Hello,
For my project, I need to train a model that can recognize handwritten “D, T, F, Y” letters. So I downloaded this dataset. And then I extracted the letters I need, and turn them into .png files using this script.
- And then first of all I inverted their colors and added black border:
from PIL import Image, ImageOps
from imutils import paths
paths = paths = list(paths.list_images(‘/content/content/abece’))
for i in paths:
img = Image.open(i)
inverted_image = PIL.ImageOps.invert(img)
img_with_border = ImageOps.expand(inverted_image,border=4,fill=‘black’)
img_with_border.save(i)
- And then added a white border:
for i in paths: img = Image.open(i) img_with_border = ImageOps.expand(img,border=4,fill='white') img_with_border.save(i)
so they look like this:

So step 1 and 2 are for making the data similar to expected inputs.
- Then, I built the data:
np.random.seed(42) data = ImageDataBunch.from_folder(path, train="abece", valid_pct=0.20, num_workers=4).normalize(imagenet_stats)
- Model trained for %99 accuracy with resnet18 pretrained model.
- I export the model:
learn.export()
- And run the model on the test data that it’s never seen before:
from fastai.vision import learner, load_learner, open_image from IPython.display import Image, display learn = load_learner("/content/content/","export.pkl") from imutils import paths paths = list(paths.list_images('/content/test')) for resim in paths: model = learn.model model = model.cuda() img = open_image(resim, div=True, convert_mode='L') prediction = learn.predict(img) display(Image(filename=resim)) print(prediction[0]) print(resim)
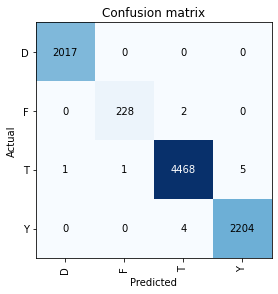
- Results:


- I tried converting the data to JPG, or converting the test data to both JPG and PNG, no luck. It just doesn’t understand the letters I’m putting. There must be something I’m missing important here.


 Thanks for the answers though.
Thanks for the answers though.