Great post from Airbnb just out last week describing how they use entity embeddings to improve their recommended listings by similarity and personalize searches in real-time for users. Also describes the ways they evaluate and tweak offline first before putting into production:
As an aside, I’m trying to brush up on my rudimentary math equation comprehension skills. Here’s their optimization objective as described:
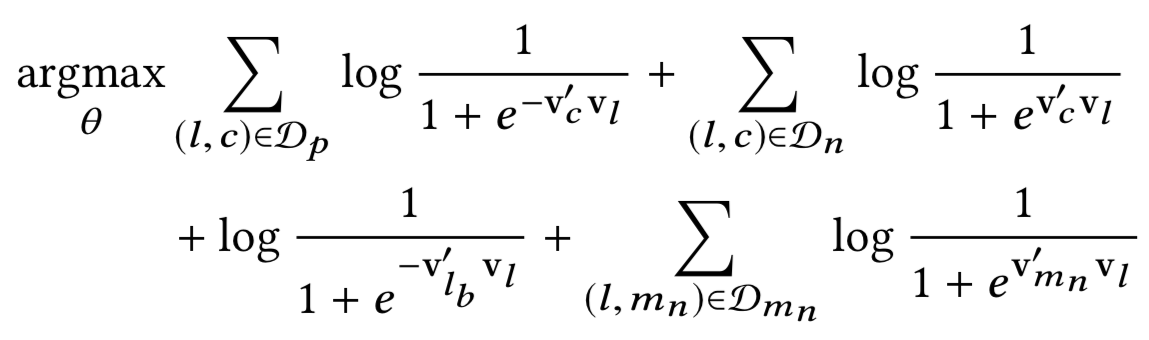
where
l is the central listing whose vector v(l) is being updated
Dp is a positive set of pairs (l,c) that represent (central listing, context listing) tuples whose vectors are being pushed toward one another
Dn is a negative set of pairs (l,c) that represent (central listing, random listing) tuples whose vectors are being pushed away from each other
lb is booked listing that is treated as global context and pushed toward central listing vector
Dmn is a market negatives set of pairs (l,mn) that represent (central listing, random listing from same market) tuples whose vectors are being pushed away from each other
Here’s my layperson interpretation of what this optimization objective means:
- find the dot product of all 2 vector pairs in the sets of positive pairs Dp, negative pairs Dn, & market negative pairs Dmn
- apply sigmoid function to the single number outputs of these dot products (& switching to negative sign in the cases of Dn and Dmn)
- take the log of these sigmoid outputs
- sum up each log(sigmoid(dotproduct(v’v) for each pair in Dp, Dn, Dmn
- add the log(sigmoid(dotproduct(lb, l) as a “global context” for the central listing vector l
- add everything together and set training to find the argmax (the largest sum total)
- this represents a training objective of finding the highest “similarity” value between the central listing vector and its positive “context listings” vectors and minimize the value between the central listing vector and its negative pairings. In other words, push the central listing embedding vector “towards” embeddings of similar listings and push the central listing vector away from random (aka negative, presumably dissimilar) listings.
Do I understand this correctly?