Lesson 6 wiki page and video are now available.
Please post your questions and comments here! (Also note that there is an ongoing discussion about the purpose of RNNs, and learning Theano.
Lesson 6 wiki page and video are now available.
Please post your questions and comments here! (Also note that there is an ongoing discussion about the purpose of RNNs, and learning Theano.
Thanks Jeremy!
Quick question – I know it was discussed already, but I forgot the reasoning. We’re setting shuffle=False on .fit with LSTMs.
Is this because of sparse_categorical_entropy? Would keras not be able to return the right output if we didn’t set shuffle to False?
It’s because of stateful=True
Right, that makes total sense.
Hi again,
I’m trying to create an artificial intellegence Trump tweet generator using the stateful model of lesson 6 to see if it’s more or less intellegent than the actual human.
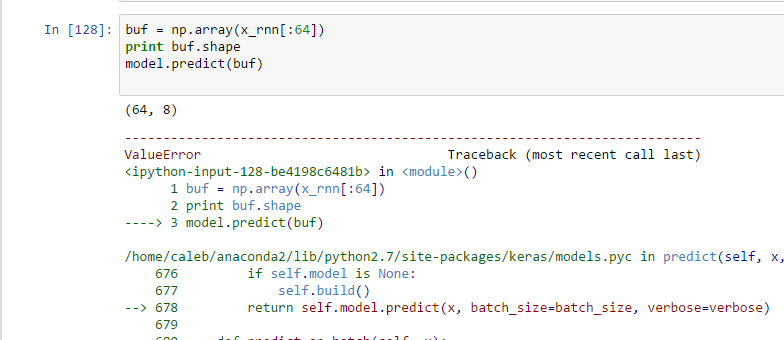
The model fits great (maybe too well… ), but I can’t seem to call model.predict in any way that works.
Here’s what I’m doing:
which seems to match your lesson 6 mode.
I can train it on my text corpus, just like you did:
However, I can’t figure out what the right parameters are to the model.predict function.
If I pass in the wrong dimension array, I get an error saying the dimensions should be (64, 8)
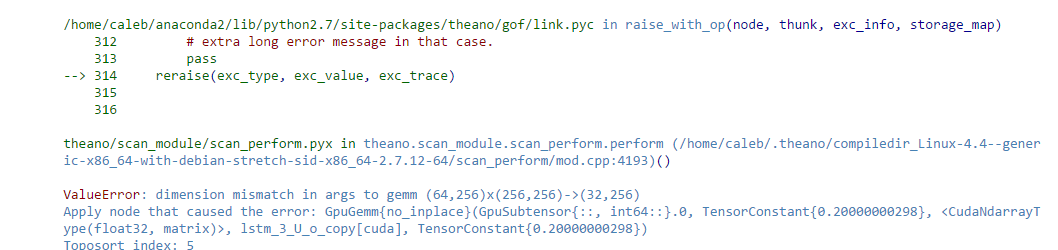
But, when I pass in an array of (64, 8), I get an enourmous stack dump that doesn’t really say anything I can grok.
Here I’m passing an array of 64,8, and getting the following error:
and farther down this:
Specifically, it says there’s a dimension mismatch, but I can’t figure out what size array I’m suspposed to pass in.
Any ideas?
You can download the full notebook here
Thanks again,
-caleb
Right, you can’t really just call model.predict - but if you look at the nietzsche generators you’ll see that I write some functions to deal with the details of that. Perhaps you can borrow from them? e.g. https://github.com/fastai/courses/blob/master/deeplearning1/nbs/char-rnn.ipynb
Oh, there it is! I knew I was missing something.
Thanks,
-C
@rachel I was going through Lesson 6, looking in to the char-rnn.ipynb example and noticed that the notebook that Jeremy presents in the lesson is different to the char-rnn.ipynb notebook uploaded to GitHub.
As an example, Jeremy’s version has a function called def run_epochs(), etc. Is it possible that the version uploaded to GitHub is an older one?
Thanks a lot!
Did anyone ever had a problem where get_next() keeps on predicting ' '? I thought it was overfitting but decreasing the learning rate greatly did not help. Variables x1, x2, x3, y looks correct too.
I’m having the same issue. Any luck debugging?
@jeremy @rachel
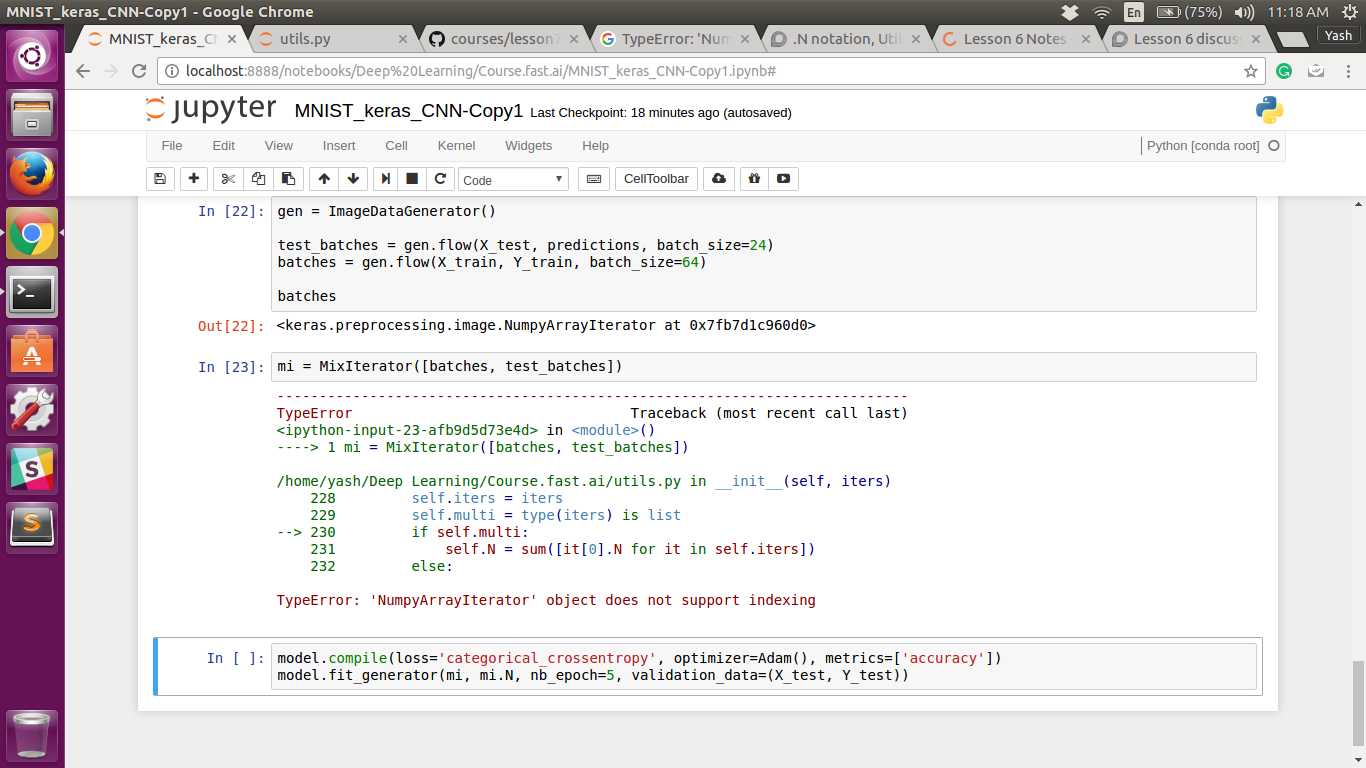
I was going through the MixIterator class and tried to use it, but I am getting this error.
Can someone please help me with this?
Hi All,
I have been working through the lesson 6 notebook, and I am getting errors that I believe may be Keras related. After I examined the code thoroughly, this appears to me like it should work.
Our first RNN with keras!
n_hidden, n_fac, cs, vocab_size = (256, 42, 8, 86)
This is nearly exactly equivalent to the RNN we built ourselves in the previous section.
model=Sequential([
Embedding(vocab_size, n_fac, input_length=cs),
SimpleRNN(n_hidden, activation='relu', inner_init='identity'),
Dense(vocab_size, activation='softmax')
])
model.summary()
Layer (type) Output Shape Param # Connected to
embedding_4 (Embedding) (None, 8, 42) 3612 embedding_input_1[0][0]
simplernn_1 (SimpleRNN) (None, 256) 76544 embedding_4[0][0]
dense_7 (Dense) (None, 86) 22102 simplernn_1[0][0]
Total params: 102,258
Trainable params: 102,258
Non-trainable params: 0
model.compile(loss=‘sparse_categorical_crossentropy’, optimizer=Adam())
model.fit(np.stack(xs,1), y, batch_size=64, nb_epoch=8)
ValueError Traceback (most recent call last)
in ()
----> 1 model.fit(np.stack(xs,1), y, batch_size=64, nb_epoch=8)
/home/ubuntu/anaconda2/lib/python2.7/site-packages/keras/models.pyc in fit(self, x, y, batch_size, nb_epoch, verbose, callbacks, validation_split, validation_data, shuffle, class_weight, sample_weight, initial_epoch, **kwargs)
670 class_weight=class_weight,
671 sample_weight=sample_weight,
–> 672 initial_epoch=initial_epoch)
673
674 def evaluate(self, x, y, batch_size=32, verbose=1,
/home/ubuntu/anaconda2/lib/python2.7/site-packages/keras/engine/training.pyc in fit(self, x, y, batch_size, nb_epoch, verbose, callbacks, validation_split, validation_data, shuffle, class_weight, sample_weight, initial_epoch)
1114 class_weight=class_weight,
1115 check_batch_axis=False,
-> 1116 batch_size=batch_size)
1117 # prepare validation data
1118 if validation_data:
/home/ubuntu/anaconda2/lib/python2.7/site-packages/keras/engine/training.pyc in _standardize_user_data(self, x, y, sample_weight, class_weight, check_batch_axis, batch_size)
1027 self.internal_input_shapes,
1028 check_batch_axis=False,
-> 1029 exception_prefix=‘model input’)
1030 y = standardize_input_data(y, self.output_names,
1031 output_shapes,
/home/ubuntu/anaconda2/lib/python2.7/site-packages/keras/engine/training.pyc in standardize_input_data(data, names, shapes, check_batch_axis, exception_prefix)
110 ’ to have ’ + str(len(shapes[i])) +
111 ’ dimensions, but got array with shape ’ +
–> 112 str(array.shape))
113 for j, (dim, ref_dim) in enumerate(zip(array.shape, shapes[i])):
114 if not j and not check_batch_axis:
ValueError: Error when checking model input: expected embedding_input_1 to have 2 dimensions, but got array with shape (75110, 8, 1)
I actually encountered this error 3 different times in the lesson 6 notebook - the first above (Our first RNN with keras), the second being Sequence model with keras, and the third the Stateful model with keras. I am using Keras v. 1.2.2 with Theano 0.9.0rc4 on my AWS GPU instance (with the K80).
Has anyone else run into this, or have any ideas?
Thanks, Christina
It’s rather hard to read that code. Perhaps you can put it in a code block? Start the block with:
```python
and end it with:
```
Or just put it in a gist.
Thanks, here it is:
n_hidden, n_fac, cs, vocab_size = (256, 42, 8, 86)
model=Sequential([
Embedding(vocab_size, n_fac, input_length=cs),
SimpleRNN(n_hidden, activation='relu', inner_init='identity'),
Dense(vocab_size, activation='softmax')
])
model.compile(loss='sparse_categorical_crossentropy', optimizer=Adam())
model.fit(np.stack(xs,1), y, batch_size=64, nb_epoch=8)
This is straight out of the lesson 6 notebook.
Thanks, Christina 
In lesson6.ipynb, when building a 3 char model on “Nietzsche”, @jeremy used non-overlapping sequences of characters for training.
cs=3
c1_dat = [idx[i] for i in xrange(0, len(idx)-1-cs, cs)]
c2_dat = [idx[i+1] for i in xrange(0, len(idx)-1-cs, cs)]
c3_dat = [idx[i+2] for i in xrange(0, len(idx)-1-cs, cs)]
c4_dat = [idx[i+3] for i in xrange(0, len(idx)-1-cs, cs)]
Why did he use non-overlapping sequences?
Using overlapping sequences might give us more training data as well as better context.
I think the problem lies here
model.fit(np.stack(xs,1), y, batch_size=64, nb_epoch=8)
I changed it to
model.fit(np.concatenate(xs,axis=1), y, batch_size=64, nb_epoch=8)
np.stack adds another dimension to the input.
Join a sequence of arrays along a new axis.
The `axis` parameter specifies the index of the new axis in the dimensions
of the result. For example, if ``axis=0`` it will be the first dimension
and if ``axis=-1`` it will be the last dimension.
.. versionadded:: 1.10.0
Parameters
----------
arrays : sequence of array_like
Each array must have the same shape.
axis : int, optional
The axis in the result array along which the input arrays are stacked.
Returns
-------
stacked : ndarray
The stacked array has one more dimension than the input arrays.
xs is a list 8 in length of 75110 row vectors
so I think the idea is to change the list into a matrix 75110 row x 8 columns hence the axis parameter of ‘1’
I used np.concatenate(xs,1) which seems to correct the error
NOTE : this applies to the section Our first RNN with keras! At the time I did not complete the lesson. Now I have my own home box I am finishing of the lesson so please bear that in mind
@Christine No Problem.
Why it was np.stack in the first place I have no idea. What has changed between when it was working and not, I am not sure either. I am using keras 1.2.2. and theano 0.8.2. I seem to be getting results in the same ball park as the downloaded notebook. I am not actually using cuda features so many parts of the notebooks are quite slow but mostly in this notebook I can get 60s epochs. I am not sure if I am getting getting floating point errors by not using a GPU or it could be down to randomness as nowhere do we set any seeds.
Anyway I guess the fix is legitimate, anyone care to comment.
EDIT: In the notebook section ‘One-hot sequence model with keras’ using np.stack works okay
I am having same issue. Were you eventually able to predict anything else?
Thanks
Same problem here. Did you find the solution?