I am training a multilabel classifier on 5 classes (animals, buildings, landscapes, humans, and vehicles). Each class has 2000 images (unclean). I took 300 images from each class for testing so I am left with 8500 training images and 1500 testing images. I used a bing image downloader Python library to automatically generate the dataset.
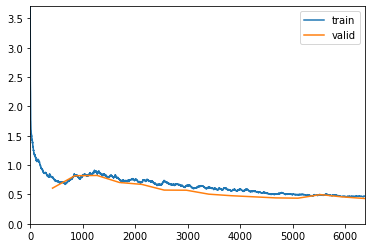
I’ve trained two 15 epochs (finding a new learning rate at the beginning & in between). This is the result of my first 15 epochs:
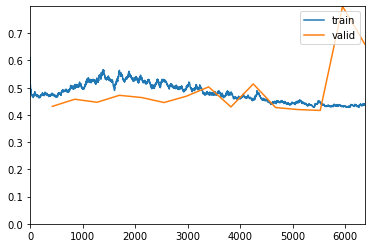
The model converges well with the validation set. After running another 15 epochs with a new learning rate, this is what I get:
The highest accuracy I got was 99.1% top-1 during training. When I run learn.validate() on an unseen, labelled test set, I get 89.5% top-1.
I know I am overfitting. I am curious what I can do to fix these numbers.
My thoughts/experiences so far… (happy for ideas from others if I have this wrong)
As you probably know, you don’t want the validation to spike up like that past the training line, as that is overfitting.
Things to try:
-train longer, with the hope that the validation will come down, under or very close to the training
-use a callback to only save the model when the validation is the lowest its ever been. So the model will only be saved at the lowest validation point. I think the below code will do this.
‘early’ monitors the ‘valid_loss’ and will stop (patience) after 10 epochs if valid_loss doesn’t get lower
‘save’ saves the best/lowest validation loss model
early = EarlyStoppingCallback(monitor='valid_loss', patience=10)
save = SaveModelCallback(monitor='valid_loss')
learn = unet_learner(dl, resnet34, cbs=[early,ShowGraphCallback(),save])