The problem
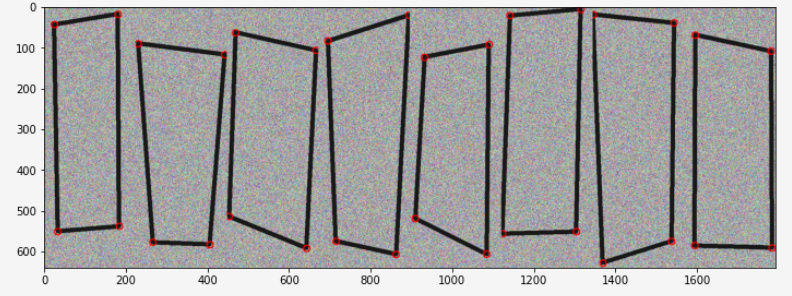
Given a fairly well bounded image of a quadrilateral object, detect the corners/permeter of the object. I wasn’t getting any results with my real data so as an easier, toy problem I decided to try and get some results with synthetic data like below. This a batch of 8 examples from my easy synthetic training set. The small red circles show the data labels.
Approach attempted
I managed to get “ok” results for this synthetic dataset this by treating the problem as one of linear regression to the corners. So I generate a set of 4 anchor points - the average positions of the four corners of objects in the dataset, adapt resnet to predict 8 values:
resnet50 = torchvision.models.resnet50(pretrained=True)
resnet50.fc = nn.Linear(in_features=2048, out_features=8, bias=True)
and interpret those 8 values as 4 (x, y) offsets from the anchor points (normalised to the range: 0.0 to 1.0 wrt. width and height of image) I use MSELoss with the 8 ground-truth corner coordinates (also expressed as normalised offsets from the same anchors)
Baseline model
For the purposes of comparison I have written a function that simply returns a tensor of zeros (ie. a prediction of zero deviation from the anchor points) I refer to this function as the baseline model
results so far
resnet is able to outperform the baseline model on the synthetic data, although not as accurately as I would have hoped. eg. the predictions below. ( Although I’m sure I could get something a bit better if I spent a while tuning the hyperparameters)
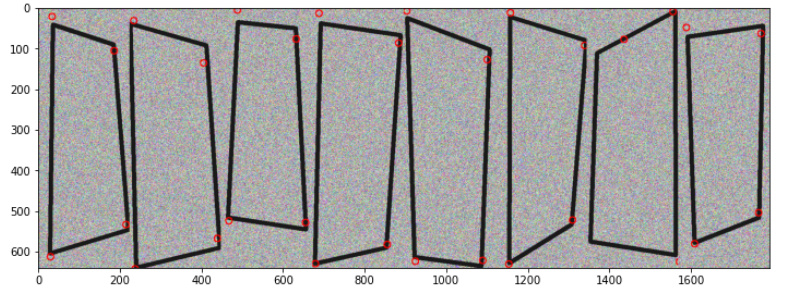
However, resnet can’t even match the baseline model when training on the real data. I can’t get it to overfit or even match the baseline model when making predictions on the training data after training
I tried a few other models like mnasnet and mobilenetv2 and found that they couldn’t beat baseline, even on the synethic dataset. I also tried adding a tanh layer after the linear layer like net = nn.Sequential(resnet50, nn.Tanh()) to map all the outputs to -1 -> +1 but found that this stopped the model being able to beat baseline on synthetic data too.
Any advice on this problem would be great - am I framing the problem well? Am I missing a trick on the DNN output?
Here is a colab upload of the notebook I’m using to experiment with the synthetic data
This is an example of the real data I wish to be able to learn to detect. Of course I know that canny edge detection is a thing, I’m hoping to be able to ultimately find a DNN solution that can cope with very varied lighting conditions and hopefully learn to exploit higher level semantic information that simple conventional CV could not.

UPDATE:
OK with large batches and many epochs of training on a big GPU I am now able to beat the baseline on real data. it’s still not doing that good though - would still really appreciate thoughts/feedback on how I can improve my overall approach.
UPDATE UPDATE:
ok - I’m actually getting good results with this same basic approach using efficientnet-B3 yogi/lookahead optimiser and training for > 1000 epochs with batch sizes of 20. I’ve never had to train something for more than a hundred epochs before for convergence - but this is a relatively small dataset (training set is around 1300 unique images) with a bunch of augmentation built in.