resolve it? thanks
edit: i tried this again with the cnn_learner method and experienced the same lack of display issue as above. i also noticed that fit one cycle for both of these are much slower than the ~2 mins indicated in the videos. this could suggest that GPU is not being used but i can see the dedicated GPU memory being consumed. does anyone have any thoughts on the above?