New Paper on Bias in Analogies
Summary: Turns out “Man is to Computer Programmer as Woman is to Homemaker” came about because of an external constraint placed on the model - it was not allowed to return words/vectors too close to any input vector!
The authors recommend listing the top-N returned words, without any constraints on the model, to determine real bias (as opposed to sensationally cherry-picking returned words). So I did just that. And here is what I found for the query “boy is to handsome as girl is to ??” when the model was trained on Reddit:
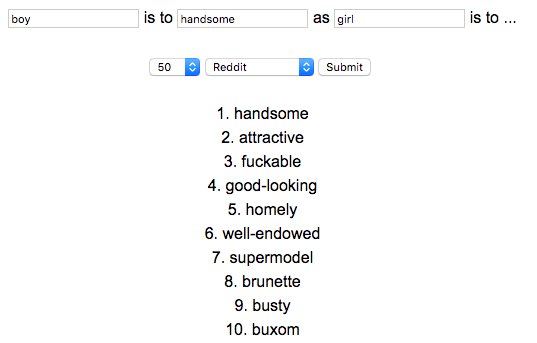
Same query in reverse (“girl is to handsome as boy is to”) on same data/model returns:
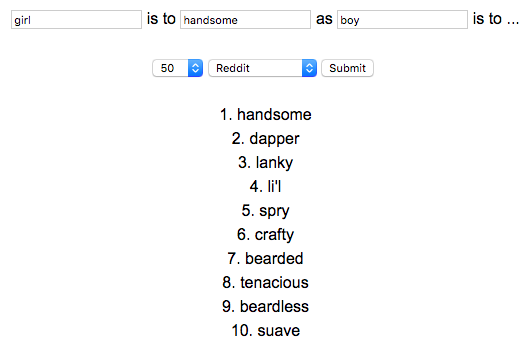
This paper tests across 3 word embedding spaces - Google News, De-biased Reddit and original Reddit. Google News and De-biased Reddit had slightly better output.
Which brings me to an important question/observation - why do NLP researchers rely on Reddit for training when it’s well known to be biased (see this and this)? Even GPT-2 is trained on links recommended on Reddit, from their blog:
“In order to preserve document quality, we used only pages which have been curated/filtered by humans—specifically, we used outbound links from Reddit which received at least 3 karma.”
Also, the paper says analogies aren’t the best way to identify bias in existing text. If so, what is?