No. It’s not. I don’t 100% remember what methodology it uses, but also note the Item Resize uses PIL, the other uses tensor logic (since it’s on the GPU/in a batch of tensors)
Indeed Item_tfms Resize is just a resize, and aug_transforms are “augmentation transforms” so it can do a resize, or a crop or other things in 09_vision.augment.ipynb it includes this 2 non contiguous lines
if min_zoom<1 or max_zoom>1: res.append(Zoom(min_zoom=min_zoom, max_zoom=max_zoom, p=p_affine, **tkw))
....
if min_scale!=1.: xtra_tfms = RandomResizedCropGPU(size, min_scale=min_scale, ratio=(1,1)) + L(xtra_tfms)
In multi-label classification tasks such as 03_Unknown_Labels.ipynb, how do you determine the best value for thresh for both accuracy_multi and BCEWithLogitsLossFlat?
Is anyone encountering a problem when running the learn.recorder.plot_losses() function from the command line? I converted my notebook into a .py file and it crashe during this step with the following error:
_tkiner TclError couldnt connect to display
Pretty sure that’s thinking/looking for something to display, which is not true when you run it from the command line.
You don’t. Thresholds are empirical. It’s dependent on the dataset and your use case.
Hii, I built a simple Image classification model but I couldn’t export it. I’m getting the below error…
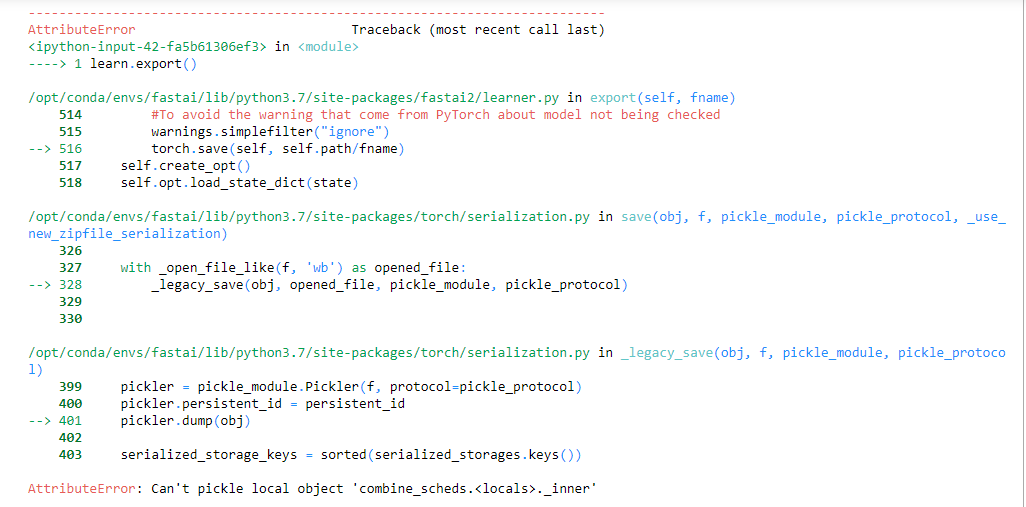
learn=cnn_learner(dls,resnet50,pretrained=True,loss_func=LabelSmoothingCrossEntropy(),metrics=accuracy)
I use LabelSmoothingCrossEntropy() ,could that be the problem?
Thanks,
Edit: Saved the model, restarted the kernel , loaded the model and now the export works fine.
Hii, is posixPath suited only for linux systems?
I tried to use load_learner(path/‘learner.pkl’) and i got the error can’t instantiate PosixPath on your system.
How do I solve this?
Thanks
I presume you’re using windows. See the pathlib docs:
Pure paths are useful in some special cases; for example:
- If you want to manipulate Windows paths on a Unix machine (or vice versa). You cannot instantiate a
WindowsPathwhen running on Unix, but you can instantiatePureWindowsPath.
1 Like
Has anyone run into mysterious crashes in v2? I’ve never seen this in fastai v1, and looking up the error suggest it’s some kind of memory leak. Was running pytorch 1.5, but now downgraded to 1.4 and still getting the same error.
> python: /opt/conda/conda-bld/magma-cuda102_1583546904148/work/interface_cuda/interface.cpp:901: void magma_queue_create_from_cuda_internal(magma_device_t, cudaStream_t, cublasHandle_t, cusparseHandle_t, magma_qu
> eue**, const char*, const char*, int): Assertion `queue->dCarray__ != __null' failed.
> Aborted (core dumped)
> ~
The only “new” thing I am doing is that I am encapsulating most of my code for training the model in a try/except block in a while loop. This allows me to set up the ‘largest variable’ batch size depending on the network architecture and GPU used, i.e. if it runs into a out-of-memory error it will restart the training and use a smaller batch size. But I do use “torch.cuda.empty_cache()” during the except block so that should have cleared out the GPU RAM…
@muellerzr
Hii,
I tried with PureWindowsPath,
path=PureWindowsPath(’./artifacts’)
__model=load_learner(path/‘learn.pkl’).
and I get an error stating, “PureWindowsPath has no attribute seek . You can only torch.load from a file that is seekable. Please pre-load the data into a buffer like io.BytesIO and try to load from it instead.” 
Not sure, I haven’t personally worked with fastai on a windows OS.
1 Like
Ohh alright.
Thank you 
Hi! where you able to fix your model deployment, I have exactly the same issue, but I do not know how to fix it.
<class ‘fastai2.vision.core.PILImage’>
but got <class ‘_io.BytesIO’>
any help?
Hi royam0820 I hope you are having a wonderul day!
Below is what the final file looked like! Its mainly based on the original ‘teddy bear’ classifier and snippets of code from @muellerzr .
import aiohttp
import asyncio
import uvicorn
from fastai2 import * # added trying to fix type error 20200212
from fastai2.vision.all import *
from io import BytesIO
from starlette.applications import Starlette
from starlette.middleware.cors import CORSMiddleware
from starlette.responses import HTMLResponse, JSONResponse
from starlette.staticfiles import StaticFiles
export_file_url = ''
export_file_name = 'artists_classifier_20200621.pkl'
classes = []
path = Path(__file__).parent
app = Starlette()
app.add_middleware(CORSMiddleware, allow_origins=['*'], allow_headers=['X-Requested-With', 'Content-Type'])
app.mount('/static', StaticFiles(directory='app/static'))
async def download_file(url, dest):
if dest.exists(): return
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
data = await response.read()
with open(dest, 'wb') as f:
f.write(data)
async def setup_learner():
await download_file(export_file_url, path / export_file_name)
try:
print("File exists?:",os.path.exists(path/export_file_name))
learn = load_learner(path/export_file_name)
return learn
except RuntimeError as e:
if len(e.args) > 0 and 'CPU-only machine' in e.args[0]:
print(e)
message = "\n\nThis model was trained with an old version of fastai and will not work in a CPU environment.\n\nPlease update the fastai library in your training environment and export your model again.\n\nSee instructions for 'Returning to work' at https://course.fast.ai."
raise RuntimeError(message)
else:
raise
loop = asyncio.get_event_loop()
tasks = [asyncio.ensure_future(setup_learner())]
learn = loop.run_until_complete(asyncio.gather(*tasks))[0]
loop.close()
@app.route('/')
async def homepage(request):
html_file = path / 'view' / 'index.html'
return HTMLResponse(html_file.open().read())
@app.route('/analyze', methods=['POST'])
async def analyze(request):
img_data = await request.form()
img_bytes = await (img_data['file'].read())
pred = learn.predict(img_bytes)
return JSONResponse({'result': str(pred[0])})
if __name__ == '__main__':
if 'serve' in sys.argv:
uvicorn.run(app=app, host='0.0.0.0', port=5000, log_level="info")
Hope this solves your technical challenge 
I tested it today with this requirements.txt and it worked fine.
aiofiles==0.4.0
aiohttp==3.5.4
asyncio==3.4.3
#torch==1.5.0+cu101
#torchvision==0.6.0+cu101
torch==1.5.0
torchvision==0.6.0
numpy==1.18.5
Pillow==7.0.0
python-multipart==0.0.5
starlette==0.12.0
uvicorn==0.11.5

Cheers mrfabulous1
3 Likes
Does anyone know if it’s possible to get dls.show_batch() to show the same consistent (reproducible) image? I’m trying to visualize data augmentation, but show_batch() keeps changing the images displayed.
I’m already using IndexSplitter with my own fixed set of val splits, so the datasets are not changing from run-to-run, but the visualization still is…
The only way I figured used is to pass unique=True, but in that case it’s only showing the first N images of the dataset (I think). What would be preferred is a random selection of images, but the same random selection of images.
The issue is in the fact each time you gather indicies on the training dataloader, they’re always shuffled. You can tell by doing the following experiment (tabular in this case, but the same works for vision):
dls = to.dataloaders()
dls[0].get_idxs()[:11]
[5882, 12248, 8969, 24741, 4134, 20467, 15052, 18692, 16251, 7092, 7134]
dls[0].show_batch()
dls[0].get_idxs()[:11]
[5855, 20989, 14712, 1539, 4967, 16457, 4665, 8793, 833, 6712, 12822]
I don’t know the solution, as show_batch deletes the internal iterator but it seems to not be.
- On top of the fact that if they aren’t shuffled, it just continues down the list.
Essentially the internal indices are being updated when they shouldn’t be.
2 Likes
Hi Zachary.
Does fastai have the concept of an environment variable ? I have a hidden folder named ‘.fastai’ in my home directory…I was wondering about changing it’s location to a different drive because I am running out of space in C:. Do I need to point an environment variable to the hidden ‘.fastai’ folder? or is there a path in a file I can change?
Hi @Legnica1241,
Not Zach here.
Yes you can set an environment variable FASTAI_HOME to set where your .fastai library
will be located.
Even better, you can just modify the config.yml in that folder right now to point your data,
archive, models to where you want fastai to look for it. Like in the example below
archive_path: ~/.fastai/archive
data_archive_path: ~/.fastai/data
data_path:~/.fastai/data
model_path: ~/.fastai/models
storage_path: ~/.fastai/data
version: 2
HTH.
Best regards,
Butch
2 Likes
Oh wow. Thank you ! I’ve been try to figure this out for a while now! Thank you so much!
Hello! Thank you for the series! I am trying to adapt the unknown category notebook to my own work. I am labeling my y's by parent_label but when I go to check a batch my labels are split into each character separated by a ; like in the picture I’ve uploaded
Here’s my code:
metersBlock = DataBlock(blocks=(ImageBlock, MultiCategoryBlock),
get_items=get_image_files,
splitter=RandomSplitter(),
get_y=parent_label,
item_tfms=item_tfms,
batch_tfms=batch_tfms)
I have noticed that Pipeline was used in the unknown notebook. I used ?? on the function but I’m still not understanding it much. Any hints or tips would be really appreciated. Thank you for your time.