Why do we pass detach=False in the get_feats function.
If i understand detach() functionality correctly it is used when we want to compute something
that we do not want to differentiate. I would guess that the layer values we want to store using hook is something that we would NOT want to differentiate. Then why do we pass in detach=False?
What am I missing?
Hi @Srinivas, trying to help out: total_loss = content_loss + style_loss. You could take any of the 2 but focusing on content_loss for this explanation this one basically compares the features at certain specific layers for your content image and your generated image. The idea is to adjust and improve the generated image to minimize the error, so you need to back-propagate trough all these layers to get to the input, i.e. the image which you actually will adjust.
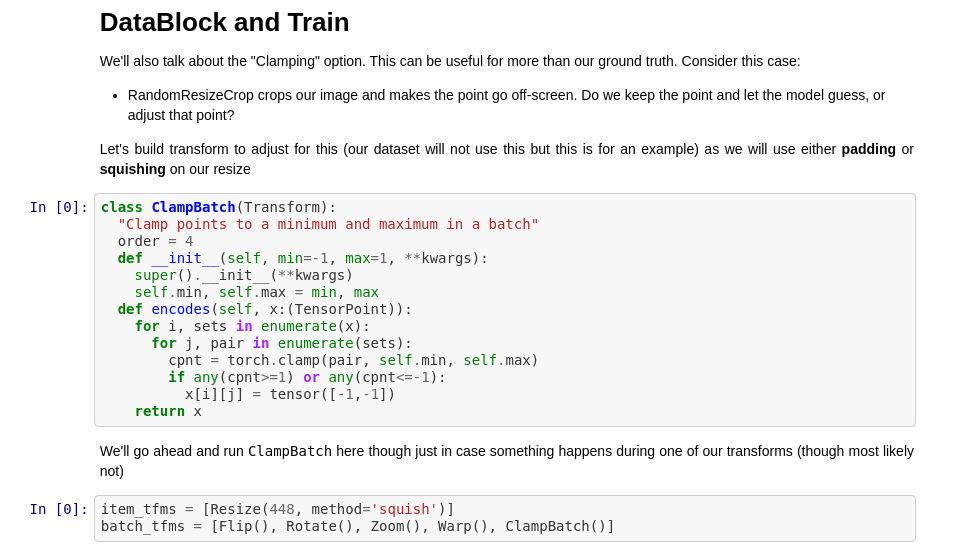
I am trying to understand how in the last lecture, we wrote a custom batch transform. Please tell me if the following is correct:custom transforms inherit from class Transform; must have encodes function where the magic happens… I believe i corresponds to the batch and j to the pair of points that we set to -1,1 if any of the two is beyond the picture limits
Why min=-1, max=1…? how are the points being resized with the image? (sorry for the vague question but I am missing here a few pieces)
Look at the TensorPoint transform and you’ll see we normalize our points to a % (-100% to positive 100%) from the center of the image. In this messy dataset some points were labeled even if it wasn’t ever on the image. Thus we could get greater than 100% or less than -100%. So we want to clamp it down if a point is not present. This is commonly done with the COCO dataset and other keypoints (on their ground truths the point is set to -1,-1 if one isn’t present)
The points are never resized (per say), they stay at the -1,-1 (or 0,0). We add this as a batch transform at the end because it simply looks at all the points after all our augmentation is done, sees if any point is out of the scope we want (-1,1), and clamps it to -1,-1 if any part is. Does this help @mgloria (I’m more than happy to explain this as much as I can because this is a very important detail not talked about much in the fastai library)
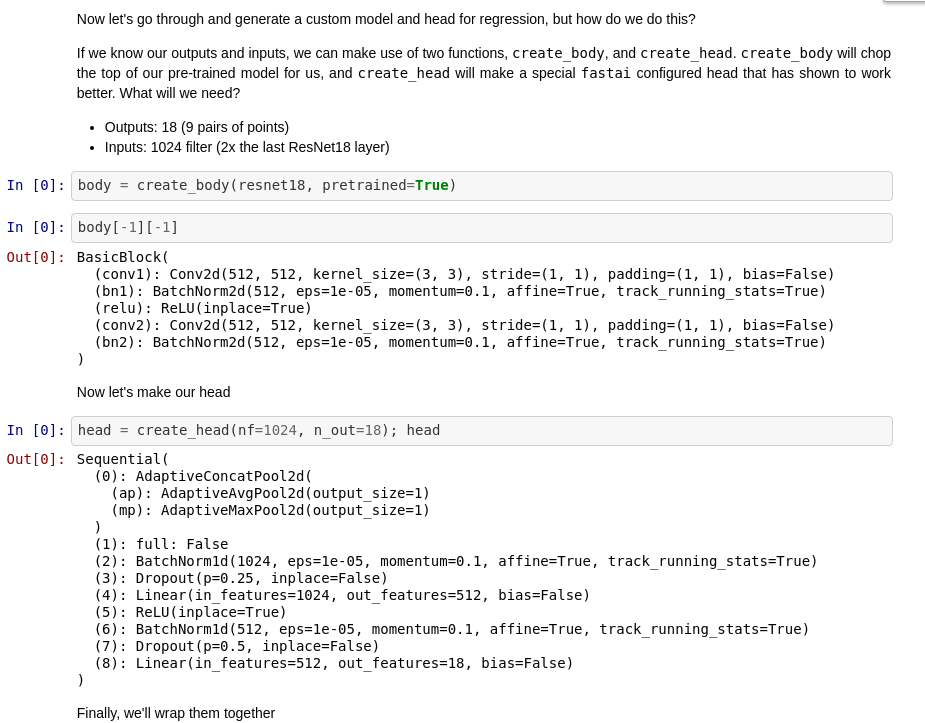
Why do we need: `dls.c = dls.train.after_item.c
I see later that we are giving manually n_out=18 so I do not see where dls.c is actually being used.
If we only had 512 channels, how are we passing 1024 as input the adaptativeAvgPool2d and AdaptativeMaxPool2d - (even if each needs 512), how is this possible?
Usually these layers are used to reduce image size but numbers of channels stays the same.
@sgugger he’s discussing FeatureLoss. This can also be found in the SuperRes notebook from the course (I don’t know the answer but here’s the loss function from the SuperRes course notebook)
class FeatureLoss(Module):
def __init__(self, m_feat, layer_ids, layer_wgts):
self.m_feat = m_feat
self.loss_features = [self.m_feat[i] for i in layer_ids]
self.hooks = hook_outputs(self.loss_features, detach=False)
self.wgts = layer_wgts
self.metric_names = ['pixel',] + [f'feat_{i}' for i in range(len(layer_ids))
] + [f'gram_{i}' for i in range(len(layer_ids))]
def make_features(self, x, clone=False):
self.m_feat(x)
return [(o.clone() if clone else o) for o in self.hooks.stored]
def forward(self, input, target, reduction='mean'):
out_feat = self.make_features(target, clone=True)
in_feat = self.make_features(input)
self.feat_losses = [base_loss(input,target,reduction=reduction)]
self.feat_losses += [base_loss(f_in, f_out,reduction=reduction)*w
for f_in, f_out, w in zip(in_feat, out_feat, self.wgts)]
self.feat_losses += [base_loss(gram_matrix(f_in), gram_matrix(f_out),reduction=reduction)*w**2 * 5e3
for f_in, f_out, w in zip(in_feat, out_feat, self.wgts)]
if reduction=='none':
self.feat_losses = [f.mean(dim=[1,2,3]) for f in self.feat_losses[:4]] + [f.mean(dim=[1,2]) for f in self.feat_losses[4:]]
for n,l in zip(self.metric_names, self.feat_losses): setattr(self, n, l)
return sum(self.feat_losses)
def __del__(self): self.hooks.remove()
dls.c is made if we pass our dataloaders to cnn_learner. It will read this to figure out how many outputs we want in our head
It gets split between the two, so it turns into 512 (they both run at once). Another thing to explore for this is how create_head uses the input filters
Thanks @mgloria. So in the case of style transfer we capture the layer specific predictions and compare to the target to generate loss and this loss needs to be differentiated to backprop and reduce loss hence detach = False. Got it.
Yes - I understood that you detach when you DO NOT need gradients. Did not grasp that gradients were needed when doing feature loss which I now get from @mgloria’s explanation. Thanks
Hi @muellerzr I just gone through the notebooks of the last video, I see you manually calculated the mean and std to normalize the dataset for the bengali notebook, but you were using a pretrained model, I don’t understand why you chose to use the dataset’s mean and std while you should have used the imagenet_stats to normalize?
Because I don’t have a 3 channel image (Normalizing ImageNet makes it 3 channels). To make up for that I also changed the first conv layer to accept our 2D image. Jeremy’s rule of thumb: ALWAYS transfer learning when and where you can
I see, now it makes sense. I have always treated grayscale images as 3 channel images by using .convert(“RGB”) Pil function, I thought that would be a better approach since you don’t need to mess with the model at all and imagenet_stats can be used to normalize. Which is a better approach from your view?
Well, it’s not a 3 channel image, so I’d rather keep it not as one personally And the dataset is only 2 channels. So I’d need it’s info still. Even if I made it 3 channels. Because that’s still not similar to ImageNet enough to use their stats (IMO) which then says why so I use their weights, again always pretrained. You can get Atleast something from their weights
Yes, so I don’t know which is better or worse mabye they’re the exact same! Many ways to skin a cat. This just one method I saw being used for situations like this