The papers I posted just use SELECT, FROM, WHERE in addition to aggregation functions, and that’s it- as far as i saw.
1 Like
A simple SELECT X FROM TABLE WHERE X > Ywould be relatively strict forward, probably regex can do the job. But as you said, complexity adds up quickly if JOIN and schema have to be considered.
Here’s a small program that validates partial (or full) SQL statements from the command line. You could play with it, or shell out to it during a beam search and/or loss evaluation.
1 Like
Or just create a simple FSM yourself - here’s a helpful start: https://medium.com/@brianray_7981/tutorial-write-a-finite-state-machine-to-parse-a-custom-language-in-pure-python-1c11ade9bd43
4 Likes
Thanks Jeremy. I would love to create one myself to test my understanding, as this is a new concept to me.
First results after a ton of help from @hiromi at our study group yesterday:
Command:
tok_translate("""select *""", 5)
Output:
'select * from badges where _unk_ *'
2 Likes
Here’s another interesting result. I fed “select *” and the rest is generated from the model.
'select * badges t_up from users b t_up where bb.id is t_up null t_up and t_up not t_up exists ( t_up select * t_up from badges b'
Looking good! Since sql isn’t case sensitive you could get rid of the t_ups from your tokenized corpus btw.
1 Like
It looks good, I guess we have similar approach. Seems that you are also using the spacy tokenizer. But I first replace special token like “.” to " . " so that “bb.id” is three token instead of one.
Similar result that I get.
a=get_sentence(['t_up','select','*','t_up','from','where','customer'])
show_sentence(a)
" SELECT * FROM where customer LIKE ' % < % ' or LOWER ( location ) LIKE ' % india % ' ORDER by reputation DESC ; _eos_"
1 Like
May I ask which dataset you are using?
I used the senlidb to start out with.
I’m working on a medium post to describe what this type of SQL generator could do for people and a little bit about how the actual model works.
1 Like
Yeah, I probably shouldn’t be tokenizing with spacy_tok, since that is more meant for sentences. That might help my results a bit. Could I see what your get_sentence looks like? Also do you think it’s best to have “bb” “.” and “id” to all be tokenized separately, or does it make more sense to tokenize them together? I guess the advantage of having them all being separate is that the model could determine this, but I think the column names are going to be the hardest part for a model to train since there really isn’t any consistency to the column names a lot of the time.
Imo “bb.id” shouldn’t be a token at all. It’s just “_xcol_” or something which will be a column from the schema provided at time of inference.
1 Like
In my mind, figuring out how subjects of the sentence map to specific members of the schema, is a separate problem.
My Code are quite messy at the moment, but it basically follow what Jeremy’s said.
For now I have tokenize “bb” “.” “id” as 3 tokens. I agree columns name is a problem as a lot of column/table names only appears a few times. When I call get_sentence(), sometimes it go into a dead loop and generating the same repeat words. I haven’t figure it out yet, not sure is it because I haven’t train the model long enough.
For now, I am trying to combine the Finite State Machine into get_sentence().
- get_sentence will call get_nextword(), where it is not actually a word, but a list of probabilities of all the token.
- the list of probabilities is passed into the Finite State Machine, where it will filter out the invalid word.
- Sort the probabilities, get the largest 5-10 words, and then use np.random.choice() to sample them to add some sort of randomness. (Hoping this can help the issue that the model always generate the same word)
- The word is feed to FSM and update the state and the word is feed into the next get_nextword()
- End when the generated word is “eos” or exceed a certain length.
I only have the simplest FSM at the moment, where it only accept a sentence looks like “SELECT X FROM Y”. I am hoping that to demonstrate a get_sentence() with/without FSM and show how a model that generating random sequence can be modified to generate a restricted form of sequence.
Once I can get FSM into the get_sentence() function, I will re-visit the FSM to add richer state that it can at least recognize pattern like multiple columns. It is more like a proof of concept, so I don’t want to spend too many times on making the machine a perfect SQL validator.
Regards to the “Column name only appears once problem”, I am actually thinking to generate sentence in a “Character Level”, except that SQL Keyword will be still one token.
i.e. a = 0, b= 1, c= 2 ,d=3, … “select” =50, “where”=51, and hopefully it can deal with the problem that tokenizing a unique column name as 1 token. But it is too much at my hands now, I am aiming to finish the whole thing and then improve it bit by bit.
2 Likes
I actually got to set aside some time to work on this!
So I’m at the pre FSM stage still, but I am generating random sql.
Some are definitely better than others, but I am not at all choosing ones that look better. These are just a few random ones. If there’s interest in seeing more of what it’s generating, grab my notebook below.
SELECT xschema AS xschema , xschema AS [ xschema xschema ] FROM xschema ORDER BY xliteral ASC ;
SELECT sum ( xschema ) xschema count ( * ) AS xschema FROM xschema WHERE xschema = xliteral ;
SELECT * FROM xschema WHERE xschema LIKE xliteral % xschema % xliteral ;
UPDATE xschema SET xschema = xschema FROM ( SELECT * , xschema ( ) OVER ( xschema BY xschema ORDER BY xschema ) AS xschema FROM xschema ) xschema RIGHT OUTER JOIN xschema xschema ON xschema ( xschema ) LIKE xliteral % xliteral + xschema + xliteral % xliteral ORDER BY xliteral ;
UPDATE xschema SET xschema = xschema ( xschema , xliteral , CONVERT ( xschema , xschema - xliteral ) ) EXEC xschema xschema ORDER BY xschema ( xschema , xschema , xschema ) ;
UPDATE xschema SELECT TOP xliteral _unk_ _unk_ xschema , CAST FROM xschema AS xschema ( xliteral ) ) , xschema ( xliteral [ xliteral , xschema ) , xliteral xliteral , xschema ( xliteral ) FROM xschema WHERE xschema = xschema AND xschema = xliteral ORDER BY xschema ASC , xschema ;
Just as a bit of an explanation: xschema and xliteral are either a member of the schema or a value, like a string or number, respectively.
I let it generate until it generates a semicolon.
So I noticed that I’m approaching this pretty differently than others. I manually defined valid tokens first, and it can’t generate individual characters, only SQL keywords, one of a number of symbols, and either xschema or xliteral.
Also training on SENLIDB like others.
More examples…

And here’s the notebook…
1 Like
I found the Tokenizer is not behaving as expected, for example, “id” is tokenized as “i”, “d”

My pre-processing step:
- pad space for all special token, ie !@#$%()
- do a simple str.split()
I read Tokenizer.proc_all_mp and found it is easy to build a custom tokenizer with multi-processing. I found doing a simple for loop is much faster in this case, maybe the operation is too simple so it doesn’t worth to use multi-process.
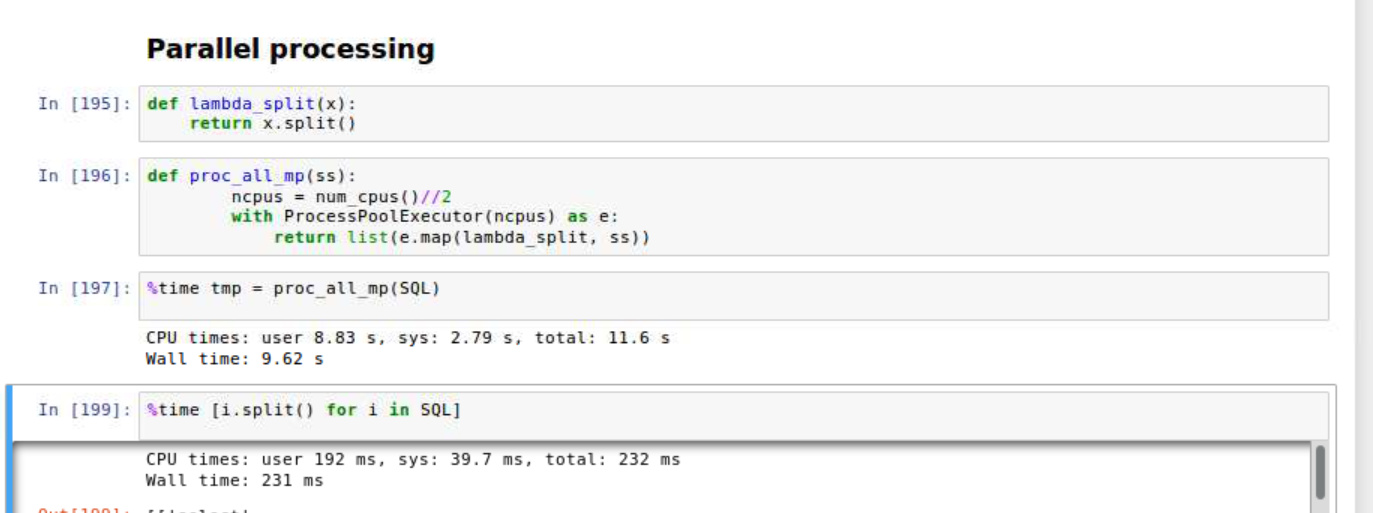
Interesting. I’m guessing this is spacy trying to tokenize I’d but even doing that without the apostrophe. Maybe intentional - I don’t know.
Although you probably should replace field names with a single FLD_NAME token. And probably shouldn’t use spacy for sql anyway.
1 Like
May I ask how did you come up with the SQL keyword list?
Googled around- i believe I used a combination of the Oracle and SQL server docs.