I’m trying to improve the collaborating filter presented in the class by adding an embedding layer that will factor in the year of the movie.
The dataloaders (defined as ds) doesn’t include this data, it only stores items,ratings and movies.
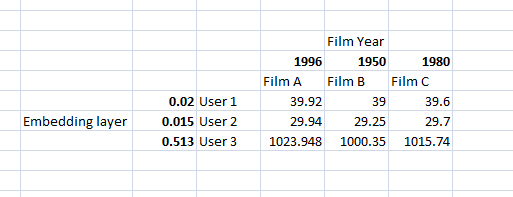
Here’s an example in Excel of what I intend to do:
Let me know if you have an idea how this could be achieved.
Here’s the code I’m using, the part I don’t understand is highlighted as pseucode:
#Loading data
ratings = pd.read_csv(path/'u.data',delimiter='\t', header = None , names=['user','movie','rating','timestamp'])
movies = pd.read_csv(path/'u.item',delimiter='|', encoding='latin-1', usecols=(0,1), names=['movie','title'],header=None)
ratings = ratings.merge(movies)
#adding the year of the movie to the DataFrame
ratings['year'] = ratings.title.apply(lambda x: int(x[re.search(r'(\d\d\d\d)', x).start():re.search(r'(\d\d\d\d)', x).start()+4]) if bool(re.search(r'(\d\d\d\d)', x)) else 1990)
#into dataloaders
dls = CollabDataLoaders.from_df(ratings, item_name='title', bs=64)
class DotProductBias(Module):#created for the entire dataset
def __init__(self,n_users, n_movies,n_factors, y_range=(0.5,5.5)):
self.user_year_factors = Embedding(n_movies,1)
def forward(self,x): #This runs per batch
#I'd like to do is define the following:
#user_year_factors = self.user_year_factors(x[:,0])
#**Now I want to get the tensor with corresponding year of film for corresponding batch**
#how do I do that??? Here's a pseocode of what I mean: film_year = dls.movie.year[x[:,0]]
return sigmoid(user_year_factors*film_year)