I’ve been very impressed by the trick on Lesson 7, saying that one could add as output the coordinates of the bounding box in order to perform localization as well as classification.
There’s one limit I think I came with, unless you have a solution to this.
Suppose there are two fishes on the picture - the model will output only one set of coordinates right ? Because it trained on 1 picture - 1 bounding box configuration, there’s no way to make him output 2 different bounding boxes, right ?
Probably a nice way to overcome this is to use the full convolutional layer and watch for these heatmaps. In that case we’d have a spatial “probability” distribution making it possible to spot multiple highly probables candidates…
So I first sticked to your course case, using full convolutional network.
My dataset consists in images of racing cars (all are the same model, but they can be decorated differently). 800 pictures for 17 classes, and using your full convolutional network, 94% classification accuracy reached easily. And the localization trick works neatly !
But for now, when there are multiple cars it doesn’t look for a car but the class car. It is… too precise. So I’ve thought of 3 solutions :
Training a full convolutional network with a binary task : picture with car(s) VS picture without car. Using the heatmap trick that would act as a car localizer (and could thus handle multiple cars).
Maybe I could check the inputs of less deep convolutional layers and maybe one is actually already doing the simple car detection…
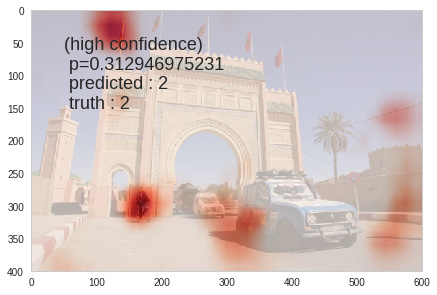
Actually checked that on a picture where there are 2 cars, but doesn’t seem like working
Convo Layer n-1
Convo Layer n-2
Maybe doing an average of output from the last convolution layer filters for all classes could yield me some “this looks like a combination of all the already existing cars although it’s not one of them”
Did try this also. Doesn’t work all the time, but cases appear where it works :
Here it doesn’t find the one behind …
Supposing the localization works, using that same training data, I’d slice car parts. Do you think there could be some unsupervised classification (clustering) at that point ? In order to find car classes “by itself”… Something like PCA + k-means I don’t know.
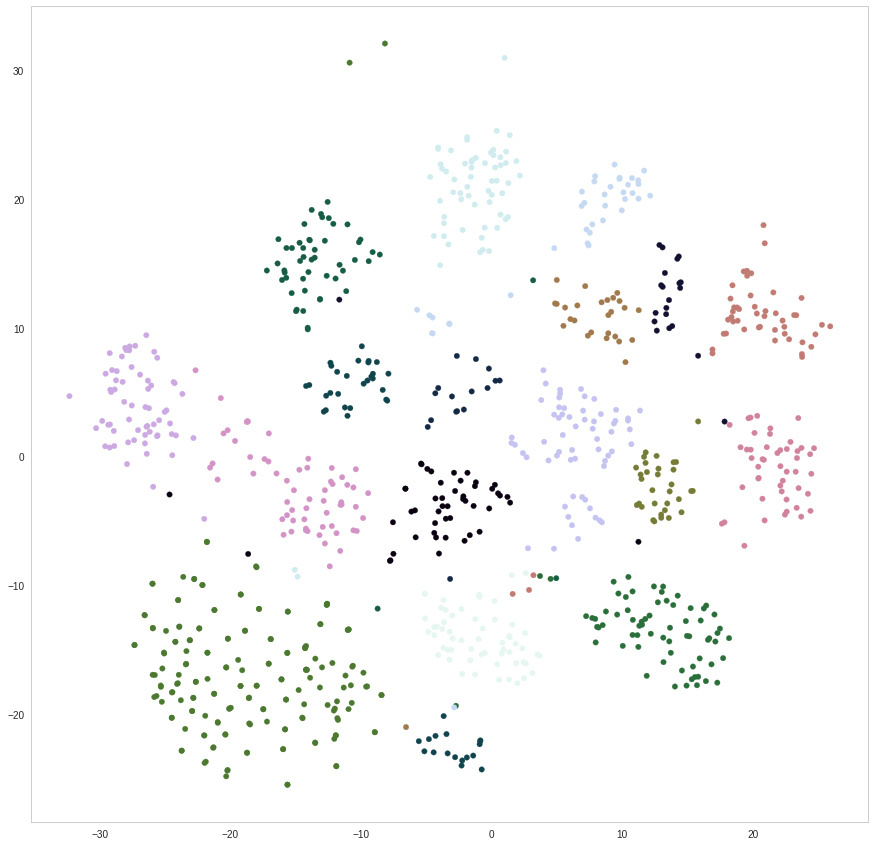
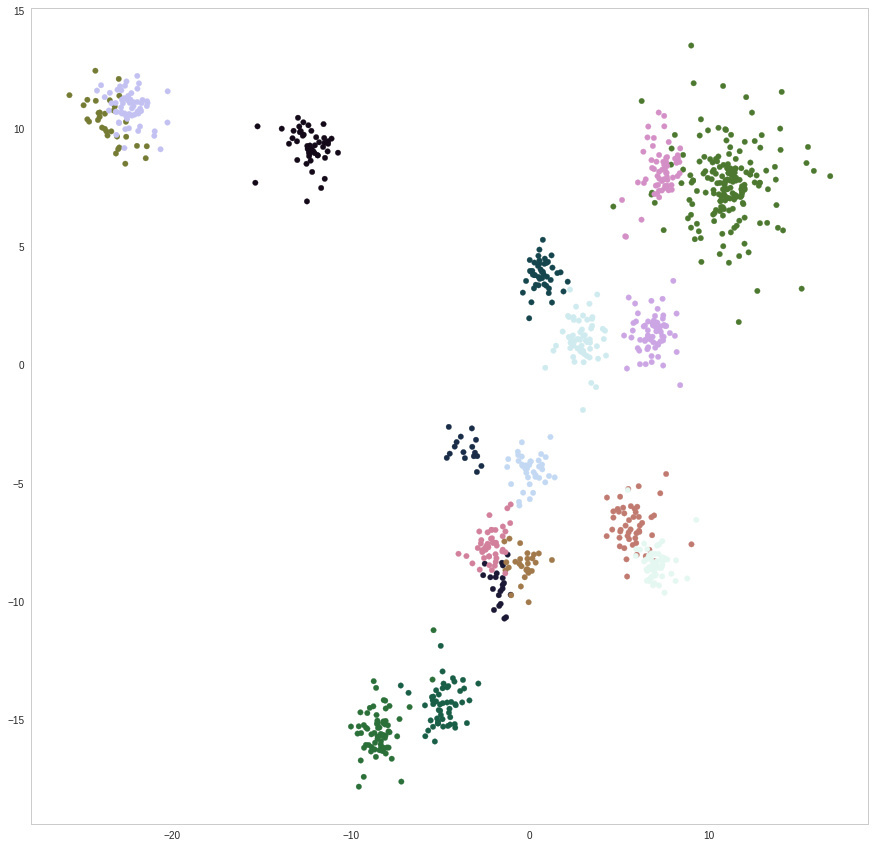
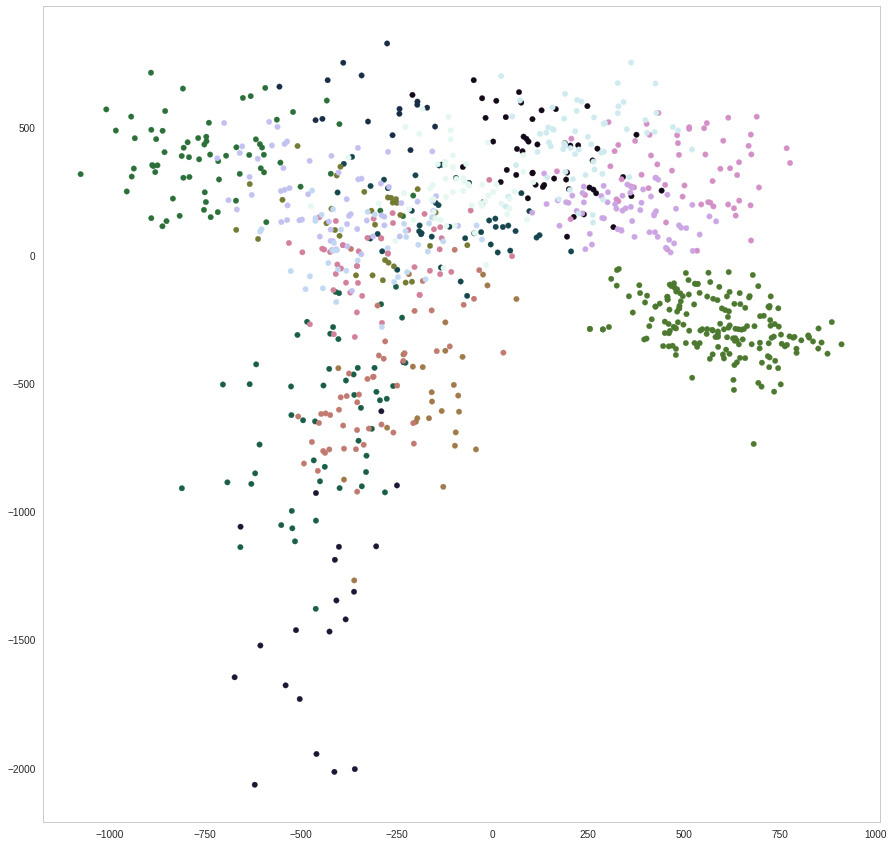
Actually tried to do some dimension reduction on the final convolution features of full pictures (didn’t try with slices yet) and it works pretty well… The question is how to react with a new point ? If it’s right in a cluster, then assign the existing class, and if it’s a little too far then say it’s a new class… Hmmm. I expect it could start to make sense if I crop pictures and train again. Clusters might become stronger and stronger
Now, supposing clusters are stronger maybe there will be ways to strongly assume that because it’s not right in a cluster, it should be a new class. Etc etc, and it goes unsupervised now.
That would, in the end, enable to “tag” automatically a new picture from a new class, switching from supervised to unsupervised.
I’m quite disappointed, although I can crop images pretty well using FCNN, I can’t get the accuracy better when training on the crops of my initial dataset. Training on both initial dataset and crops is not getting better performances.
Hi @arnaud Thanks for opening up this discussion. I have been following this thread since it was posted. Any good progress on your side?
And @jeremy thanks for the lesson 7, that was definitely the peach of the part-1 course. Regarding detection in lesson 7, I’m aware of the state of art methods like RCNN,YOLO,SSD,etc for object detection.
Is there a way we can exploit keras functional api to predict multiple bounding boxes if there are multiple fishes in the image - from lesson7 code . Or any other way to achieve this without the advanced state-of-art detection methods, since I’m working on multiple instance object detection of just single class?
Well I didn’t go a lot further regarding this heatmap approach although it seemed to work finely. There’s one thing I’ve seen from that notebook which is pretty interesting :
By combining the heatmaps at different scales, we obtain a much better information about the location of the dog.
If you go and visit the link, you’ll see that they actually compute the heatmap for different sizes and then take the geometric average of them.
Regarding localization, I just thought I should look first into dedicated methods (Fast RCNN, SSD) before going further. on heatmaps. And that’s where I am right now, into SSD : there’s a Keras implementation that works just fine here if you respect the environment It can already localize 20 classes from PASCALVOC and you can also train it on custom classes. It is a very light notebook, and easy to go through. Quite fascinating. Once again, the longest part is to make your training data fit into the expected format, and eventually manual labelling takes time too…
Didn’t go into Fast RCNN yet but should be a step too !
After manual labelling on only 50 pictures with 3 classes car, bib_number and license_plate, the training was smooth and results are promising (especially for plate that gets often recognized). car was already a class from the pre-trained network. bib_number is pretty hard… Would require more data I guess !
For the question around the tSNE clustering bit, what about computing cluster centroids and checking the distance to the nearest cluster centroid - where that exceeds the current max distance then tag it an outlier, otherwise put it in that cluster. Could do cross-validation to check performance but I’ve found that sort of cluster centroid approach works quite well in applications outside of image processing…
Sure, that makes sense, k-NN can also be used (we’re in a semi-supervised case).
Didn’t try anything further though, I’m on supervised localization now (see SSD post above). But will maybe come back to it
Hey @arnaud
Fantastic work man. Congratulations for getting the SSD working for custom classes.
Can you walk me through the process of getting SSD work with custom data; especially fitting the training data into the expected format. Thanks in advance.
Moreover, I’m in the middle of getting YOLO work, will update once done.
Hi @siv, thanks for your message. I’d be very keen on seeing a “tutorial” from you on YOLO then.
Regarding the Keras implementation, if you want to do a complete custom training on new images, here are the steps. I’ll assume you don’t even have a labeled dataset yet.
Label a certain amount of your images
(OSX) RectLabel writes annotations in .json format. One per image
(Ubuntu) labelImg does it in .xml or .json. Back in time I used it with xml, and it was very painful to make it work on OSX so I have an Ubuntu virtual machine to run it (huh).
I’d welcome other tools for labelling ? I’m surprised there’s no fancy web-based app to do it. Any one here knows one ?
Turn these annotations into the proper format expected by the SSD implementation. Nothing very hard here, just needs to understand that they save a dict as pickle in that following scheme
With (x_bl, y_bl) being the coordinates of the bottom left point. And one_hot_encoding is … well the one hot encoding. If you have 2 classes, then it’ll be one value only one_hot_encoding = 0. or 1. but if you have 3 classes it will be two values e.g (1. 0.), or (0. 1.) or (1. 1.) for example.
But remember img1_bbox_1 is a flattened list.
Then you’re… done. You can feed that pickle and the path to your images to the SSD.
I have a function to translate either labelImg (xmls) or RectLabel (jsons) annotations to that pickle format if you want. Can provide tomorrow.
Hope that helps, sometimes (often?) it seems like figuring out what goes in and what goes out is the hardest part… 95% time spent preparing the data, 5% training
hi all,
I’m very much new to machine learning.
I’ve created a simple CNN and obtained the weight file referring “building-powerful-image-classification-models-using-very-little-data” on keras blog.
As the second step, I’m planning to use a large image and identify the objects in it using the trained weight file. The identified objects should be marked using a bounding box or any other method. As I know it’s achieved using a sliding window? I’m stuck at this step over a month. Still unable to get the implementation successful. Would you kindly help me with this, please?
The two most popular and well known tools I am aware of are ImageJ, which is cross platform, been used in academia and research for years, has great documentation and allows you to script within it in multiple languages, and Sloth, which is cross platform, been used in academia and research for years, has great documentation, etc . . .
Don’t forget figuring out a fancy new loss function to give you an edge over the competition =)
tl;dr
If you want to run this kind of localization algorithm, then you may want to first use Fast-R CNN or SSD - but not code this on your own.
This is exactly the question algorithms like Fast-R CNN and SSD are trying to solve.
If you go naively into a bruteforce sliding window, you may end up in terrible computational times (looking every possible subset of an image is … long). Indeed, the hard part is to find good bounding box candidates, for that Fast-R CNN will look for ROI (Regions Of Interest), and SSD will look at randomly but well chosen generic candidates. Once you have the bounding box candidates, then you just classify and keep those that have a good enough ‘probability’.
Hope that’s clear. Although I’m not quite sure what your question was
Does anybody have an explanation for the SSD Single Shot Multibox Detector ? I can’t understand what exactly is happening.
The first thing I’m stuck at is what ‘Default box’ is. What is the output of that model?
@jeremy
Is it possible to do the same technique for telling FastAI what the boundary boxes are now that we’re using PyTorch? Lesson 7 shows how to show Class Activation Maps but doesn’t show to pass in the boundaries if they’re already known for an image.