Hi Dooley,
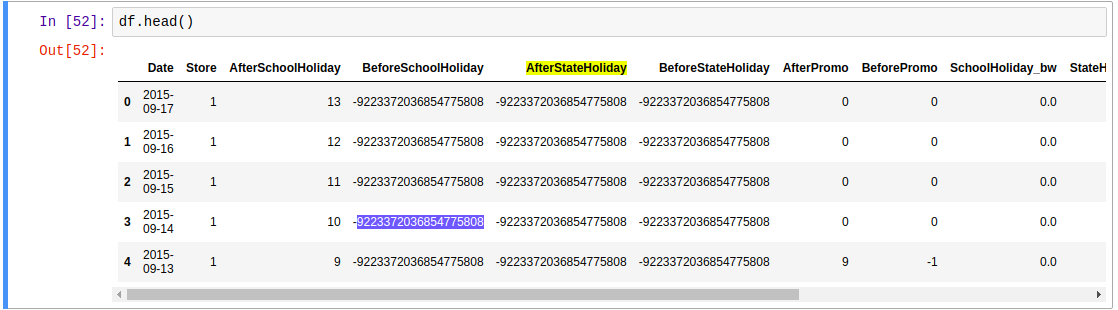
Thank you for this response.I converted the large negative values using df.replace(-9223372036854775808,0).
Did you see a drop on performance when you submitted to kaggle? In my approach, I did worse than taking the median for day of week.
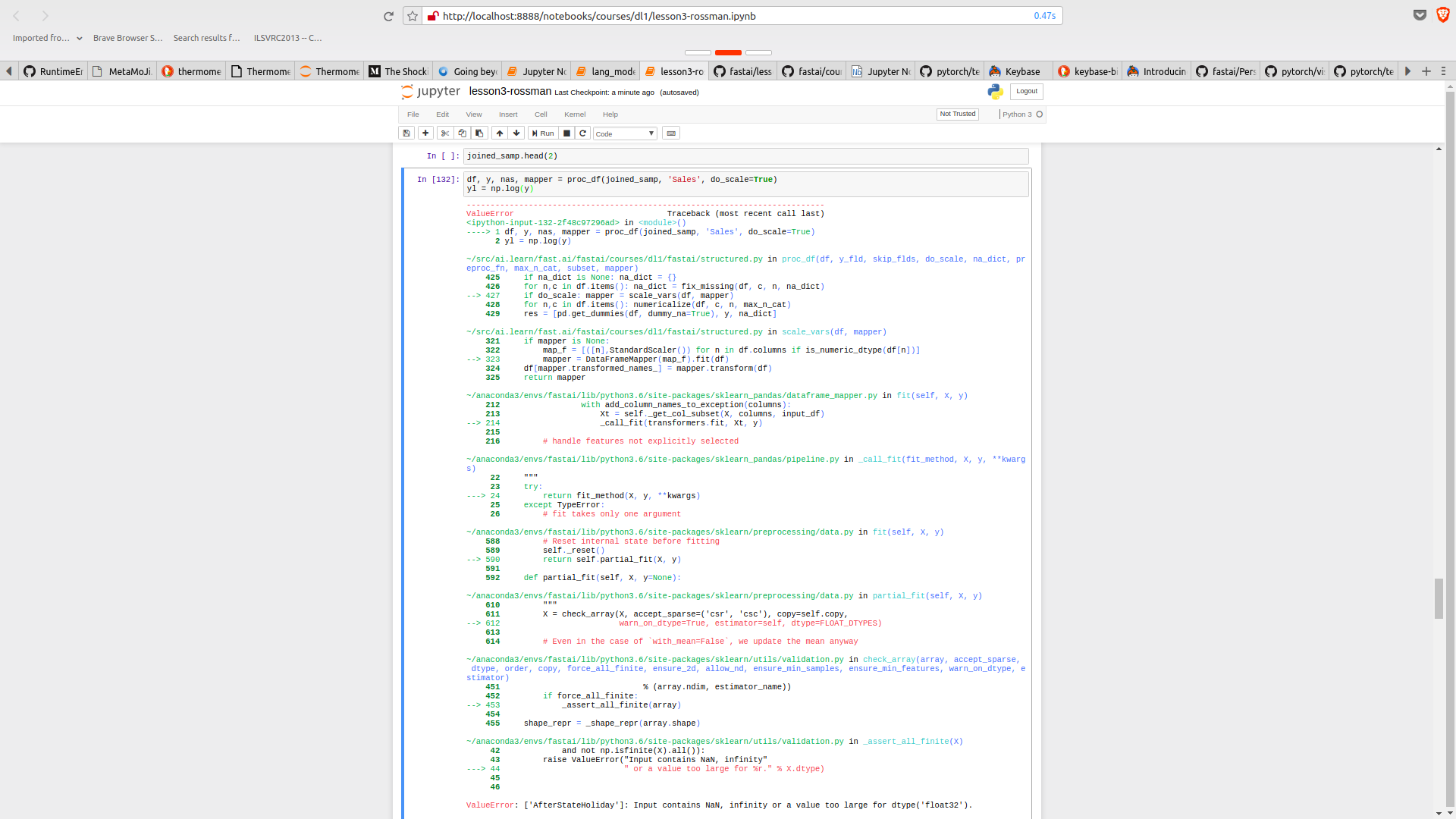
Looking futher into the issue, I think the code is more broken…
cat_sz = [(c, len(joined_samp[c].cat.categories)+1) for c in cat_vars]
[('Store', 1116),
('DayOfWeek', 8),
('Year', 4),
('Month', 13),
('Day', 32),
('StateHoliday', 3),
('CompetitionMonthsOpen', 26),
('Promo2Weeks', 27),
('StoreType', 5),
('Assortment', 4),
('PromoInterval', 4),
('CompetitionOpenSinceYear', 24),
('Promo2SinceYear', 9),
('State', 13),
('Week', 53),
('Events', 22),
('Promo_fw', 1),
('Promo_bw', 1),
('StateHoliday_fw', 1),
('StateHoliday_bw', 1),
('SchoolHoliday_fw', 1),
('SchoolHoliday_bw', 1)]
Thus, I think get_elapsed is just broken, particularly the line:
res.append(((d-last_date).astype('timedelta64[D]') / day1).astype(int))
Thanks!