@wgpubs recently released a library to use HuggingFace transformers, although as of writing I don’t think you can pre-train with it yet, but the classification element should work https://ohmeow.github.io/blurr/
Sylvain also released a Fastai transformers tutorial, but right now it only covers text generation, but worth a look to see how he integrates HF and fastai: http://dev.fast.ai/tutorial.transformers
One disadvantage to training from scratch with transformers is that the impressive results they have gotten has been due to using really huge amounts of data and take a long time to pre-train, so I would either start with a pre-trained transformer model or pre-train an AWD_LSTM
Hii @muellerzr, once the language model is created, the model understands the language so from is there is it possible to take it to chat bots? has anybody worked on it ?
We follow the OpenAI GPT-2 to model a multiturn dialogue session as a long text and frame the generation task as language modeling. We first concatenate all dialog turns within a dialogue session into a long text x_1,…, x_N (N is the sequence length), ended by the end-of-text token.
I want to confirm my understanding of this example…
We have a DataBlock
Within that DataBlock we have many TextBlocks
Each TextBlock has a method .from_df which in this example is saying go to our ‘text’ df and we a specifying it’s a language model
Once the TextBlock has this data it will use get_x from the ‘text’ column using ColReader
And finally the data is being split 90:10 for training and validation set
The next part I’d like confirmation/correction on. I understand it is probably in the source code but I can’t understand it fully.
Q: Is the get_x being performed by each TextBlock here or the DataBlock?
Q: Similar to the above question, is the data being split once the TextBlocks form up the DataBlock or is it split per TextBlock
I think my new example may help some. I’m in the middle of redoing the course material/course, check out the revamped lesson 1, this may help. However it’s just like the regular DataBlock API, one TextBlock for your input, other blocks for output.
Hi @muellerzr, I’m looking at your updated 01_Intro notebook, and I need some help understanding the learning rate adjuster schema and how you come up with it.
adj = 2.6**4
Maybe this is just a heuristic, and if you could share the rationale behind it, it’d help me apply to a different dataset.
Also, I noticed you were adjusting the lr based on how you were unfreezing. I seem to be missing some basic info on why this is the case. Did I miss this in one of the lessons somewhere?
I wonder if anyone knows how to deal with overfitting with an RNN? I hope Zach talks about this in subsequent lessons.
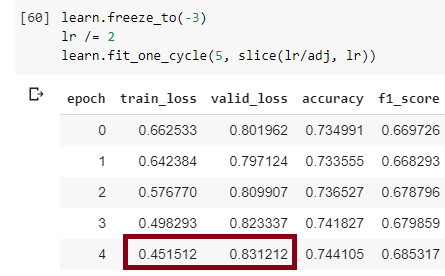
For example, I have something like this, while training:
My valid_loss is not going down but train_loss is, and is drifting away from the valid_loss. I’m trying to first overfit, and then regularize. How do I do that now?
I tried to change drop_mult, but it does not seem to be an attribute of the learner. Does anyone else have experience with this?
================================
UPDATE:
I still don’t know how to change drop_mult or alter in the middle of my training loop, interactively by looking at my loss trend. However, I initialized with drop_mult of 1 when I create the learner, and I am seeing much better behavior that is allowing me to train for longer, and reach better scores.
Also, using lower values of moms helps. moms default for text_classifier_learner is moms = (0.95, 0.85, 0.95)
I’m seeing better trend with: moms = (0.8, 0.7, 0.8)
Not sure if it’s possible to alter drop_mult after setting up Learner, but what you could do is add/increase weight decay by passing e.g. wd=0.01 or higher values to learn.fit_one_cycle(...)