For those who might be encountering a similar issue… I found the solution in a another post here: Proc_df() for machine learning course
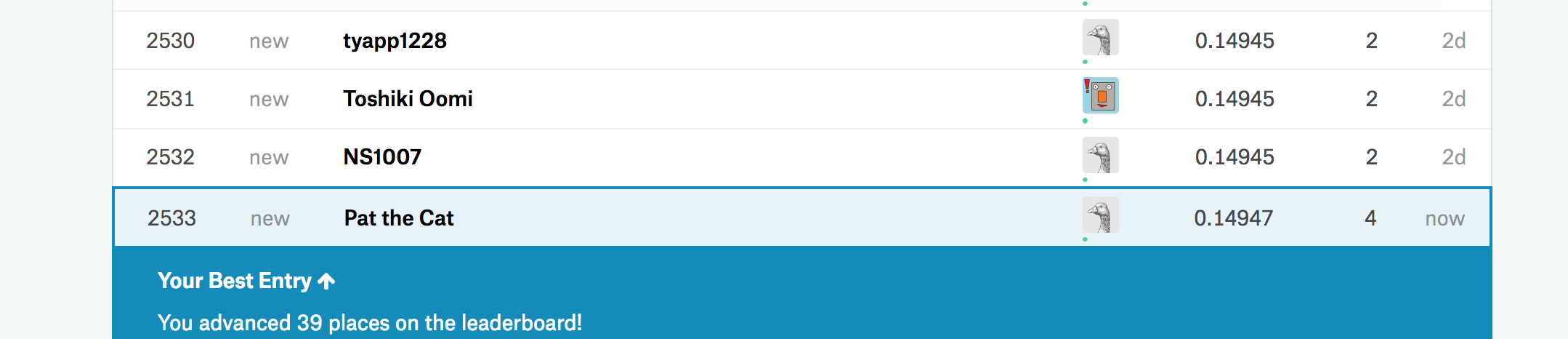
I successfully submitted results to Kaggle and ranked at 2882 out of 4379 entries
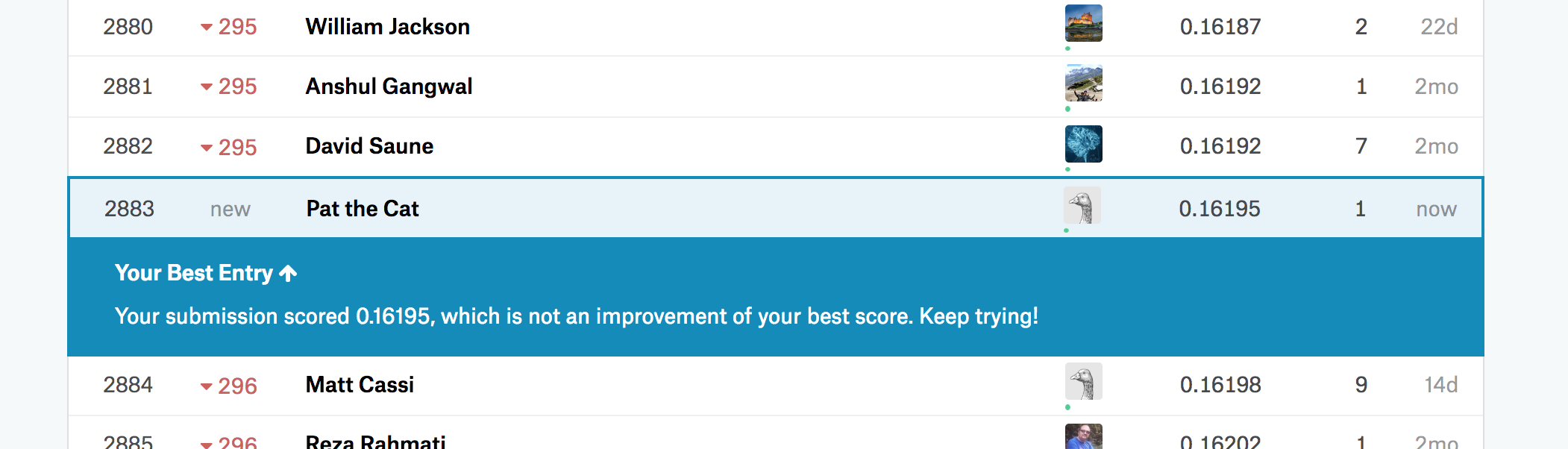
By using the concepts from week #2, I was able to move up by 300 ranks (from 2883 to 2533).