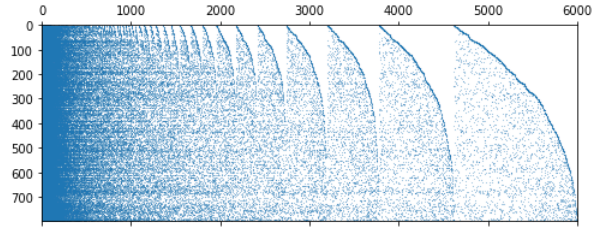
just got a little distracted with the sparsity pattern of the doc-term matrix in 3-logreg-nb-imdb:
I think we see the density ripples because “Elements with equal counts are ordered in the order first encountered” - so tokens are ordered by usage frequency then by when they were 1st encountered.
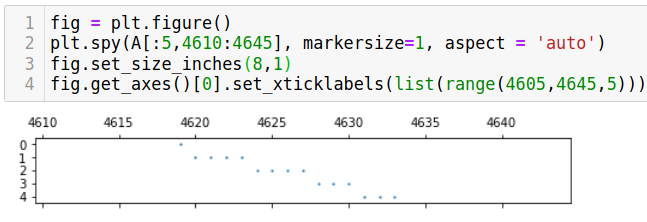
If we zoom right in ↓ we can see new tokens added by the 1st few docs get consecutively assigned indexes - (in the plot above ↑ this is what makes the edge of the ripple dense):
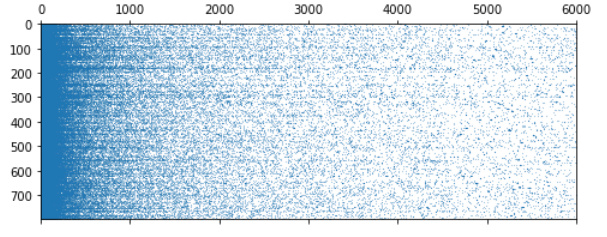
If we remove doc order from the plot with np.random.shuffle(A), we loose the ripples:
I’m trying to run the nn-vietnamese notebook, but the get_wiki function won’t work. It returns the following error:
FileNotFoundError: [Errno 2] No such file or directory: ‘/root/.fastai/data/viwiki/text/AA/wiki_00’
This is after “extracting…” gets printed, so I’d assume this is the step:
shutil.move(str(path/‘text/AA/wiki_00’), str(path/name))
I’m using Google Colab, GPU-enabled.
Any idea what the error might be? I’d suspect it’s Colab running out of space, but the download and upzipping seem to work fine.
Hi! If I want to run a notebook (5-nn-imdb) on a cloud, how should I deal with this “Unzip it into the .fastai/data/ folder on your computer.”? Where I can put wikitext?
Thanks for the list. I just started running the notebooks in course materials and it seems some modules are deprecated (or their names have changed). For example, in 2-svd-nmf-topic-modeling.ipynb
from sklearn.feature_extraction import stop_words
is now
from sklearn.feature_extraction import _stop_words
Is it possible to know the version of all the libraries mentioned above?
P.S. I’m using scikit-learn 0.24.2
Just sharing a paper explaination that was only a bit above my level of understanding, so perhaps broadly interesting to others (and summarising it helps me remember better)
I’m in the 3-logreg-nb-imdb.ipynb portion of the lecture. Most of the code is giving error. I know the tutorial asked to install the fastaiv1, but most of the method used in fastai_v1 are changed.
I’m trying to solve all the errors and run the notebook, although it is taking too much time in solving the errors rather than understanding the concept. I know this would be a practice for me to learn to debug. Still, I’m not in favour of changing the whole notebook implementing the new methods from the new fastai version. This is just Lesson 3 As such I’m a newbie to NLP and it would take a lot of time to do that.
Now one solution is to install the required packages in local and start running the notebooks. But I don’t have GPU in my laptop and wanted to run all the notebooks on Google coLab. Now Another problem in google colab is that the python installed ther eis 3.10.something. While most of the fastai’s components are valid on python versions<3.10. Basically what I mean to say is some of the fastai’s modules are not compatible with python 3.10
So what I wanted to ask is :
Is there a way to run the notebook with minimal errors( errors especially related to core packages like fastai and it’s sub-modules like DataLoaders, TextDataLoaders etc) so that I can focus on learning the concepts of NLP rather than understanding what the new methods do as compared to older methods. FYI the notebook uses methods from old versions ?
If not, what would your suggestion about ?
are we going to have a new version of the A Code-First Introduction to Natural Language Processing 2019 in the near future ?