In different small projects on image classification I encounter a similar problem: difficulty picking the correct learning rate. Currently I’m working on classification of about 10.000 images classified into 7 categories. The validation set contains 25% of the data. The architecture is resnet50.
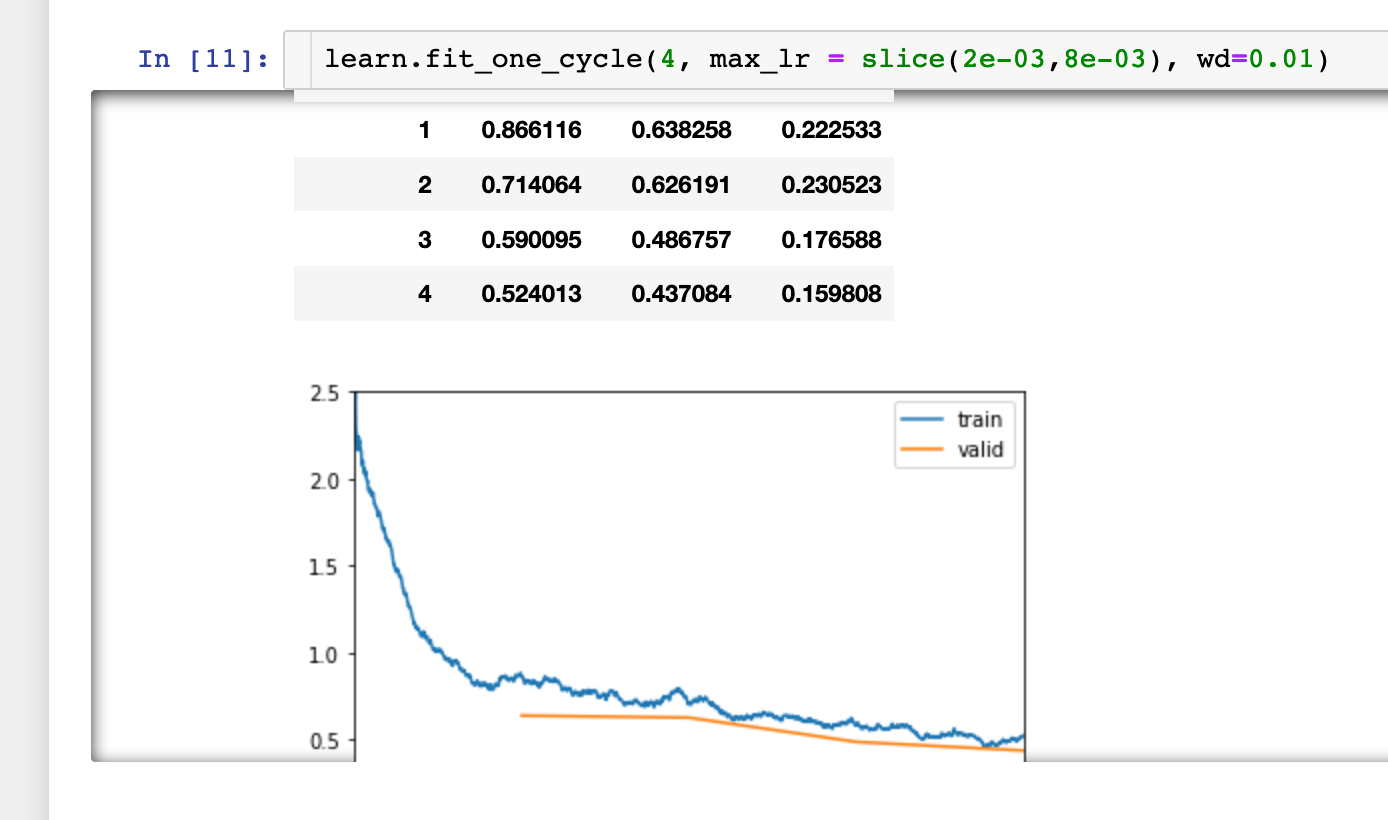
Initially I find a good learning rate (see picture for parameters):
In the second step there is a big gap with the validation loss, it seems to be underfitting. The training loss is not improving much. Is my learning rate too small?
what is the use of the lower limit in max_lr()=slice(x1, x2). In my understanding the slice defines limits for the max learning rate and ‘the software’ figures out the best one?
Sometimes it seems to perform better when I don’t use slice at all??
the second run of fit_one_cycle tends be more rough/unpredictable. I try to create a bump/initial increase in the loss by picking higher max_lr(), because this prevents setting in a local minimum with good effect. But sometimes the decline of the loss is doesn’t recover and the proccess ends around the same error rate.
Is it advised to use weigh decay in a resent50 CNN?
If anyone has advice about the questions above I’d like to learn more. Especially is an interaction between the number of epochs, max_lr and the cycle length which I didn’t grasp yet. Fit one cycle and max_lr induce an inital increase and the number of epochs determines how many times the data is evaluated? Is there a possibility to use multiple cycles as well to create a saw-tooth pattern for the learning rate over multiple epochs? Any other considerations for fit_one_cycle?
According to the results, it looks like you are underfitting as your train loss is greater than your validation loss.
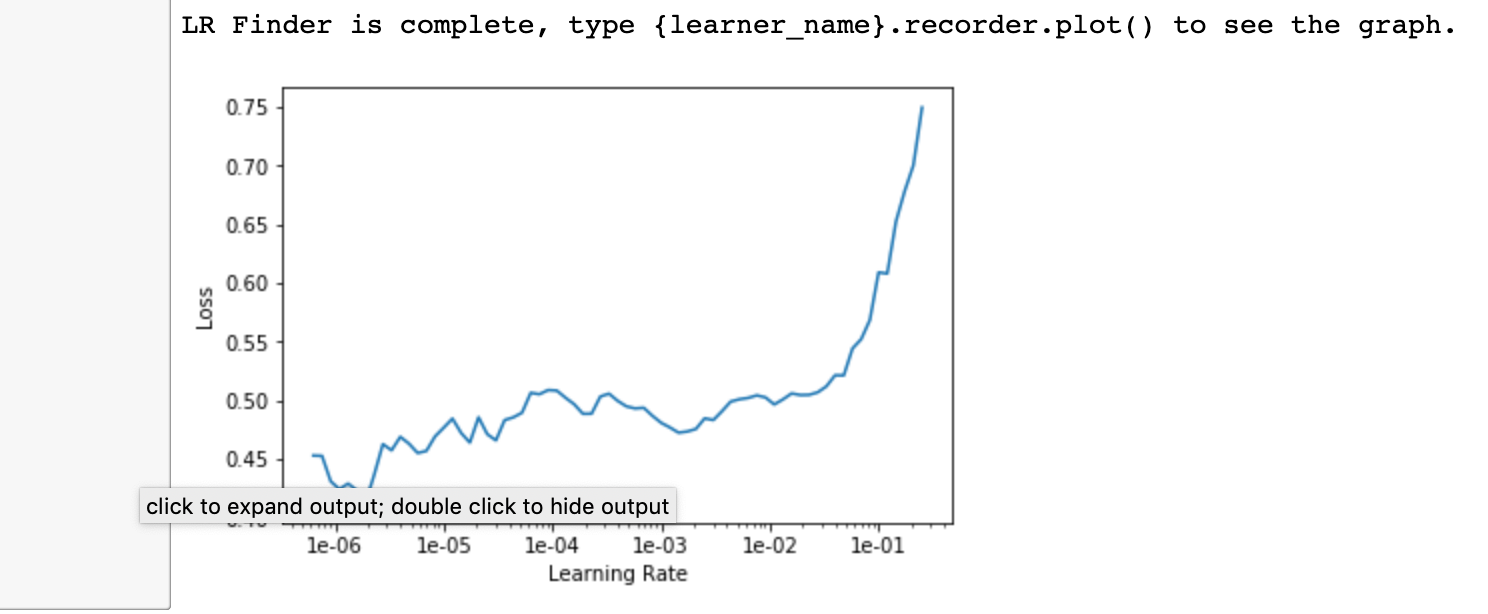
Also, I am not sure about the choice regarding the learning rates (LR), they look very low compared to what I have seen throughout the first lessons. With the x-axis cut off in some charts, it’s hard to tell if those LR were the best ones.
I would try running the model with the default settings with the LR at 3e-3 (I think that’s what it is set at), then make some plots and fine-tune the LR with lr_find()
Also, check out Jeremy’s methodology in Lesson 3 notebooks (here is the link to the notes).
Concerning max_lr=slice(start, end), I think it means something like, train the first layers with a LR of start; the last layers at a LR of end; and for the remaining layers, spread the LR across the range (start, end).
Hey thanks.
Yes, usually I use a larger learning rate as well. This one gave a better result now.
If it is underfitting I would expect more improvement of the training loss with more epochs?
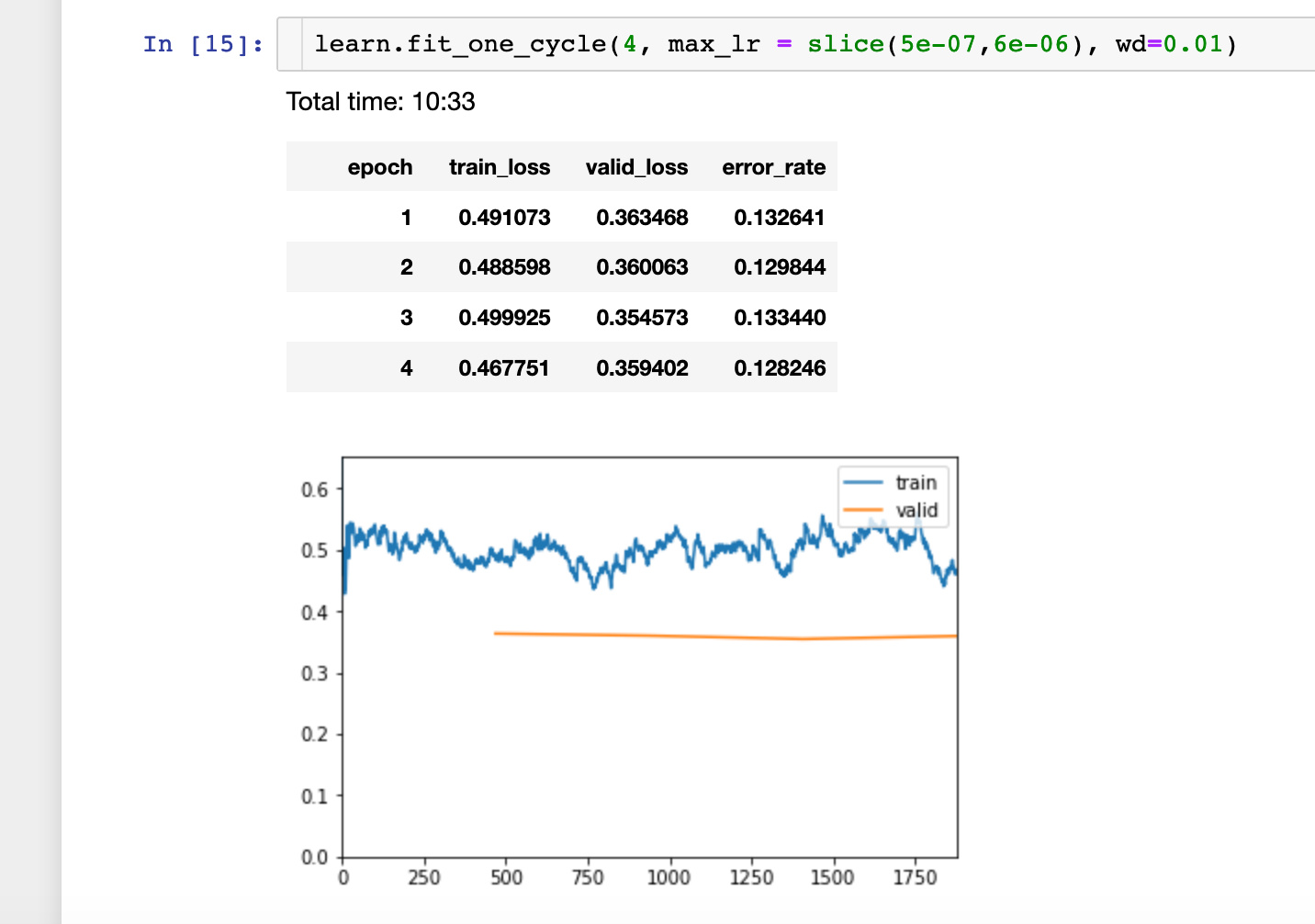
I was surprised by the improved validation loss of this lower learning rate.
Something similar like you explain about limits for the learning rate I assumed. I don’t have a clue about how to choose the lower bound for the learning rate, to train the first layers. With unfreeze() it should be even smaller?
 ,
,
