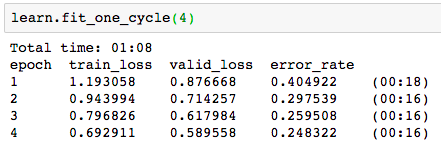
I’ve done multiple passes to fine tune my model and reduce the error rates (currently quite high) by doing two things:
adjusting learning rate using the plot and passing different ranges to slice
cleaning up data using the filedeleter widget
Through the 2-3 passes of this I was able to see a lower rate (relatively speaking) but then by the end error rate was again back to where I started. Any tips on what I’m doing wrong?
Some questions and info from my side:
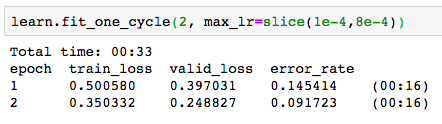
My most recent iteration actually resulted in error going down and then up:
My question is, does this imply overfitting? Even at this stage?
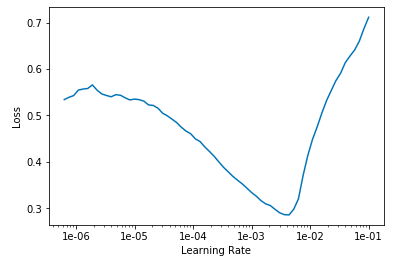
The lr plot for this run is:
The lowest loss actually occurs closer to 1e-2. I recall Jeremy saying default is 1e-3 and we should pick a rate 10 less than default. I’m wondering if that applies here? What should be the range I pass to slice in such a plot?
I reran the model at this stage for 2 epochs and my error rate fell to 0.38 (still high, i know). but then i ran it again setting epoch to 3 (hoping to improve the error rate) and this time my error rate shows signs of over-fitting (went down and then up). My question is - am I interpreting this correctly? Is this really a sign of over fitting?
I have more questions, but I’ll post this for now.
PS: feature enhancement request: the filedeleter currently does not give the label names for the files/images being chose under top losses. can we add that, so we can better assess if its really a “bad” data point or just an interpretation error by a poorly trained model.
How many images are you using to train/validation? There’s a great paper by Leslie Smith explaining how to set the hyper-parameters and how to understand if the model is underfitting or overfitting.
I started with 3 classes, 70 images each, valid_pct of 0.2. So had about 42 in the validation set and around 130 in the training set (I think I lost some from training set due to read errors on some images).
At this point, all terms like hyper-parameters, momentum and weight decay etc are latin to me! I’m still learning about learning rate… but thanks for the paper link… will try to process!
No, you are not. Note that valid loss is still decreasing nicely, and is of the same order of magnitude of tr loss.
Try and run more epochs. Much more. Then report back.
Looking at your plot, I’d pick something like 2*10^-4. You tell me why.
Let yourself be guided by losses as you judge whether your model is overfitting.
However you situation is typical of going inside a minimum and then jumping out of it. It’s not necessarily bad: you could end up in a better minimum, particularly if you are using restarts.
Save the paper for later then, after a few more weeks will start to make sense
Have you tried to unfreeze and train for a few more epochs to see if it improves? And also, use the ClassificationInterpretation to try to understand the wrong predictions. Are they obviously wrong for a human?
On the maxLR value of 210^-4 => is it because after that point loss steadily falls for a while? No local peaks and troughs, at least until 310^-3.
What did you mean by “using restarts”?
Clarification on the filedeleter: currently when it pops up the images to be deleted, it doesn’t specify which label/class they belong to. In my case (working on predicting human emotions) having this will help me identify if the image is obviously wrong to the human eye or not, as @mnpinto enquired. Hope this helps.
You can modify the FileDeleter code ever so slightly to display the labels if your data is organized with one directory for each class. Here is a quick hack:
copy and paste the source code of FileDeleter to a new cell (type ??FileDeleter, and copy the source)
Go near the end of the code, in the method ‘render’, and change the following line:
delete_btn = self.make_button(‘Delete’, file_path=fp, handler=self.on_delete)
This is not a recommended way to modify the FileDeleter, because you’re assuming that the input data is organized in a certain way; but if that’s the way your data is organized, then it should work fine. (I noticed that the source code of FileDeleter is changing, so there might soon be a better way to display the classes).
Interesting application! There’re works on that topic, maybe you can find which databases they used and if they are publicly available try to train your model on them and compare the results. And then you can fine-tune on your dataset and the results should improve.
If your images are large you can try progressive resizing (i.e. train the model with image size 64x64, then on top of that 128x128, 256, 512) it can help to improve the results.
Fastai tries (if you tell it so) to get out of (bad) local minima by resetting the learning rate to its highest value, according to the guidelines provided by Leslie Smith in its paper “Cyclical Learning Rates”.
The hyperparameters just are all the non-trainable parameters of your model. Forget about WD and momentum for now, Jeremy will explain them in due course.
Try not to get overwhelmed by technical terms.
Thanks @balnazzar@mnpinto for the inputs! I have updates. And more questions.
Instead of training on the Google images, I got the KDEF dataset and trained the model on that. The first stage results already show marked improvements:
Did some fine tuning of the learning rates and was able to bring down the error rate to 9%!!
Tbh, I am scared to touch this model now!!
However, I still have my Google dataset. So now I want to see the error rates when I pass this data via my trained model. I’m looking at lesson2 notebooks for the prediction part but I can’t figure it out. Do I need to run predict in a loop and review each output separately? Is there an easier way to run a new dataset through a trained model and see the results?
I didn’t quite understand what exactly you want to do, however:
If you are afraid of making your model worse, save the weights (learn.save).
If you want to keep training your model on the other dataset, save the weights, instantiate a new learner with the other dataset, load the weights, and keep training on.
If you want to predict against a single img, do (more or less) what follows:
img = open_image('/path/to/your_image.jpg')
losses = img.predict(learn) # learn is your learner
prediction = learn.data.classes[losses.argmax()]
print(prediction)
I want to use my trained model to determine how accurate a Google image search for “human face angry” really is!
So, I don’t want to further train my model using this dataset. But assume my model is accurate and pass in the top 100 results of a search and see how my model classifies them.
If you want to run predictions for multiple images at once you can put tem in a test folder and give the folder path to ImageDataBunch (if you are organizing the images in folders and using the method from_folder). Then you just call learn.get_preds(is_test=True) to get the predictions for all images in test folder (after training the model or loading previously saved weights).


 but thanks for the paper link… will try to process!
but thanks for the paper link… will try to process!