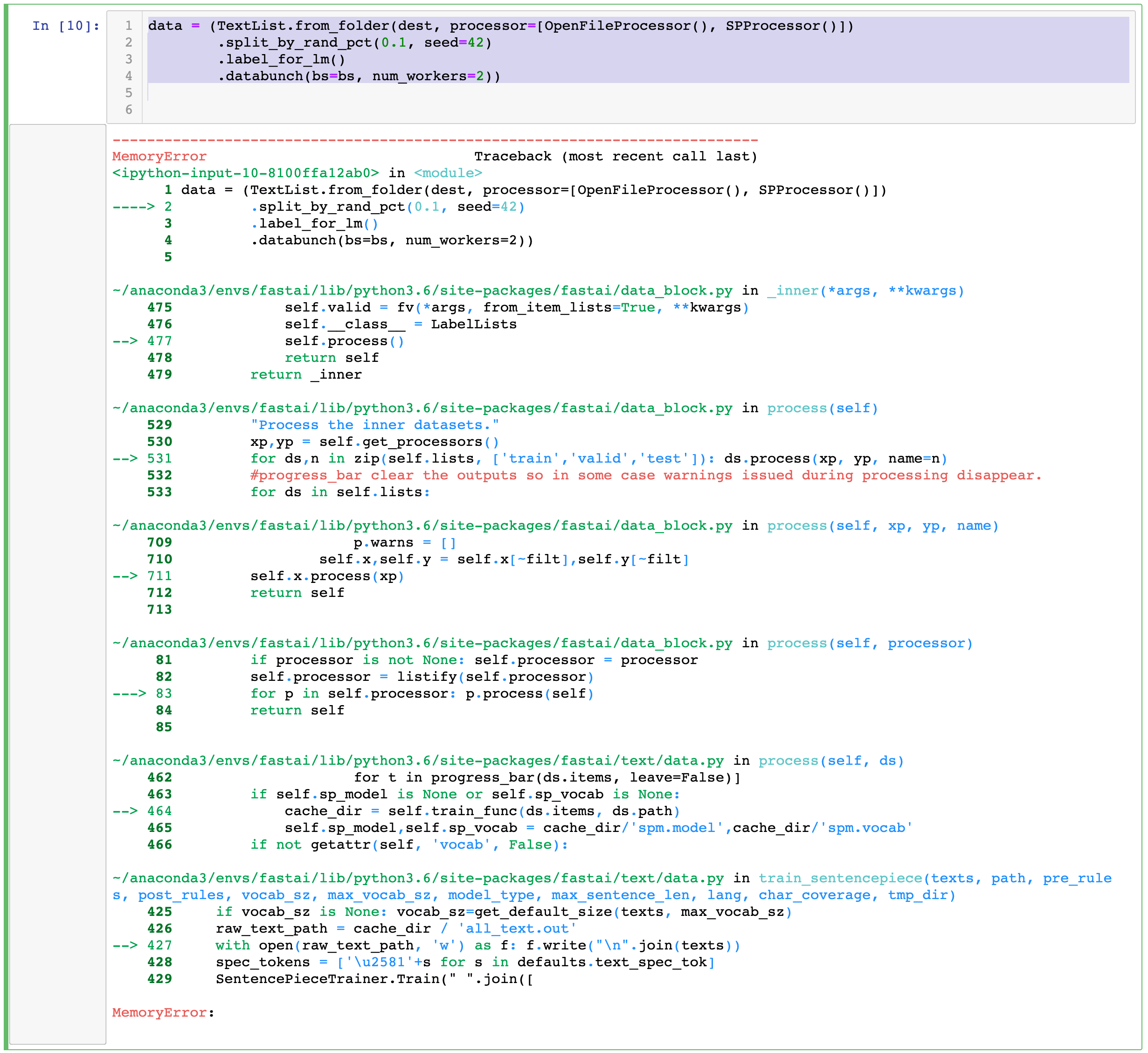
Generating a German language-model, the way Jeremy does for Turkish language. After watching the lecture videos, I was curious to build my own language model for German. I have followed the steps but set language to “de” when downloading the wiki sites.
Nevertheless this line throws an error: MemmoryError: (I have watched the processes with the top on the terminal and the jupyter process never ran over 50% memory usage).
My system has 32GB RAM. (GPU RAM was not used at this stage)
The error occurs after the progresbar finishes. Any idea where to dig deeper to find the error?