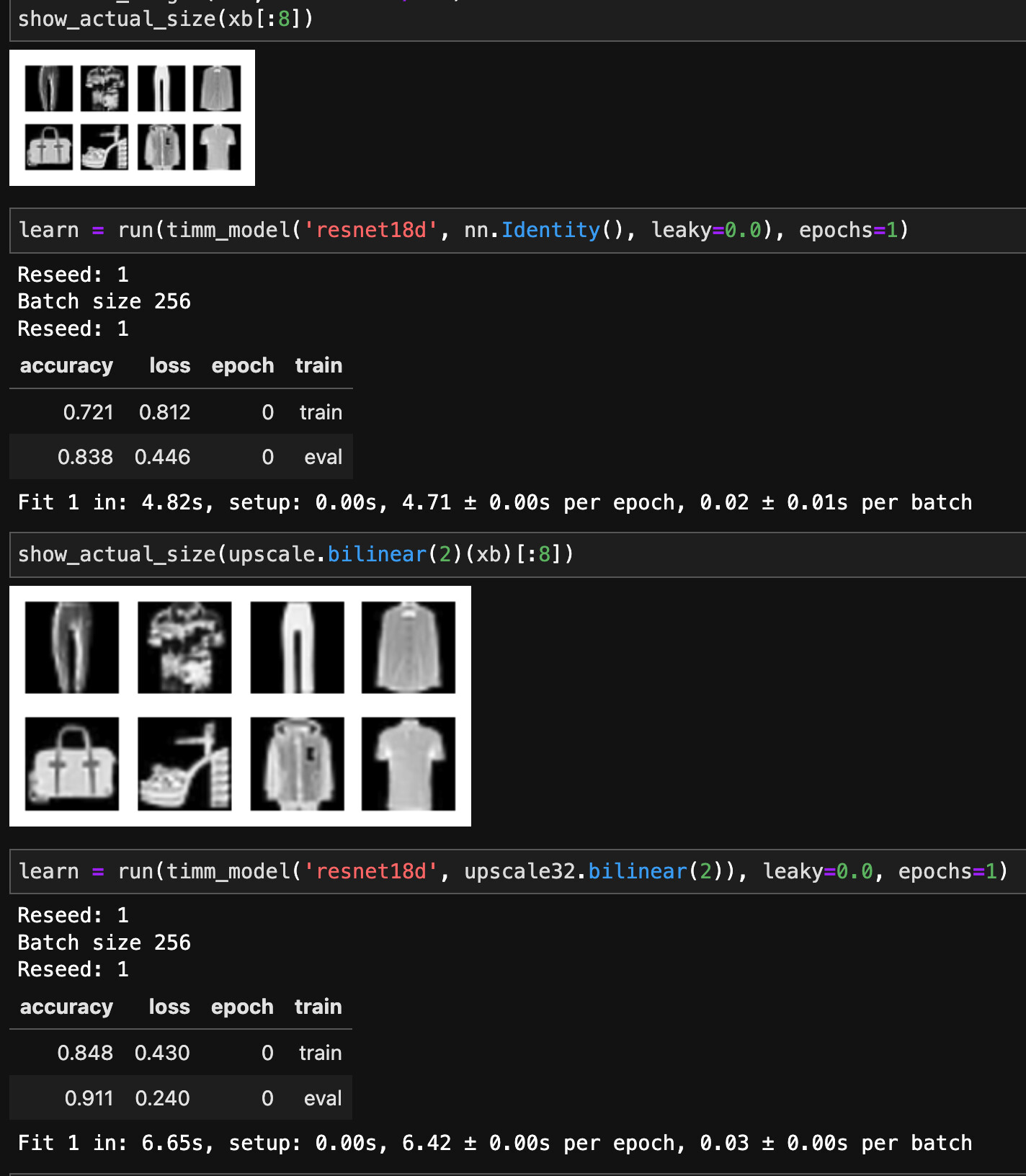
How about resnet18d trained up to 95.78% in 285 sec and 94.2% in 35s (on 2080ti)?
I know this is not about the speed but I hope to spark your interest again as this dataset is very rewording to work with when you use LazyMetrics/LazyProgress. (Jeremy would you accept PR for that?)
94.2% with vanilla resnet18d
The trick was to scale up the image to 64px and initialise resnet properly, then vanilla resnet18d trains up to 94.2%, with AdamW without or with weight decay,
BTW. We are using AdamW that has default weight_decay of 0.01, even though our models have batch norm. Although it doesn’t seems to be bad at least for lr=2e-2.
Upscaling probably helps resnet retain information in later blocks. Here is an accuracy after epoch contrasted with actual image scale
Getting to 95.78% and 95.82%
Scaling worked, but then I wasn’t able to get anywhere near the top results after applying our training improvements. General Relu/Swish/Hardswish, @christopherthomas curriculum learning, @tommyc OneCycleWithPlateau, augmentation with TTA all don’t have visible impact for 5 epochs.
Thanks to @johnri99 analyses I’ve thought about implementing mixup and label smoothing which I hoped it will help with noise. And it does so but only sometimes :). But combined with google’s lion optimiser it let me improve from 95.63%/95.55% up to 95.78% (50 epochs 289s).
Here are the relevant attributes in a small DSL that wraps learner:
#95.78
run(timm_model('resnet18d', upscale32.bilinear(2), leaky=0.0, drop_rate=0.4),
get_augcb(transforms.RandomCrop(28, padding=1, fill=-0.800000011920929),
transforms.RandomHorizontalFlip(0.5),
RandErase(pct=0.2)),
lion(1e-3, bs=512), # adamw(1e-2, bs=512) it gives 95.54%
mixup(0.4, lbl_smooth=0.1), # if removed gives 95.53% (lion) 95.63 (adamw)
epochs=50, tta=True)
Btw. Lion is an absolute marvel. it is almost as simple as sgd, it is smaller (one moving average), and it does not hide the fact that it updates model with learning rate disregarding gradient value which is quite pleasing (Adam does the same, when update direction does not change but it is hard to notice). Here is a simplified (3 loc) implementation that updates 1 parameter
I also trained resnet50d, it gets slightly better results more often than resnet18d.The best I have is 95.82%, I’ve got the result using dadaptation.DadaptAdam (I don’t have the implementation of DadaptAdam from scratch yet as I’m still processing the paper), here is the config:
run(timm_model('resnet50d', upscale32.bilinear(2), leaky=0.0, drop_rate=0.4),
get_augcb(
transforms.RandomCrop(28, padding=1, fill=-0.800000011920929),
upscale32.bilinear(2),
transforms.RandomHorizontalFlip(0.5),
RandErase(pct=0.2)),
mixup(0.4, lbl_smooth=0.1),
opt_func=partial(dadaptation.DAdaptAdam, weight_decay=0.0), base_lr=1,
epochs=50, tta=True)
If you want to have a closer look here is a notebook with the relevant experiments extracted.