So I’ve trained a language model on a subset of Stackoverflow questions. The language model trained amazingly well; I got it up to ~68% accuracy and the questions it generates are pretty good! (You can see some of the questions it generated on this site I’m working on).
Now I’m trying to use that language model to create a regression model (or classifier; I’ve tried both) that can predict how many views and votes a question will get.
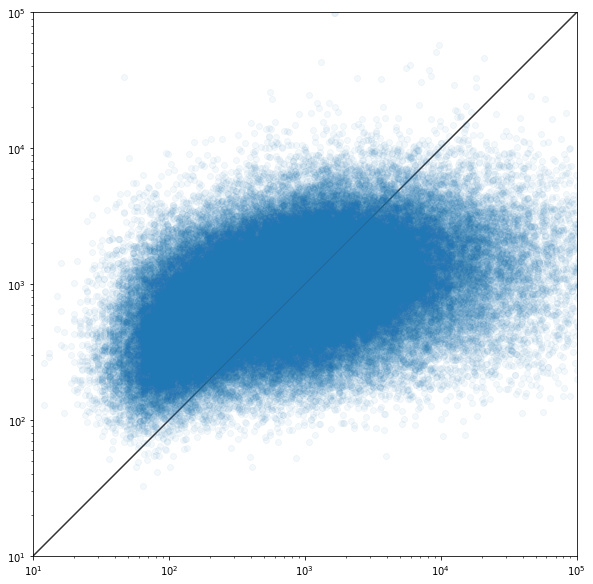
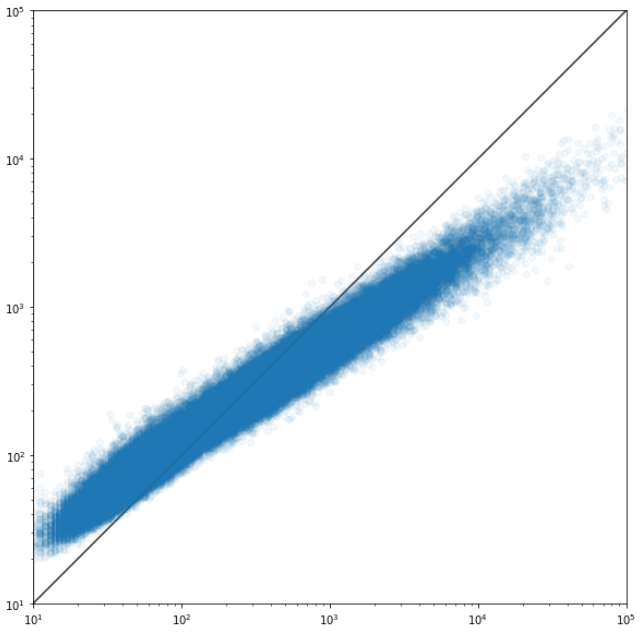
It’s failing miserably. The scatterplot of actuals to predictions looks like random noise.
Binning and doing a classification instead of a regression,
Transforming inputs in a few different ways (taking the log, clipping, etc)
Normalization (both before and after data transformation)
Playing with dropout
Messing with momentum
Adjusting batch size
Using much more data to train on (left it going over the weekend)
Using a variety of learning rates
Using the wt103 weights instead of my language model
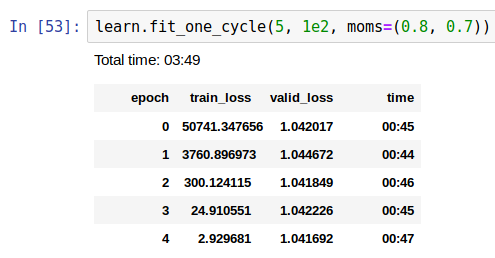
Nothing seems to give me anything that looks better than random noise… and my validation loss stayed about the same even when I tried to blow up the model by using a learning rate of 100.
How do I know that I’m fighting a losing battle? Is it possible that Stackoverflow upvotes and pageviews just aren’t at all correlated with the content of the questions?
Or is there anything else I can try?
Edit: In writing this question it occurred to me that it might be a good idea to test what would happen if I randomly shuffled the label values and see what happens when I try to train the model… and the results look pretty much the same as with the actual data.
So now my question is: how can I tell if my data is actually not at all correlated or if I’m messing up the encoding somehow?
Have you tried simpler modeling to see what kind of results you get? For example, if a Naive Bayes classifier on bag-of-words representation performs better, this might suggest a problem with your language model. Conversely, if it also looks no better than random chance, it lends support to the notion that language features aren’t well correlated with your variables of interest.
Are your labels lined up correctly?
Are you using the right vocabulary mapping (itos, stoi) for your language model? (I’ve personally messed this one up and I can tell you it makes everything fail). This could happen if you’re not loading the fine tuned language model vocabulary into the dataloader for the classification model (remember the fine tuned model will have a different vocabulary to the wikitext 103 model).
When you print out data in your dataloader, does your x and y data look correct?
The fact that you can blast the model with a learning rate of 100 without everything blowing up is weird. There’s something there but I don’t know what.
Some other things I’d check:
Is there some consistent token structure or tag present in the training data that forms a simple pattern that is unrelated to your classification task? This could explain why fine tuning a language model works so well, while classification doesn’t.
Can you overfit to a single batch? Try get like 1-2 batches of data for training and validation. You should be able to train to a point of ~0 train error (overfitting to the small dataset) while the validation error should diverge.
I’ve tried double and triple checking all of this. As far as I can tell the labels look good and the vocabulary looks right.
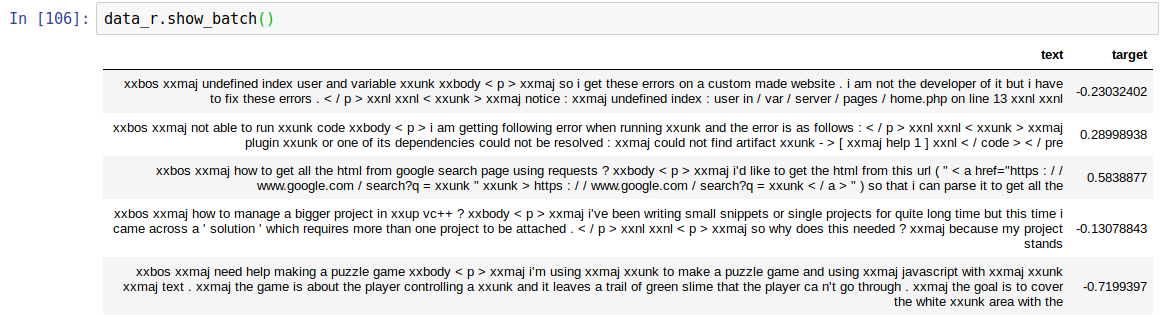
The data I see from show_batch looks good as far as I can see – anything specific to look out for here? (I am passing the vocab I pickled from the language model to the TextList construction but not sure how to know if I made a mistake somewhere along the way).
Here’s an example, I tried googling a few of these and backing out the target value to make sure it looked right and as far as I can tell they do.
For example, the first one -0.23032402, multiply by the std (1.5098) add the mean (5.7504), and take the exponential (these are from the log) gives 222. And if I Google the title I find the original question and the number of views is 235 (which is the right ballpark since the data dump is from a month or so ago).
I think the code and html tags may be easier for it to predict which is why the language model turned out to be so accurate. But the text predictions it makes actually do look good.
I also uploaded a subset of the data to Google AutoML Natural Language Beta. It’s training now so hopefully I’ll be able to see if it does any better soon.
If that also produces poor results I think I’m about ready to come to the conclusion that the contents of a Stackoverflow post don’t correlate with the number of views or upvotes it gets… Which is actually a really surprising result!
Intuitively I’d think it would… but looking at some of the “popular” questions and some of the “unpopular” ones I as a human don’t see any rhyme or reason to it either.
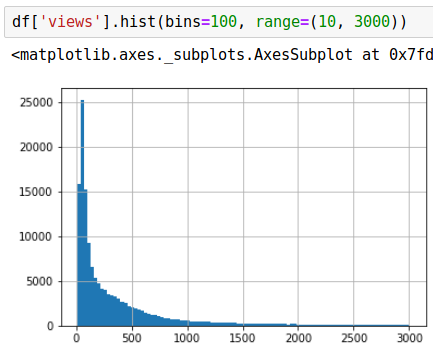
The thing that’s making me kind of second guess this is the power law distribution of views on posts. I don’t know if there’s a good way to predict something with this distribution at all since it’s so heavily weighted towards posts with only a few dozen views.
Here’s a histogram of the distribution (clipped because the post with the most views has 26,000):
I found it hard to believe that there is no signal at all.
If you take a few steps back and bin it to two classes such as high/low (on number of views). Pick the 1000 most popular questions vs 1000 old questions (that has had the chance to be read, but was not) and build something with bag of words, and also add stylometric features such as readability measures like flesch kincaid.
The reason I mention readability measures is that they have shown to be correlated with the impact factor of academic papers.
I did a test where I binned into “famous” and “downvoted” and balanced them so they were roughly equal sized bins (I think that meant less than zero and more than 50 votes but can’t remember exactly).
The RNN based classifier was able to get ~70% accuracy on that. So it’s not nothing but not very useful either.
It’s when I tried to do anything meaningful with larger sets of the data that it didn’t seem any better than random noise.
Few years ago (before all DL hype) I’ve tried to build an SVM model between issue content and time, required to close it. Found very little correlation.
I guess, the same goes with the SO content vs upvotes.