Many thanks for the update @dillon . It’s great to know that you’re working on it.
BTW pytorch 0.3 is about to come out. It has a massive improvement in group convolution speed, so you’ll definitely want to include it when you can!
Many thanks for the update @dillon . It’s great to know that you’re working on it.
BTW pytorch 0.3 is about to come out. It has a massive improvement in group convolution speed, so you’ll definitely want to include it when you can!
OK, so I spent the last few days building out different versions of the template with different drivers/ base OS/etc.
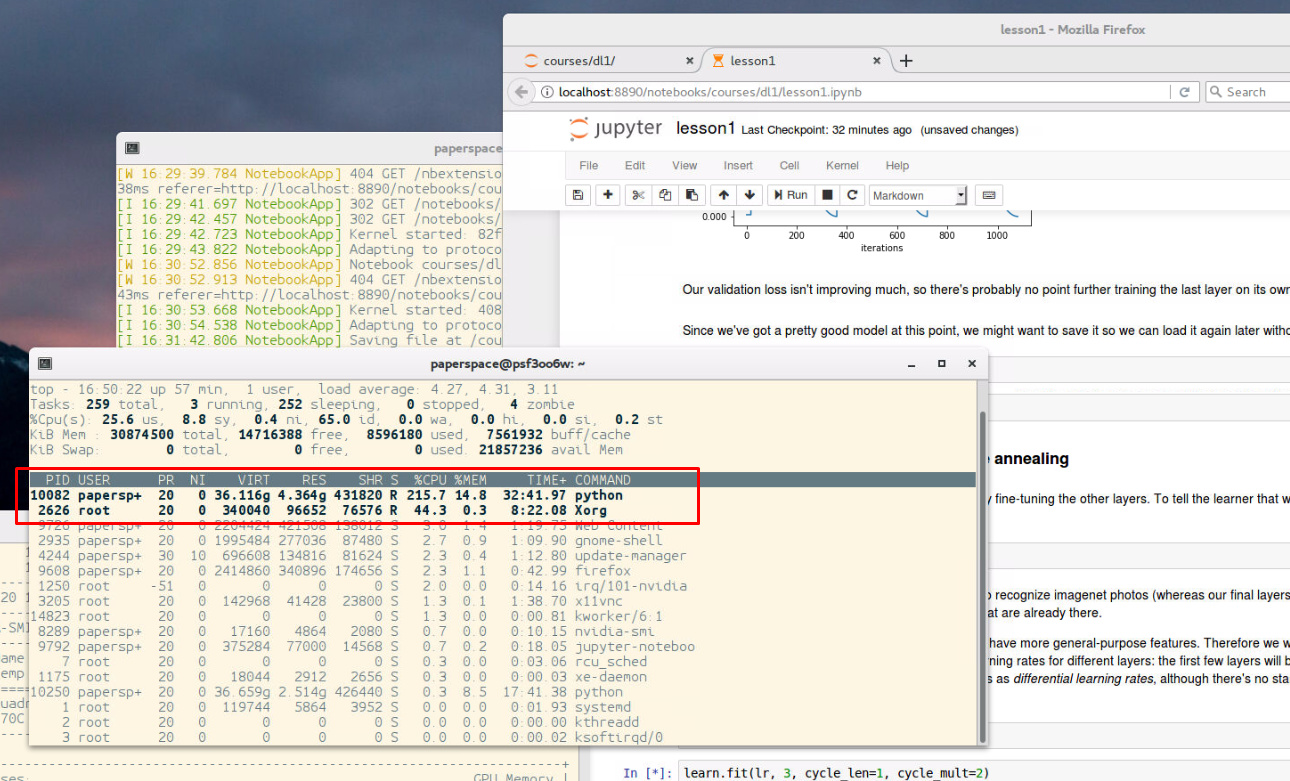
dlopen: cannot load any more object with static TLS error only occurs on Ubuntu 14.04 and when I switched to a Ubuntu 16.04 template that issue went away entirely.learn.fit() consistently just as you mentioned. What I notice is that the CPU is getting hit really hard so I’m going to have to dig in to what this method is doing. From the outside it almost looks to me like there is a memory leak in the method. Virtual memory use explodes as CPU starts to really heat up.@jeremy just as you mentioned it eventually works but something doesn’t look right and it can take 5 minutes to get going. This is on a brand new Ubuntu 16.04 template where I installed new drivers, fresh Conda install, etc.
If anyone is interested in helping debug I am happy to share my new instance 
Sure. I can give it a try. Most likely later in the evening today. I am not using Paperspace at the moment, but used it in the past and will most likely return to it after a few months. So ping me if I can help.
@dillon I was seeing freezes on constructing learn, not on fitting. It might be worth doing a git pull and trying again, because I switched from ProcessPool to ThreadPool last night so if it was a multiprocessing issue this might well fix it.
We’re not seeing the problem on any other platform BTW, so it’s something specific to your config. Are you using docker? There are various threads around about docker and pytorch IIRC…
Is this problem specific to paperspace V100 GPUs?
I have been able to successfully run my planet classification code on a p2.xlarge instance. However, when I run in on a p3.xlarge instance - Volta V100 GPU, I get this problem. The kernel just freezes. The GPU memory is allocated however the code doesn’t get executed.
Upon further investigation, it freezes at construction of learner object.
The same code works smoothly on a p2.xlarge instance though. Any thoughts on this?
Damn! It works now on V100 GPU.
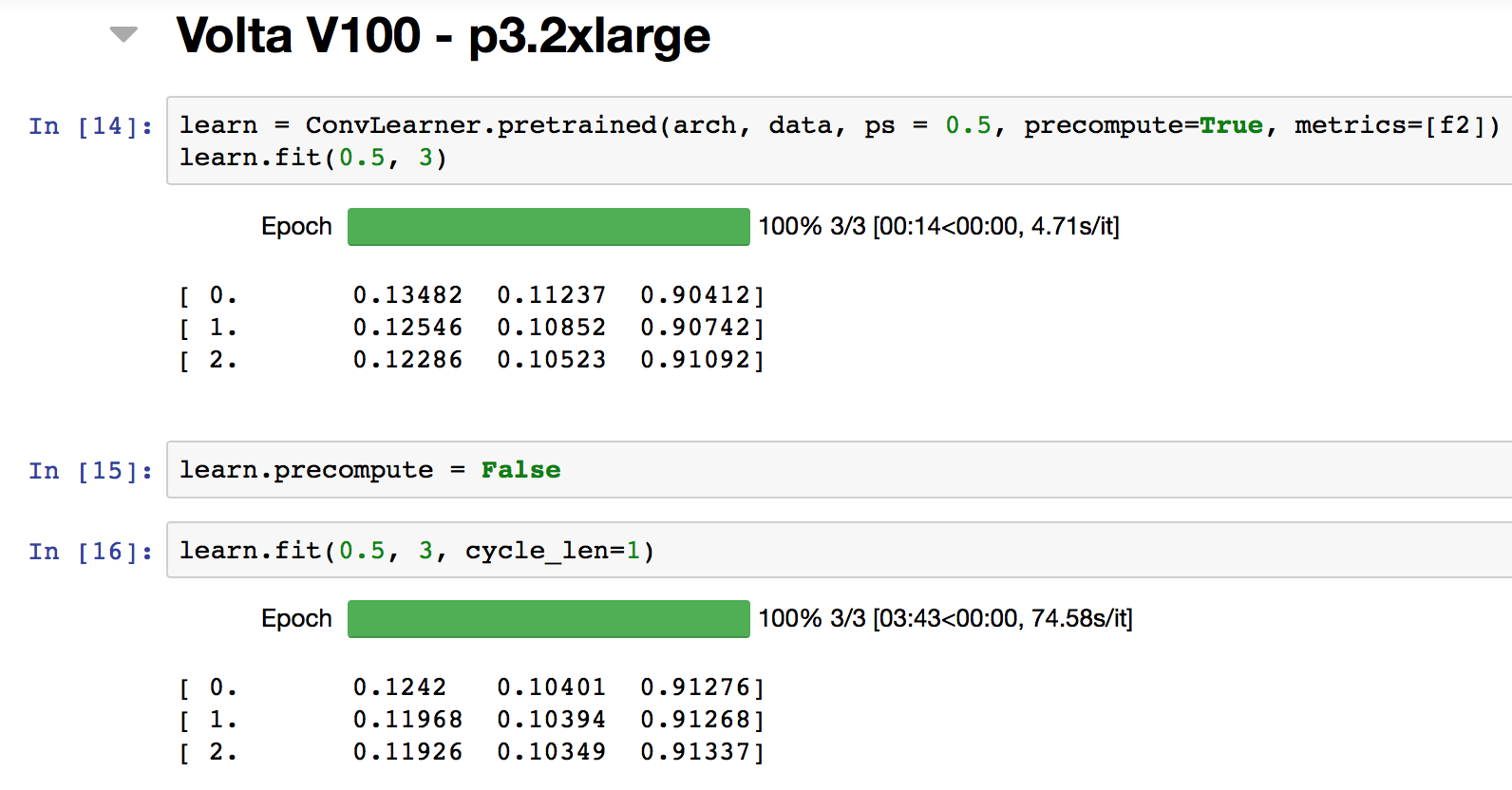
Some points to note:
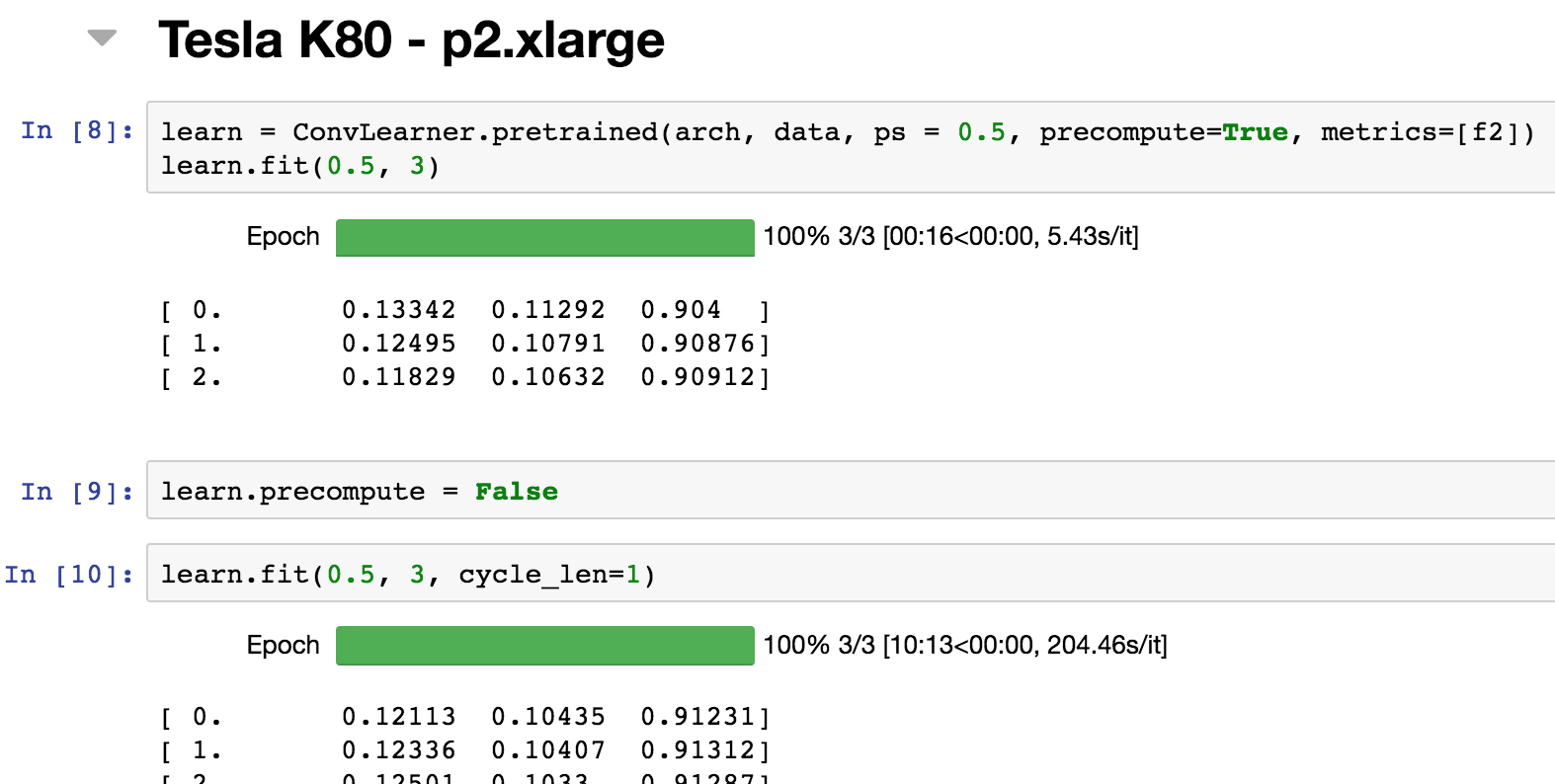
When I set precompute=True, the speed improvement for 1 epoch on V100 is around 13%.
When I set precompute=False, the speed improvement for 1 epoch on V100 is around 63%.
Attached screenshots for reference.
Give this a try? - http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/optimize_gpu.html
I have not tried them, so take a image before changing the settings.
Here’s my very unscientific explanation for this - Looks like this may be issue with PyTorch 0.2 with Cuda 9 and V100 Machines take advantage (requires) Cuda 9?
Pytorch 0.3 Release checklist has Cuda 9 and Cuda8 support -
Hopefully it should be available in next few weeks and wait until then to use V100 (P3) and even paperspace?
Alternatively, in this Doc from NVidia, they reference couple of pull requests to make PyTorch compatible with Cuda 9.
Ok, I tried doing this on both the p2 and p3 instances. Unfortunately, I did not observe any significant changes in runtime / epoch. The difference was less than 5s/it. 
some typos in the code
fastai/courses/dl1/fastai/torch_imports.py", line 21
def children(m): return m if isinstance(m, (list, tuple)) else
^
SyntaxError: invalid syntax
Don’t want to be a bore @dillon but has any progress been made in PaperSpace?
(It is quite a few days already that I stopped my daily logging in to Paperspace + trying to make fast-ai work… but have not lost hope  )
)
With pytorch 0.3 installed from source my problems on V100 went away. Maybe will help paperspace too?
Hi guys,
Apologies for the radio silence. We are still debugging this issue and I should have an update later today. Long story short this bug is much trickier to reproduce than we had originally thought.
Stay tuned!
Dillon
I signed up last week to help Dillon, but didn’t really get much time over the weekend. Hope to spend sometime later in the evening, but hoping Dillon and his team will figure it out before that 
OK, so on @jeremy’s recommendation I rebuilt everything with Pytorch 0.3.0 and also master branch of Pytorch and the bug disappears. We were running out of ideas as we had tested every GPU/driver/CUDA combination and even built dockerfiles to debug.
We will do a bit more testing here and then upgrade the Paperspace Fast.ai template to use the newer version of Pytorch.
@jeremy is there any reason we should not upgrade pytorch for the class?
No that would be great. There’s a deprecation warning that’ll appear due to a change in softmax - I’ll work on removing it. Excited to be able to show paperspace to our students!
Perfect! I’ll go ahead and make the changes. For reference I have added the docker containers I was testing here:
in case anyone else finds it useful.
OK guys we updated the Fast.ai template to specifically work with current Pytorch-based course. This template is based on Ubuntu 16.04, uses Pytorch 0.3, and has a few other improvements. Would love any feedback!

Thats great news! @dillon, is there anything we should do in our machines to load the new template or it should just work “out of the box”, silently replacing the old template?
Deleting the old one and it’s storage …??
And then re create another one?