I think converting the gray scale to 3-channel would be better as you’re not throwing away the very first layer, having said that CNN is a powerful model, So I also think it doesn’t matter much which method one uses. Regarding the transfer learning, do you think using transfer learning from huge handdrawn datasets like quickdraw would give better performance? Has anyone done that?
No idea. Possibly.
1 Like
Zach,
Is your style transfer example based on Gatys’s 2015 “A Neural Algorithm of Artistic Style” (what Jeremy describes as “the original way to do it” in his video)?
1 Like
Yes it is! We replicate that technique (which is also what Jeremy did in part 2 a few years back).
You can see the parallels if you explore the source code here:
1 Like
Thanks a lot @muellerzr. Awesome reply!!
So in this case we are doing dls.c = dls.train.after_item.c because since we are not using cnn_learner but just Learner we need to explicitly specify it. Correct?
Thanks a lot for the head code link!! it really help me a lot. I see now how the number of channels gets multiplied by 2. What does *body.children() mean?
It manages to return the number of channels (i.e. number of filters - nf) but I do not understand the syntax.

Finally I have a petition for the last image lecture. Could you walk us through the Datablock API code. I mean the output of DataBlock??
The reason behind is I usually code with an IDE, not with colab. In an IDE I know how to set stop points and follow the execution line by line until I understand it all. Here I do not have this deep understanding of the code which makes mistakes difficult to debug in more complex statements like
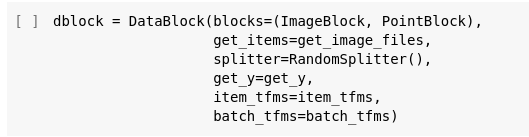
I believe this is what I am really missing…
Not quite. If we were using cnn_learner, we would still need to specify it. And since we pass in dls.c to our create_head, we’re mimicing how cnn_learner works.
I think this resource may help you:
https://spandan-madan.github.io/A-Collection-of-important-tasks-in-pytorch/
children() allows us to see the submodules inside of the body. num_features_model let’s us take what the output size of the last layer was (we don’t pass an input because it figures out what works for us).
Sure, I can try to do that.
@vijayabhaskar I took a look at your question, imagenet_stats are simply a tuple ([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])these being the means and std for the 3 channels, as pointed out by @muellerzr.
However, to be fully honest I do not see how they are applied. Here is the code of Normalize.from_stats(*imagenet_stats)], seems to me the actual normalization happens in encodes but I do not see this function being called…
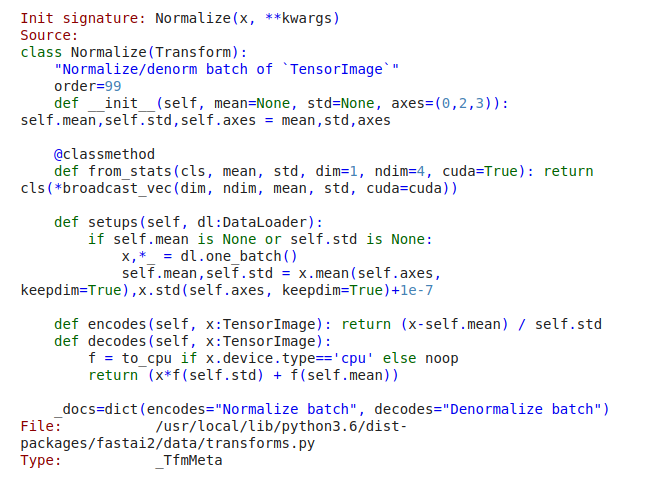
1 Like
Remember, our encodes happen when we go down our transformation pipeline. So it happens at the tail end (see how order = 99). It’s the last thing that happens. And our TensorImage is one giant matrix, so we can subtract and divide all it’s values by our passed in mean and standard deviation
How do you know about the order? Where can I find it for other cases? I looked into the code of Rotate() Rotate??but I do not see in this case the order being specified. I thought this batch_tfms were executed in the oder they were specified in batch_tfms, e.g.
batch_tfms = [IntToFloatTensor(), *aug_transforms(size=224, max_warp=0), Normalize.from_stats(*imagenet_stats)]
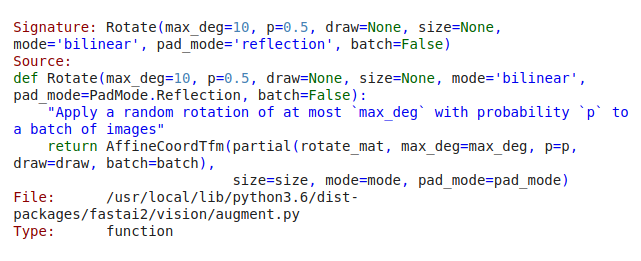
and I struggle to find where Normalize.encode() is being called 
you don’t have to call encodes explicitly. it is similar to how we never call forward from a nn.module
2 Likes
If you go look at the parent (AffineCoordTfm) you’ll see it too has an order, which is 30.
No, we have a hierarchy now, which gives us freedom to define when and how we want particular transforms to be done.
It’s being called when we go down the pipeline. Go look at how our dblock.summary() works. You can see the magic happening (especially when I talked about when we attempt to do it without a datablock)
1 Like
By the way, with dblock.summary(), the bug where Normalize would break everything was fixed  (should come out in the next version, for right now it’s on dev)
(should come out in the next version, for right now it’s on dev)
1 Like
By the way, back to our discussion of the getters, this also works for our bounding box example:
getters = [
noop,
lambda o: img2bbox[o.name][0],
lambda o: img2bbox[o.name][1]
]
block = DataBlock(blocks=...,
splitter = ...,
get_items = get_image_files
getters=getters)
Essentially we already define get_items and so we can work off of it’s result for everything that’s not the first
i was uncertain about something in 06_Keypoint_Regression … with this code
item_tfms = [Resize(448, method='squish')]
batch_tfms = [Flip(), Rotate(), Zoom(), Warp(), ClampBatch()]
since the batch transforms happen after the item ones, isn’t it possilbe that the Zoom batch transform could make one of the tensor points fall outside the dimensions of the image?
one other thing i’m not sure about, this line in 06_Keypoint_Regression
dblock.summary('')
prints out
Applying batch_tfms to the batch built
Pipeline: ClampBatch -> IntToFloatTensor -> AffineCoordTfm
starting from
(TensorImage of size 4x3x448x448, TensorPoint of size 4x9x2)
applying ClampBatch gives
(TensorImage of size 4x3x448x448, TensorPoint of size 4x9x2)
applying IntToFloatTensor gives
(TensorImage of size 4x3x448x448, TensorPoint of size 4x9x2)
applying AffineCoordTfm gives
(TensorImage of size 4x3x448x448, TensorPoint of size 4x9x2)
I would have expected to also see mention of the other batch transforms, … flip, rotate, zoom, warp, but the only transform i see is the ClampBatch.
Like I said to the above comment, those are all AffineCoordTfms (this is why we can include them)
If we look at the Zoom transform (which should probably be zoom):
We can see it runs typedispatch on our TensorPoints to take into account this ![]() But I think yes it potentially could land a bit outside
But I think yes it potentially could land a bit outside
1 Like
Yes, imagnet_stats has mean and std of the imagenet datset. If you’re using imagenet weights you should normalise with these stats. If you’re using different stats the model won’t train as you expected, you can clearly see this in Keras, if you don’t preprocess as they did while training on imagenet you will get a model that massively overfits the training set.
@muellerzr I was trying out the Bengali.ai competition with fastai2, I cropped the images and stored them in ‘images/train’ and ‘images/test’. Since the datablock path is different I couldn’t find a way to predict from the dataframe created from test.csv , can you help me with this? learn.predict(image_path) throws some error.
You should do a test_dl and pass in the list of file names from the test dataframe. Look at the starter kernel I referenced in our notebook. It shows how to do the inference. Also here:
https://www.kaggle.com/mnpinto/bengali-ai-fastai2-starter-lb0-9598/comments#752294
yes. the double negatives get/got to me. dont detach if you need gradients. detach if you do NOT need them.
1 Like