Okay we’ve isolated the issue (just to keep you updated), and I’m working on a PR now. What’s happening is when points go off-screen, we don’t actually properly clamp it (and my own clamp function actually didn’t solve this issue, as you can get a result such as: [ 1.0661, -0.0437] when our points need to be between -1 and 1).
I don’t deny something else may be afoot here, but first let’s fix the bug we know is a bug The other option would be to try training without warp, etc and see if it’s still present. We may have simply gotten lucky. There were some hps not being passed down and some defaults weren’t quite the same in the image augmentations we fixed too in relation to the probabilities, so this could be another factor.
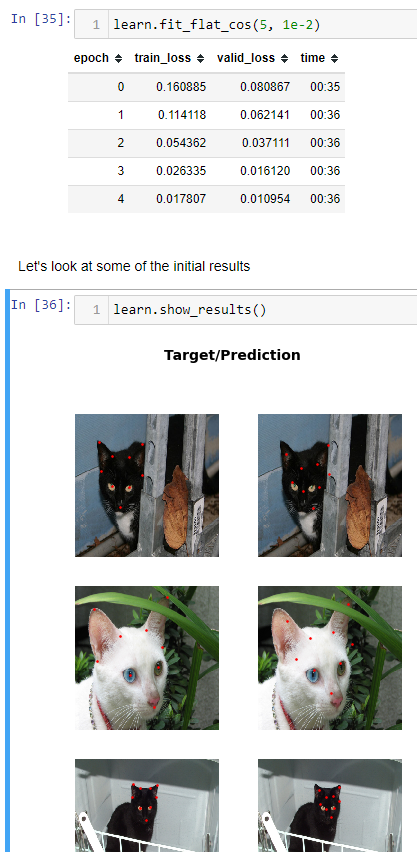
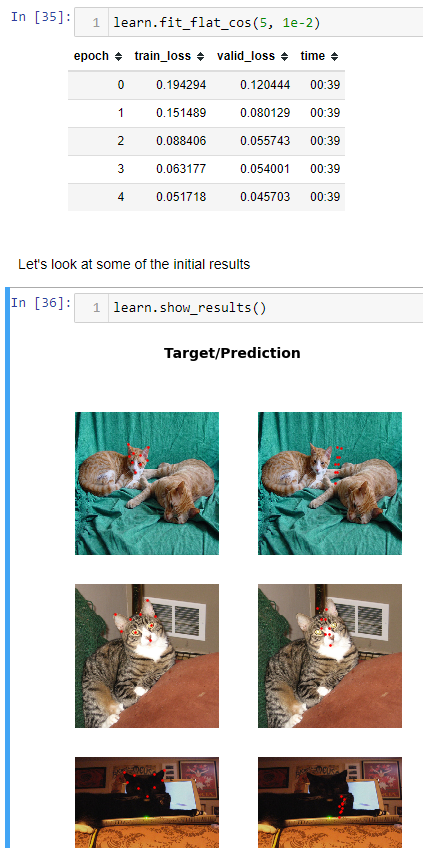
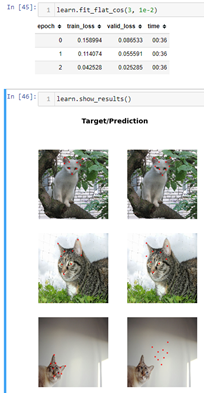
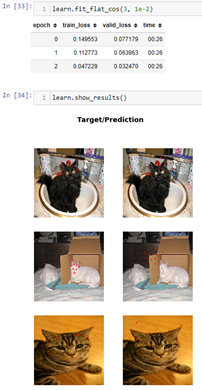
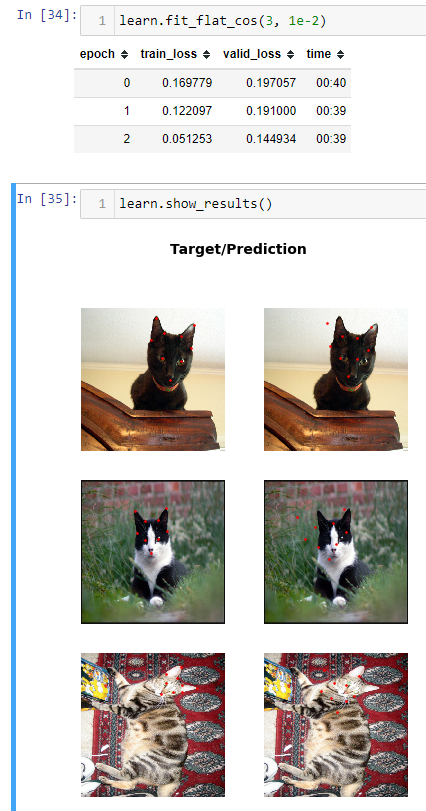
ok so it looks like theres definitely something with Flip() in batch transforms. im going to show them all because 0.0.17 with all batch tfms looks like its the best compared to 0.0.29 using one of the batch tfms. it seems like itd be easier for 0.0.29 to be better since theres only 3 epochs and one batch tfm.
@pattyhendrix the next step is to look at the outputs from just using flip, are any of them going outside of -1, 1.? I’ll look and see if flip’s behavior changed lately, but I have not noticed a major change to that specific augmentation. Only big difference is flip’s p was taken from 0.5 to 1.0, so to properly recreate it we should make flip’s p 0.5 (It’s default p was adjusted, so do Flip(p=0.5) (and verify that it is 0.5 when running it by checking the dls.after_batch. This may not actually need to be a thing, but this would be what I first check
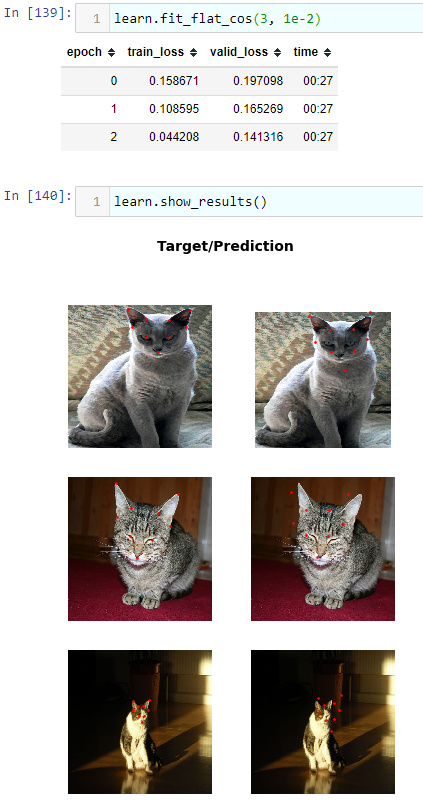
its like 3 seconds slower than 0.0.17 and the valid loss is way worse but the predictions look ok. not as good as 0.0.17, but better than 0.0.17 if it had the valid loss of 0.0.29