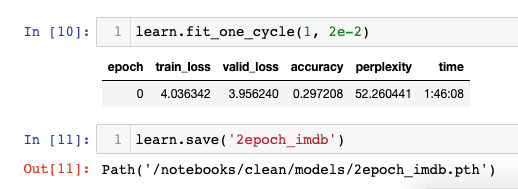
I am not sure if the 30G is GPU memory. It could be probably CPU memory. I tried running the same code on RTX 5000 in jarvislabs.ai, it took approximately 13.46 seconds.
Since you are getting a CUDA OOM error, it sounds like the model is being trained on the GPU and not via CPU.
I’m not seeing a Paperspace 30G GPU on their instance list, but if it’s one of the cheaper GPUs, perhaps a M4000 or P4000, those both have significantly less RAM and compute power then the Titan RTX which the lesson was ran on.
If that’s the case, you’d have better luck using Colab or Kaggle. Kaggle’s P100s are still a lot slower than the Titan RTX, but should be leaps and bounds better than a M4000 or P4000. Likewise a T4 on the free tier of Colab will be slower but also should be an improvement, especially if you used Mixed Precision.
Hey Roger. You might try paper space just for one month to see if that RTX4000 runs faster for you. They also have faster GPUs you can rent by the hour for a couple of dollars an hour.
note: I never seemed to get mine to run as quickly as Jeremy’s example, but about twice as fast was super useful.
Fastai currently doesn’t support TPUs, so unless you are using a custom callback your code is training on CPU. A GPU instance should train faster (even a K80, I’d imagine).