Nvidia just released a new library that provides gpu support for data processing using pandas syntax. Seems like it’s really powerful and could be a good addition to the library / notebooks.
I haven’t evaluated it yet, and I’m curious if anyone has explored it?
While I am very enthusiastic about GPU-enabled computations, I am skeptical about relying on proprietary tools when this can be avoided. This tool (which, I suppose is very good in terms of performance and quality) means you will probably need a powerful enough GPU with lots of memory for routine data analysis.
If you do need some speedup, you can utilize multiple cores of your CPU using Dask.
I wanted to explore it, but until 6h ago it was all only marketing. I was at the nvidia conference where they announced it, and the webpage was up and running, but there was actually nothing to test yet. The instructions said to download the docker containers, but those were only pushed today and the official repo was not up to date. So nobody can have really tested that yet
Having said that, I intend to test it a little and see what speedups are actually possible and how it feels compared to pandas.
and now it’s 12 pulls, that was me
And this seems to be very much still under development. 5GB docker container??? Not quite as lightweight as pip install pandas
EDIT: to be fair, 2.3GB of the 5GB mentioned are tar.gz files with the demo data…
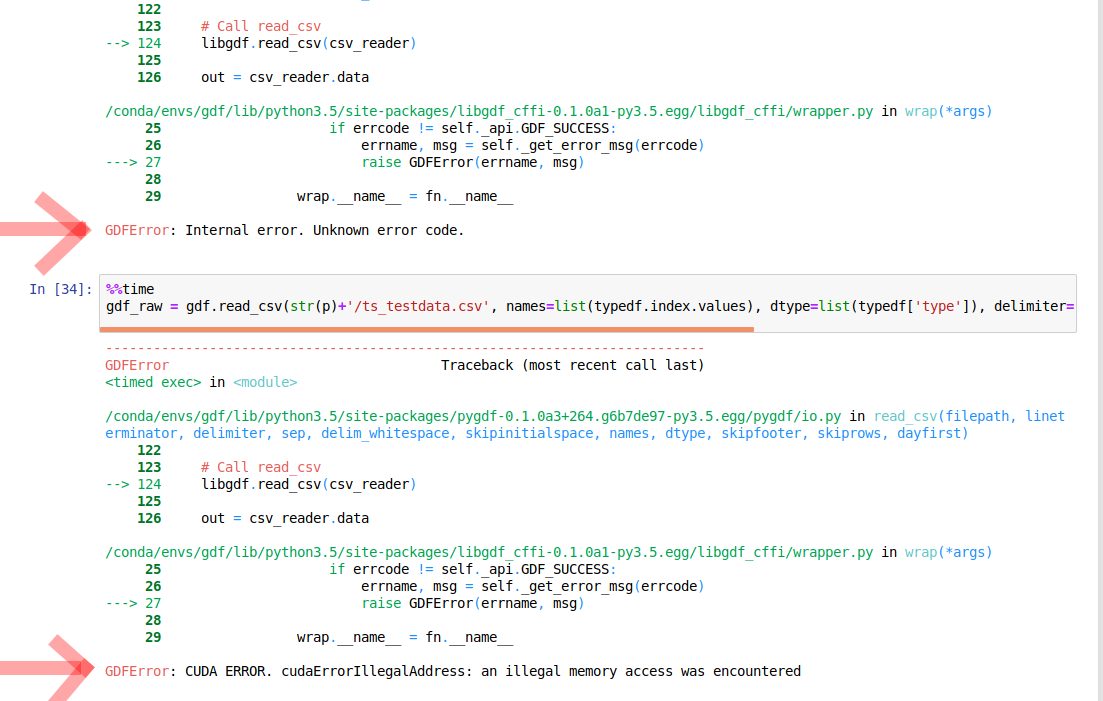
So, I played around with it for an hour with the official docker image. In this hour, I have only unsuccessfully tested the read_csv function.
My impression is that this is still very much alpha and I will be wasting much more time preparing and bug tracking than I will currently save due to the possible GPU acceleration. The error messages are quite unhelpful as you can see below, I cannot even get the simple csvs to load. Of course that might be me, but with pandas all of this is a oneliner that simply works. Documentation is also lacking, I can’t even find an official list of the available datatypes. Another little thing: I am currently not able to use pathlib.Path for the file access (Error because they expect the filepath to be of type string apparently).
One observation: Currently the read_csv function alone lacks many of the features that pandas has, but that is to be expected. But one of the most annoying missing features is the automatic datatype inference. With gdf you have to specify the column names and column datatypes by hand, which means you first have to load everything with pandas to make this a semi automated process (unless you have only a small number of cols and want to do this by hand). While I might do the dtype-specification for pandas sometimes as a speed optimization, this is very annoying to have to be done generally. I have read though that this feature is in the pipelines.
So, I am stopping my experiments for now. Happy to see if any of you get some more interesting results or hints on what my problems could be.
If someone wants to try, this is the way I semiautomatically created the colums-type lists (maybe there is a bug here?)
df_raw = pd.read_csv(p/'ts_testdata.csv', nrows=10)
typedf = pd.DataFrame(index=df_raw.columns)
typedf['type'] = None
for col in df_raw.columns:
typedf['type'].loc[col] = str(df_raw[col].dtype)
typedf.loc[typedf['type']=='object', 'type'] = 'category'
typedf.loc['time'] = 'date'
Thanks for sharing your impressions. Sounds like it’s a little too alpha right now to really be useful. I’ll be curious to see if they can make it easier to use. Until they do I don’t think i’ll be exploring it.
Just attended a local meetup where Nvidia also presented rapids.ai stuff (cuML, cuDF). Super intrigued… Also their docker architecture seems real nice.
One thing I was wondering is: how big is the difference to pandas, sklearn? Are we talking 80%, 90% of the imoortant stuff (minus some edge cases)…?
Reading about read_csv crapping out is kind of a bummer though
Also, would there be a seamless solution to work on non GPU-machines with small data locally and then simply push to AWS, GCP with loads of GPUs for the big stuff?!?
Hi all, I’m knew here so I’m not sure if this thread is still active, but I’m the director of engineering at NVIDIA responsible for RAPIDS. We’re actively working on fixing the issues discussed here, and the project is fairly new.
We are not at feature parity with pandas nor sklearn, but our goal is to continue to add features and improve usability. Reading csv on GPU is not trivial, and I think you will be happy with our most recent versions which also has better string support.
We have new containers, conda packaging, will add pip soon, and did a massive refactor to make our repos cleaner and easier to fix and contribute to. I would love it if you all took a moment to try it out, and report any issues you find. We will continue to push ahead, but it’s not possible without end user support from people such as you all.
Great to have you here! I’ve been following the progress on twitter and I’ve been impressed with the pace that the team has been pushing these updates. The conda installs are really helpful, and I’ve got it running on my machine but have yet to work it into an application. I definitely see the need; I do most of my preprocessing in my ETL currently and this would be a big step up. One thing that might help push adoption is the development of some notebooks that use the library and demonstrates it’s impact directly. Jeremy uses notebooks quite effectively to spread the fastai usage and it’s been really successful.
I’ll download 0.4 and try to give it a spin sometime later this week. I’m currently on pat leave with a newborn so it might take a while to dive into it fully though, but thanks for the amazing tool and for connecting with the community.
Just a quick note:
We were competing in the current PLAsTiCC kaggle competition (ended yesterday), the 8th place solution there is advertising the use of rapids.ai.
The guy is an nvidia employee and so far this may be only free advertising and good product placement (Joshua? ) but what I wanted to get at is that the guy says he will publish his/ a notebook with how he used rapids here.
This would have been a really good usecase because one time-wise bottleneck in this competition was calculating the features on a half-a-billion row (453.65 Million) test set of tabular data, which took hours with pandas. So maybe there will be a good “real world” demo of rapids to come out of this, let’s see.
It would be really bad form for Jiwei to mention RAPIDS only as product placement… especially given his Kaggle Grand Master reputation.
@marcmuc please try it out. It’s very much still early, but there are many things you can do on a single GPU. Jiwei used a GV100 (which has 32GB of memory), but RAPIDS works with smaller GPU (though a big more difficult). We’re working on dask integration to make it even easier to use cuDF with data sets larger than a single GPU memory, with out of core or, the best way we prefer users to use dask, with multiple GPU.
I didn’t think it was just product placement, otherwise I wouldn’t have posted it here. Thanks for the pointers to the other demo notebooks, will check it out again.
Thank you! Also we should have a parquet and orc reader in the next couple of weeks, and new things coming out in our 0.5 release. Definitely some rough edges here and there, but trying to smooth everything out. Have a merry Christmas and Happy Holiday!




 ) but what I wanted to get at is that the guy says he will publish his/ a notebook with how he used rapids here.
) but what I wanted to get at is that the guy says he will publish his/ a notebook with how he used rapids here.