Is there a way to generate the Nietzsche with one or a few given words? Say, if I want a Nietzsche-like comment about horses, is there a way I can make sure that the generated text would contain “horses”?
You can’t be sure of the results, but you can make the starting phrase something about horses.
Thanks @jeremy. So there isn’t a known way to inject “horses” in the middle of the generated text? – That would be surprising, given that one can always run the RNN on a training text that’s reversed.
A related question: how about generating text with the constraint that certain words cannot be used, or, equivalently, only words from a given set can be used? Is that feasible?
You need to go beyond what we learnt in class to do this, but it is possible. This paper shows a extremely effective method: https://www.aclweb.org/anthology/D16-1126
Here’s a poem created using this method from the word ‘Turing’:

Not bad! 
2 Likes
I am also getting ’ ’ as predictions. Any luck finding the problem area?
@genkiro, @kelin-christi, @idano, @ozym4nd145
I started the training with the default learning rate and it gave a loss of 2.15 after 4 epoch and gave the prediction same as @jeremy 's notebook.
4 Likes
So it’s a poem about Turing but didn’t mention Turing. I didn’t know a computer could be so subtle… 
1 Like
@himanshu Great thanks for that:-
I recompiled the model ran 4 epochs with out setting the learning rate and got a 2.17 loss and the correct outputs in the ‘Test model section’. I then went back and ran another 4 epochs with a learning rate of 0.01 and got a loss of 2.09 and same ‘Test model’ result
Hi @Manoj, I was having the same question , were you able to figure out why ?
Those look like overlapping sequences to me?..
Hi guys, I have a question in number of model parameters
- There is a difference in the number of parameters when building layers by hand v.s using keras’s SimpleRNN(),
The number of parameters should be (input_to_embedding params) + (embedding_to_hidden params) + (hidden_to_hidden params) + (hidden_to_output params), where
a) input_to_embedding params = vocab_sizen_fac,
b) embedding_to_hidden params = n_facn_hidden + n_hidden,
c) hidden_to_hidden params = n_hiddenn_hidden + n_hidden,
d) hidden_to_output params = n_hiddenvocab_size + vocab_size
so the total is (8642) + (42256 + 256) + (256256 + 256) + (25686 + 86) = 102514.It checks out perfectly with the individual layer building way, but when using keras’s SimpleRNN , the number of parameters are different.
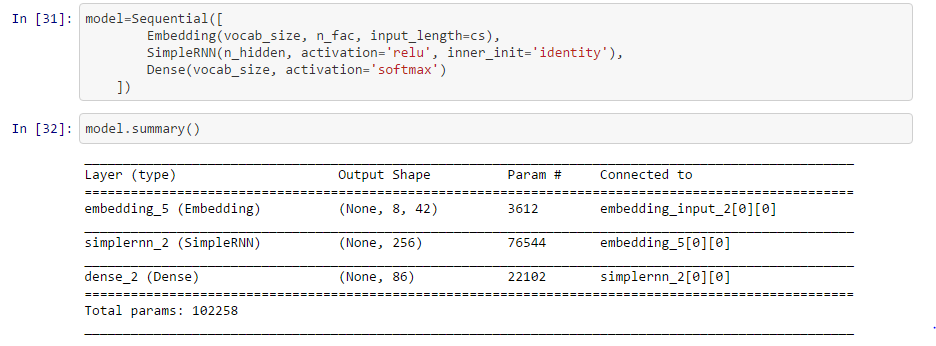
There’s no need for 2 separate bias vectors - just one is enough.
1 Like
Hi @jeremy, in the notebook when the sequence length is 3,
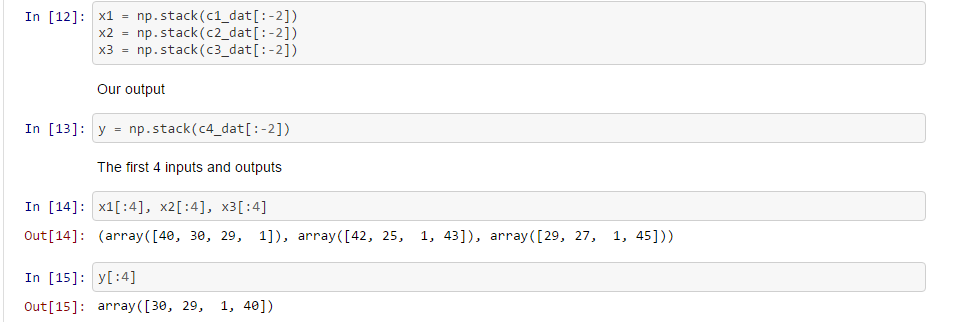
where x1 = [char0, char3, char6, char9, …]
x2 = [char1, char4, char7, char10,… ]
x3 = [char2, char5, char8, char11,…]
y = [char3, char6, char9, char12,…]
why not have overlapping training data like this
x1 = [char0, char1, char2, char3, …]
x2 = [char1, char2, char3, char4, …]
x3 = [char2, char3, char4, char5, …]
y = [char3, char4, char5, char6, …]
will there be gradient explosion/vanishing with having majorly overlapping examples ?
Thank You
I have a question, why the output of RNN: “y_rnn” needs an additional dimension:
y_rnn=np.expand_dims(np.stack(ys, axis=1), -1
plz
@jeremy, For example we have a sequence “abcdefg”. In this case you are considering only two sequences “abcd” and “defg”. I was wondering why you didn’t use n-grams such as “abcd”, “bcde”, “cdef”, “defg” as training data rather than only two sequences we are using as mentioned above.
Hi,
I had a same problem with u, would u plz tell me how to deal with it specifically:blush:
Thank a lot
Hi @yashkatariya, I made some changes to MixIterator as below
class MixIterator(object):
def __init__(self, iters):
self.iters = iters
self.multi = type(iters) is list
if self.multi:
self.N = sum([it.N for it in self.iters])
else:
self.N = sum([it.N for it in self.iters])
def reset(self):
for it in self.iters: it.reset()
def __iter__(self):
return self
def next(self, *args, **kwargs):
if self.multi:
nexts = [next(o) for o in self.iters]
n0 = np.concatenate([n[0] for n in nexts])
n1 = np.concatenate([n[1] for n in nexts])
return (n0, n1)
else:
nexts = [next(it) for it in self.iters]
n0 = np.concatenate([n[0] for n in nexts])
n1 = np.concatenate([n[1] for n in nexts])
return (n0, n1)
I was able to run fit_generator() on it but it is giving exceptions like below
Epoch 1/3
70000/70000 [==============================] - 126s - loss: 0.4123 - acc: 0.8791 - val_loss: 0.2753 - val_acc: 0.9214
Epoch 2/3
69968/70000 [============================>.] - ETA: 0s - loss: 0.2924 - acc: 0.9167
/home/tftuts/anaconda2/lib/python2.7/site-packages/keras/engine/training.py:1480: UserWarning: Epoch comprised more than samples_per_epoch samples, which might affect learning results. Set samples_per_epoch correctly to avoid this warning.
warnings.warn('Epoch comprised more than ’
70048/70000 [==============================] - 126s - loss: 0.2925 - acc: 0.9167 - val_loss: 0.2548 - val_acc: 0.9279
Epoch 3/3
70048/70000 [==============================] - 126s - loss: 0.2816 - acc: 0.9212 - val_loss: 0.2445 - val_acc: 0.9304
have you figured it out ?
You don’t need to worry about this - it doesn’t hurt anything.
Can you summarize the changes you made?
Hi @jeremy,
I changed lines
if self.multi:
self.N = sum([it[0].N for it in self.iters])
to
if self.multi:
self.N = sum([it.N for it in self.iters])
I was getting an error that says I cannot index the item so I removed the [0]
and I also changed the lines
def next(self, *args, **kwargs):
if self.multi:
nexts = [[next(it) for it in o] for o in self.iters]
to
def next(self, *args, **kwargs):
if self.multi:
nexts = [next(o) for o in self.iters]
Thank you
When I run the lesson6.ipynb in aws, somehow it offen appear ‘kernel-dead’ situation like this:
while running epochs, it seems “stop” running(the progress bar doesn’t move anymore), but the star mark still here , no matter how long I wait, nothing happen again.
Therefore I have to reconnect the kernel and run that cell again, but same problem again.
I left alone the problem, run the get_next function to see if it’s trained already, but I got nothing.
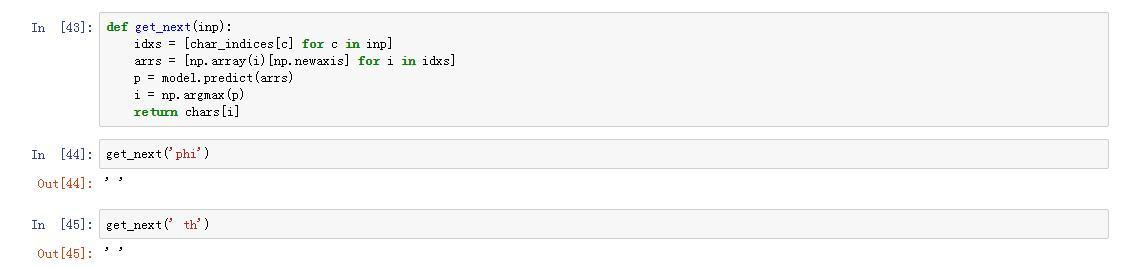
What should I do?