Hi Folks,
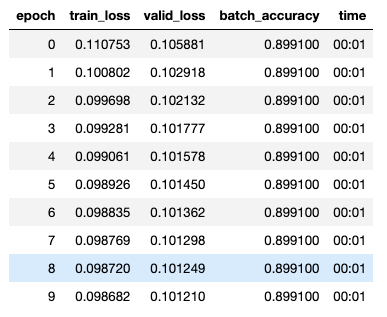
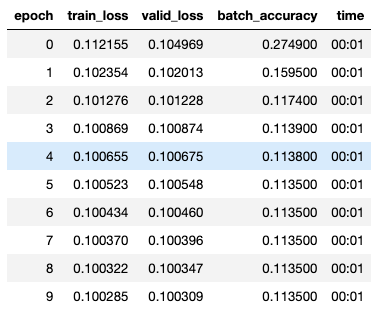
I have spent too many hours trying to get past my bug. I am trying this hw assignment using the learner method, simple_net, and batch_accuracy. My problem is that my batch_accuracy is flat (0.89910) and my network give bad results when tested on a few samples. Can you please help find my error? Is something setup incorrectly? Maybe my indices are wrong? How can I “reset” my learner?
(So sorry if this is the wrong category)
Notes:
- train_x and train_y both look good (60k rows 28*28 columns and 60k rows 10 columns)
- the resnet-18 and cross entropy method does work (98% accuracy AND validated on a few pictures)
Here is some code to chew on for the method I am developing and where I need help:
def init_params(size, std=1.0): return (torch.randn(size)*std).requires_grad_()
def mnist_loss(predictions, targets):
predictions = predictions.sigmoid()
return torch.where(targets==1, 1-predictions, predictions).mean()
simple_net = nn.Sequential(
nn.Linear(28*28,30),
nn.ReLU(),
nn.Linear(30,10),
)
def batch_accuracy(xb, yb):
preds = xb.sigmoid()
correct = (preds>0.5) == yb
return correct.float().mean()
dset = list(zip(train_x,train_y))
valid_dset = list(zip(valid_x,valid_y))
dl = DataLoader(dset, batch_size=256)
xb,yb = first(dl)
valid_dl = DataLoader(valid_dset,batch_size=256)
dls = DataLoaders(dl, valid_dl)
w1 = init_params((28*28,30))
b1 = init_params(30)
w2 = init_params((30,10))
b2 = init_params(10)
params = w1,b1,w2,b2
learn = Learner(dls, simple_net, opt_func=SGD,
loss_func=mnist_loss, metrics=batch_accuracy)
learn.fit(10,0.1)