If it works on dev, I may wait until the next release to include it in (though this should be within a week). Thanks for investigating!
1 Like
In 03_Unknown_Labels notebook
pets_multi = DataBlock(blocks=(ImageBlock, MultiCategoryBlock),
get_items=get_image_files,
splitter=RandomSplitter(),
get_y=[RegexLabeller(pat = r'/([^/]+)_\d+.jpg$'), multi_l],
item_tfms=RandomResizedCrop(460, min_scale=0.75),
batch_tfms=[*aug_transforms(size=224, max_warp=0), Normalize.from_stats(*imagenet_stats)])
there is both get_items and get_y, shouldn’t that get_items be get_x since get_image_files returns only a list of image paths? When I replace it with get_x I get this error
TypeError: object of type 'PosixPath' has no len()
Why is get_items used and not get_x? How this works, we now have both get_items and get_y?
1 Like
Our new get_y overrides whatever the get_y from items is (which if you try it you’ll notice it just uses our original input path I believe so our x and y are the same)
If you wanted to use a get_x, you could do get_image_files(path)
1 Like
A very clear example (if you want to jump a bit ahead) is in the object detection notebook.
1 Like
I had the same doubt @vijayabhaskar . my understanding was either use get_items or get_x and get_y. The overriding makes sense now though. But did you mange to get it running with get_x : get_x = get_image_files(untar_data(URLs.MNIST_TINY)) as Zachary suggested?? i still get an error.
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-8-d21d4394e08f> in <module>()
----> 1 dls = pets_multi.dataloaders(untar_data(URLs.PETS)/"images", bs=32)
1 frames
/usr/local/lib/python3.6/dist-packages/fastai2/data/block.py in dataloaders(self, source, path, verbose, **kwargs)
89
90 def dataloaders(self, source, path='.', verbose=False, **kwargs):
---> 91 dsets = self.datasets(source)
92 kwargs = {**self.dls_kwargs, **kwargs, 'verbose': verbose}
93 return dsets.dataloaders(path=path, after_item=self.item_tfms, after_batch=self.batch_tfms, **kwargs)
/usr/local/lib/python3.6/dist-packages/fastai2/data/block.py in datasets(self, source, verbose)
83 def datasets(self, source, verbose=False):
84 self.source = source ; pv(f"Collecting items from {source}", verbose)
---> 85 items = (self.get_items or noop)(source) ; pv(f"Found {len(items)} items", verbose)
86 splits = (self.splitter or noop)(items)
87 pv(f"{len(splits)} datasets of sizes {','.join([str(len(s)) for s in splits])}", verbose)
TypeError: object of type 'PosixPath' has no len()
and get_items[0] returns Path('/root/.fastai/data/mnist_tiny/valid/3/8551.png') which is not a tuple.
I may certainly be wrong there, I haven’t played with the get_x as much as I would like :), instead opting for get_items
sounds good, thanks. will keep you posted if i find something interesting.
1 Like
@muellerzr another question for you in regards to transforms. I’m looking at 02_MNIST and i see CropPad is used in the item transform and Normalize is used in the gpu transform. i took a peek at the source for Normalize and CropPad and see they both inherit from Transform.
do you know of a rule for which transforms are to be used for item vs batch?
It depends on what they are being used for. Every transform can be either, but the item transforms help follow a few rules for our batches. See the slides here (specifically the very last one):
2 Likes
Got it. Thanks!
@barnacl I think I get it now, @muellerzr correct me If I’m wrong.
-
When we create a dataloader we pass in a
sourcewhich can either be adataframeor apath.
get_xandget_yare functions that are applied to thesourcedirectly ifget_itemsis not defined, if it is defined they’re applied to outputs ofget_items. -
The purpose of get_items is to get a collection of inputs and outputs in some way, if we pass a dataframe it already has a collection of both, but if we pass in a path, we need to specify get_items to tell it how to get a collection from this path.
-
If we had a dataframe we simply specify 2 ColReaders via get_x and get_y, which will take this collection(dataframe) and get the inputs and outputs.
-
If we had a path, we need to get a list of paths from
get_items=get_image_files, this collection is now needed to be transformed to inputs and outputs, so we define aget_x=None(we don’t explicitly do as that’s the default value anyway) which internally specifies a dummy function which takes in the input and returns the same as output, and also we define aget_yto get the labels from the collection (list of paths), now we have inputs and outputs. -
The
gettersattribute stores the get_x and get_y functions that will be used to get the inputs and outputs, so if print them, you can see:
[<function fastai2.imports.noop>,
[<fastai2.data.transforms.RegexLabeller at 0x7f83b8389d68>,
<function __main__.multi_l>]]
getters[0] will be used to get the inputs from the collection(dataframe or list of image paths), getters[1] will be used to get the outputs.
4 Likes
@muellerzr I have a doubt regarding the source,it takes only dataframes or paths? or as long as it is handled by get_items, get_x and get_y it accepts anything?
Hi @vijayabhaskar the way I see it is the following: (for the planet multi-label example) get_x should get you the path to the images and get_y the labels. If you look at the code you are not passing a folder were the images are but a dataframe (df) so get_x and get_y are extracting the columns of interested (i.e. crafting the absolute path / getting the multi-labels) from the table. You could instead use ColReader for both get_x and get_y, it does the same if you are not confident with lambda functions in python. Finally, get_items returns a tuple which should be like the result from calling (get_x, get_y). If you call get_items but then get_y, essentially the last call will overwrite the first. Hope this clarifies!
2 Likes
@muellerzr which libraries should we install in colab to have the latest version of the library, I found from a post of @Srinivas the following but I struggle to understand what he/you mean:
I see that there is a difference in the installation commands between the two nbs.
Older version says:
import os
!pip install -q fastai2 fastcore torch feather-format kornia pyarrow wandb nbdev fastprogress --upgrade
!pip install torchvision==0.4.2
!pip install Pillow==6.2.1 --upgrade
os._exit(00)
Seems to fix torchvision and Pillow versions (note that error reported with PILLOW_VERSION is only in Pillow 7.0.0) so this could be the cause???. Do not know whether fixing torchvision version is important as well??
Newer install says:
import os
!pip install -q torch torchvision feather-format kornia pyarrow Pillow wandb nbdev fastprogress --upgrade
!pip install -q git+https://github.com/fastai/fastcore --upgrade
!pip install -q git+https://github.com/fastai/fastai2 --upgrade
os._exit(00)
In addition two more minor questions to our study group: 1) what does the syntax git+https above mean? 2) is there a way to run the fastai2 documentations notebook easily in colab? I believe it would help me a lot to understand it better rather than just looking at the executed code. How are you guys doing it? Thanks a lot!! 
Hi @mgloria that’s exactly what I think it’s happening, but I still have this doubt, can we pass anything while creating dataloader as source as long as we handle it using get_items, get_x and get_y?
-
The syntax git+https is nothing but git+{repo url}, basically what it does is clones the repo and install it as python library. Exactly similar to doing a simple
pip installbutpip install git+{repo url}allows you install the most updated copy from github. Depending on when you installpip install git+{repo url}can be broken, whilepip installinstalls the last stable release. -
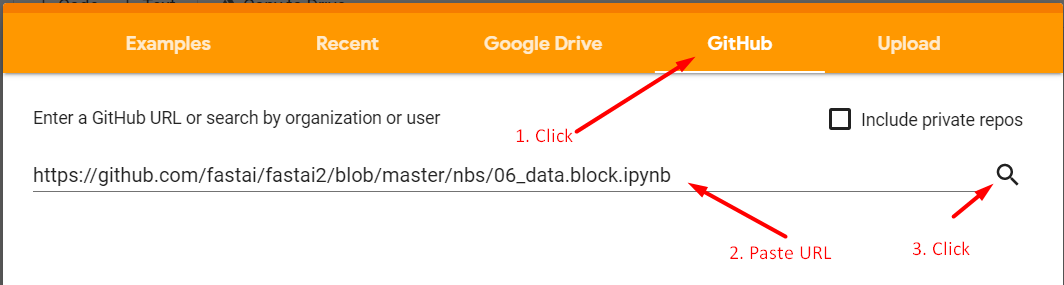
You can simply open https://colab.research.google.com/ click on Github tab, paste the notebook github url, and press the search button next to it.
2 Likes
Hi! I have written a short article on medium on how to deploy your model to heroku. Works great. I have also used Heroku because it’s free (at least if you just want to do a demo or prototype): https://medium.com/analytics-vidhya/put-deep-learning-image-classifier-in-action-a956c4a9bc58
The two scripts do not do the same thing. I saved time by installing direct versions of torch and torchvision as else it would install 1.4.1 then downgrade. Yes. This is the environment you need to stay in if you want to use the library. It will break if you try the most recent installations of everything.
On documentation, run the same script for installs of the lib then just run them.
And then everything @vijayabhaskar said 
Also: in regards to where to keep an eye out for those install changes, it’s this thread that I update
Thanks a lot to both! For the ones not following all the posts. The required install is:
import os
!pip install -q feather-format kornia pyarrow wandb nbdev fastprogress fastai2 fastcore --upgrade
!pip install torch==1.3.1
!pip install torchvision==0.4.2
!pip install Pillow==6.2.1 --upgrade
os._exit(00)
just as indicated in the course notebooks 
3 Likes