Hi,
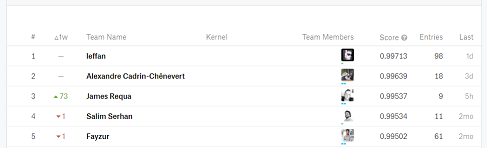
I’m participating in this competition: https://www.kaggle.com/c/invasive-species-monitoring and I cannot get past ~0.964 score. I ran out of ideas, I even recreated my validation set twice.
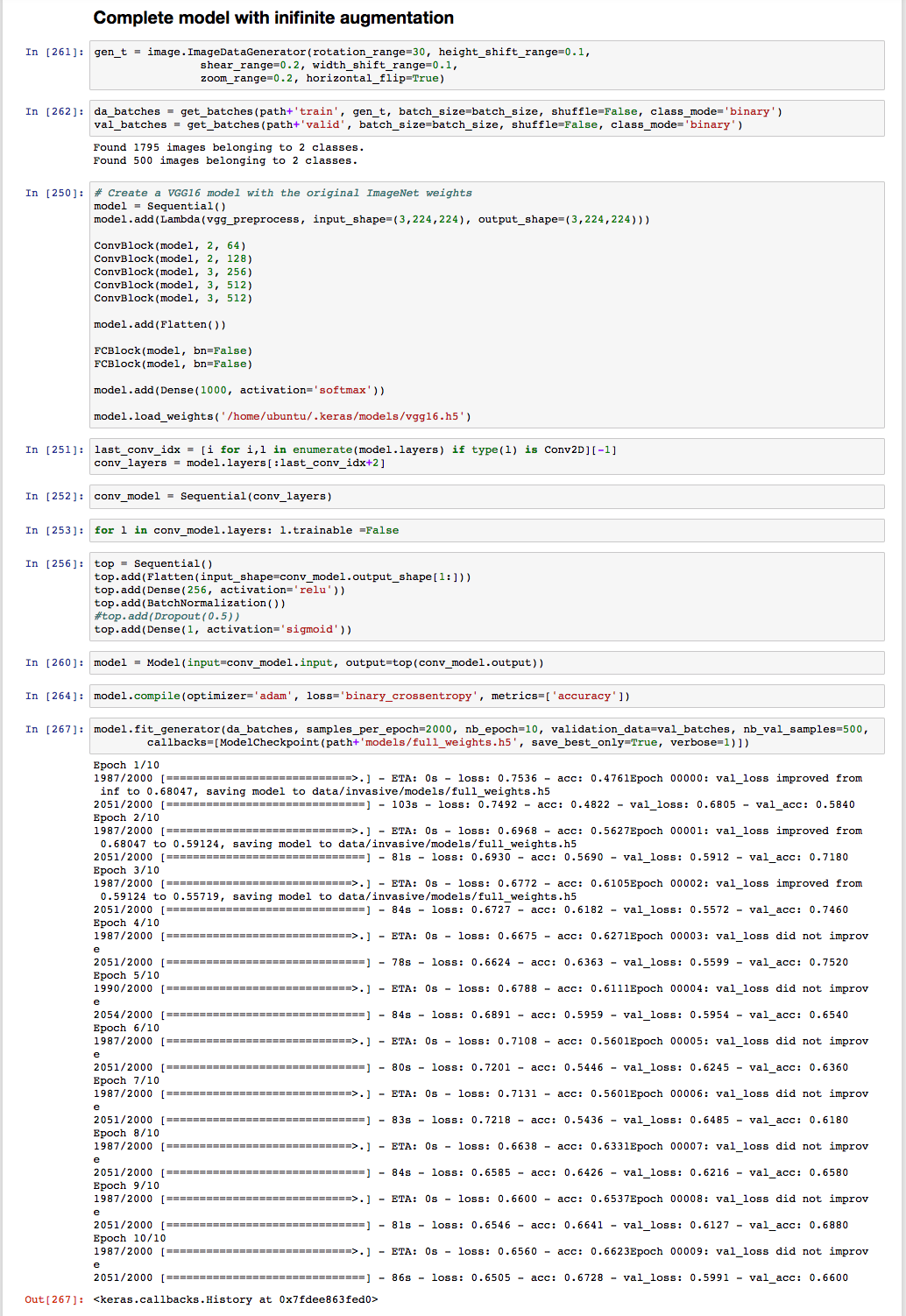
I’m using these augmentation parameters:
rotation_range=30, height_shift_range=0.05, shear_range=0.1, width_shift_range=0.05, zoom_range=0.05, horizontal_flip=True (I also tried width and height shift of 0.1 and a rotation range of 0.1)
I tried creating an augmented set 4x, 5x and 6x the size of the original training set.
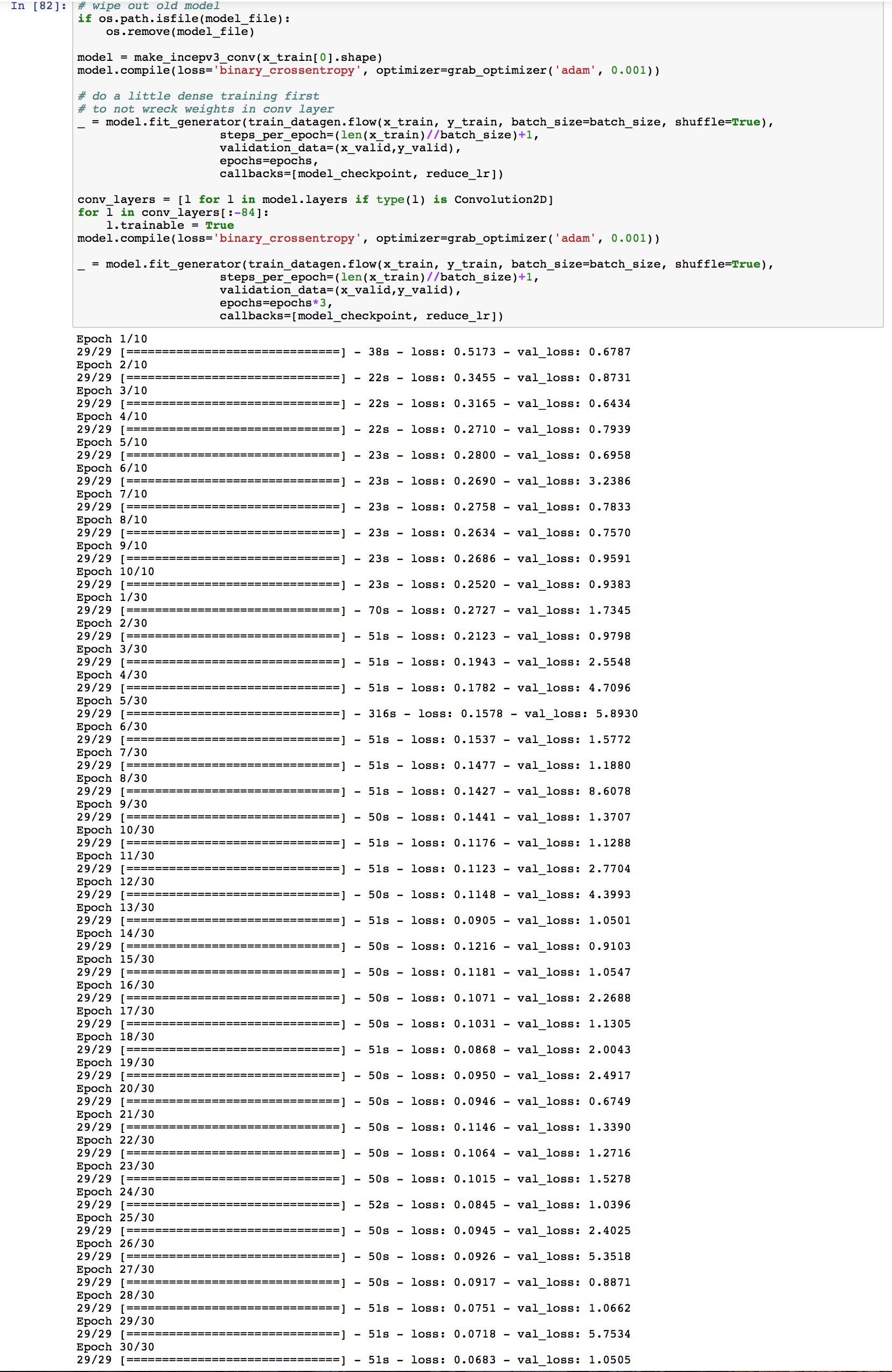
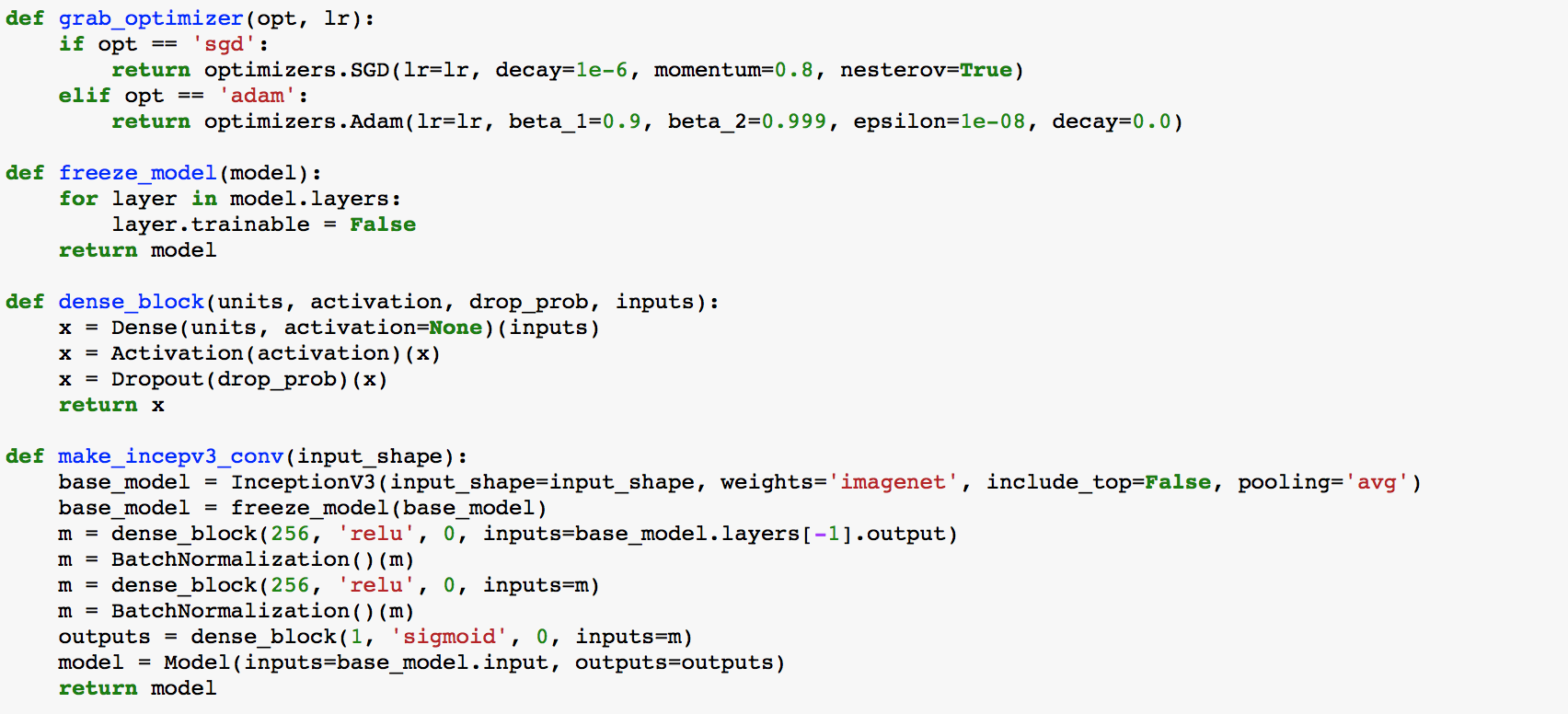
I’m using VGG16 convolution model for obtaining the bottleneck features. As for the top model, I tried finetuning the VGG16 model with BatchNorm, I also tried simpler model architectures such as 2x 256 + BatchNorm + Dropout 0.5-0.7; 2x 512 + BN + DO and also single layers of 256. In all cases including the output layer, which does not change.
I also tried two types of last output layer:
Dense(2, activation='softmax') and Dense(1, activation='sigmoid') even though I believe this does not affect anything and should be identical (please correct me if I’m wrong).
As for optimizers, I tried mostly Adam, but experimented with Nesterov SGD and RMSprop as well.
I tried model ensembles.
The “best” so far was 2x 256 + output layer with Adam and learning rate of 1e-4. But it’s still not good enough…
Every time I tested the validation accuracy using the sklearn’s roc_auc_score, but I found there’s very little correlation between my validation roc score and the score I achieve with the final dataset.
Could you please advise on what I may be doing wrong, i.e. how can I improve the results? I’ve been fiddling with this dataset for over 6 weeks now and I’m frustrated that the results are not improving… Thank you in advance.