For example, imagine your task is to differentiate between American Labrador Retrievers and English labs.
What can we do to improve the abilities of our classifier given that they are very very similar. I’ve tried running through a dataset like this and can’t get the classifier to do better than a coin flip.
I don’t think there’s any special approaches in this case. If you can provide more details about the dataset you’re using, and what you’ve tried, we can try to give specific recommendations.
This may sound kind of lame, but I’m trying to build a classifier that can distinguish between In-N-Out burgers and other burgers.
I have about 400 pictures of In-N-Out burgers and almost 2,000 images of other burgers. Most of the images are pretty big.
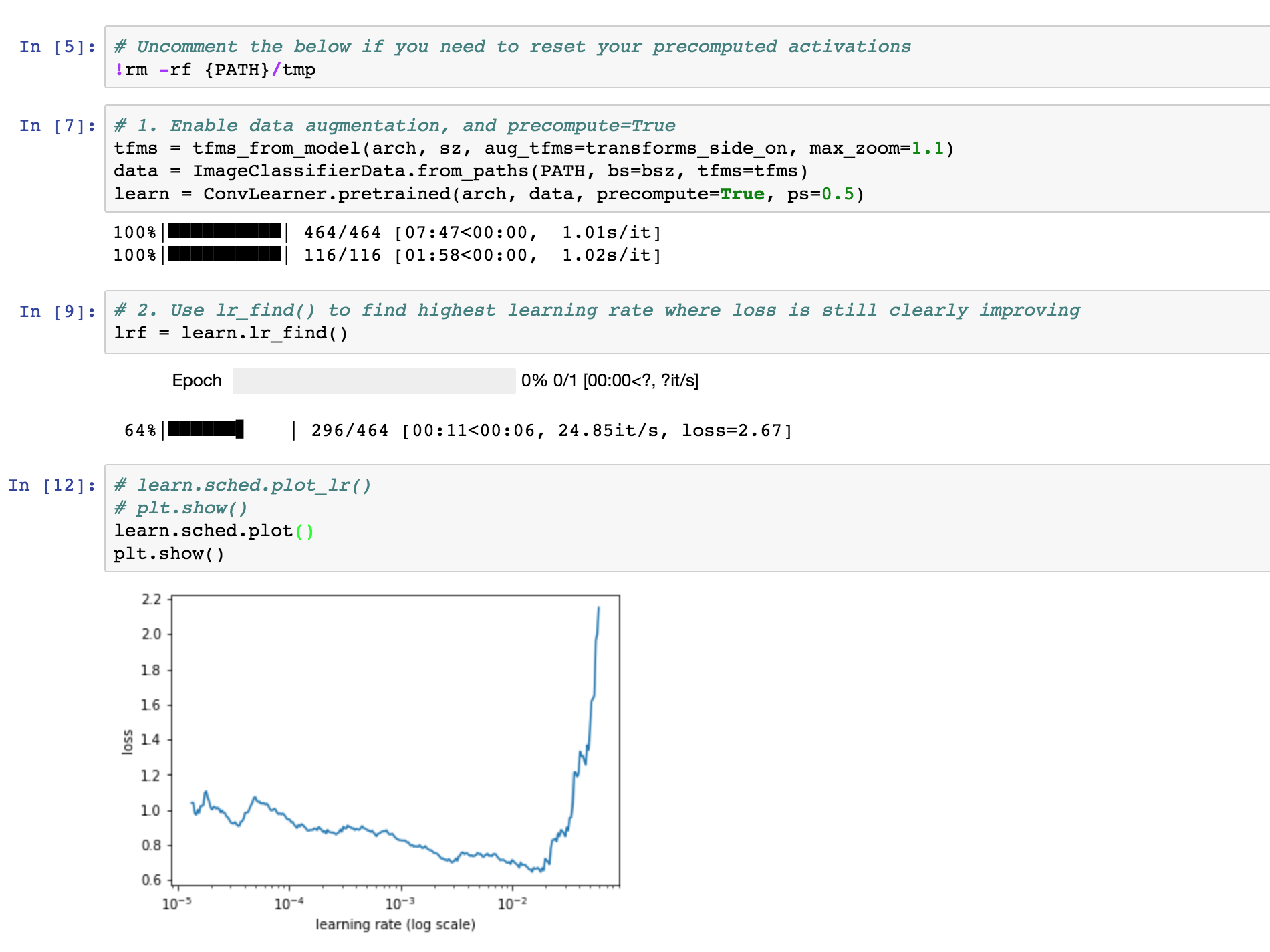
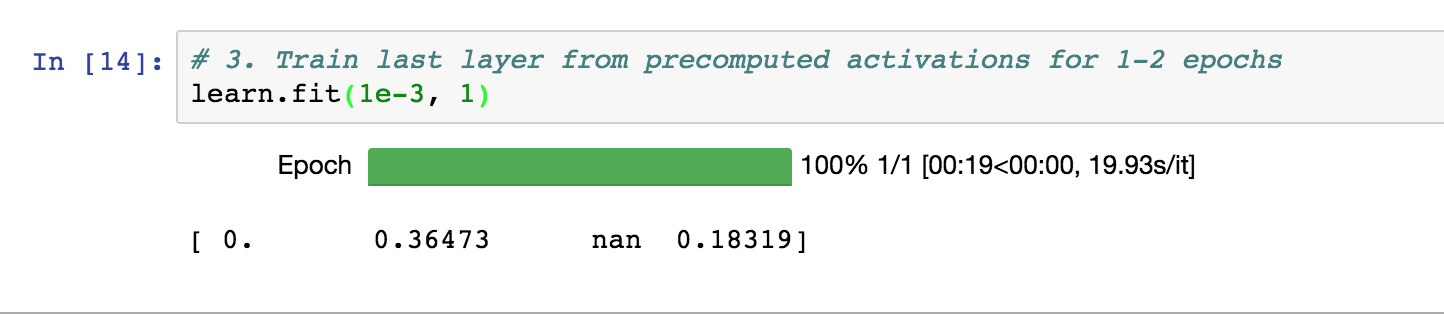
So far, I’ve tried basically using the lesson 1 approach on the dataset. I’m only getting about .18 accuracy and my validation loss is NaN (which can’t be good).
Sounds kinda awesome to me. Not that I like In-N-Out burgers myself - can’t understand the attraction…
Anyhoo if you’re getting NaN loss something is very wrong. I’d guess a too large learning rate. If you show a screenshot of the training process we’d be able to tell more.
The CPU code is new and I haven’t looked at it. Worth trying on a GPU. Also worth trying a very small learning rate. Need to figure out where that NaN is coming from…
Nah they’re really not. And the fries are always drier than any fry deserves to be. Sorry @wgpubs I can see you feel strongly about this, but I just can’t avoid blasphemy.