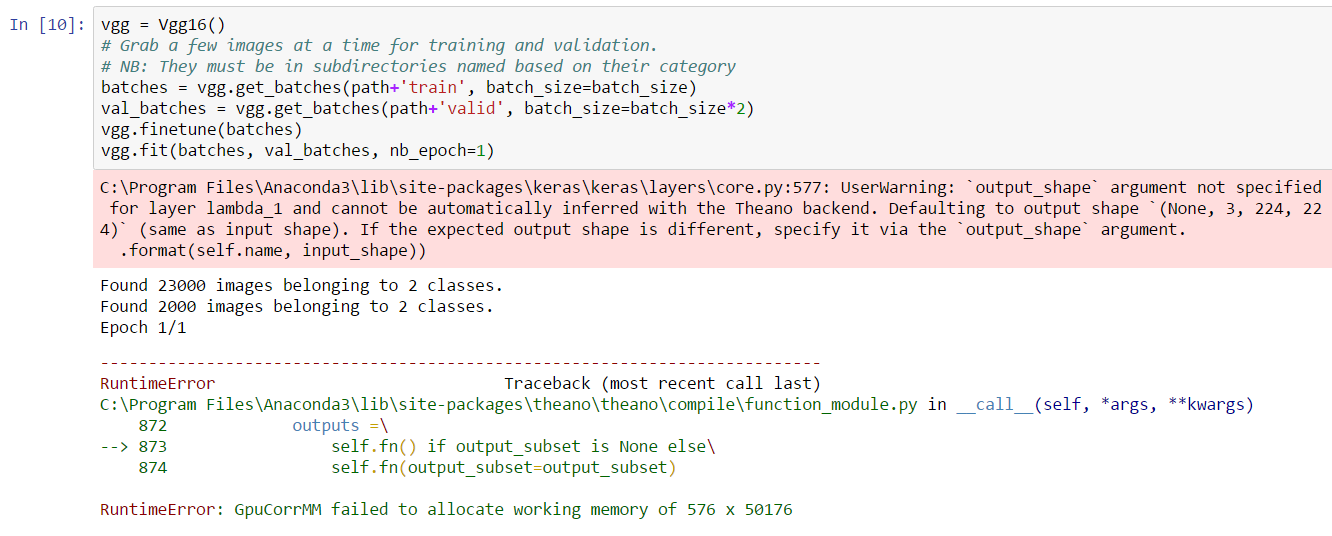
I am getting this error.
Cuda error: GpuElemwise node_1a4d88a71be2a74afabcec27cbb0fc5c_0 Sub: out of memory.
n_blocks=30 threads_per_block=256
Call: kernel_Sub_node_1a4d88a71be2a74afabcec27cbb0fc5c_0_Ccontiguous<<<n_blocks, threads_per_block>>>(numEls, local_dims[0], local_dims[1], local_dims[2], i0_data, local_str[0][0], local_str[0][1], local_str[0][2], i1_data, local_str[1][0], local_str[1][1], local_str[1][2], o0_data, local_ostr[0][0], local_ostr[0][1], local_ostr[0][2])
Apply node that caused the error: GpuElemwise{Sub}[(0, 0)](GpuFromHost.0, CudaNdarrayConstant{[[[[ 123.68 ]]
[[ 116.779]]
[[ 103.939]]]]})
Toposort index: 41
Inputs types: [CudaNdarrayType(float32, 4D), CudaNdarrayType(float32, (True, False, True, True))]
Inputs shapes: [(32, 3, 224, 224), (1, 3, 1, 1)]
Inputs strides: [(150528, 50176, 224, 1), (0, 1, 0, 0)]
Inputs values: [‘not shown’, CudaNdarray([[[[ 123.68 ]]
[[ 116.779]]
[[ 103.939]]]])]
Outputs clients: [[GpuSubtensor{::, ::int64}(GpuElemwise{Sub}[(0, 0)].0, Constant{-1})]]
HINT: Re-running with most Theano optimization disabled could give you a back-trace of when this node was created. This can be done with by setting the Theano flag ‘optimizer=fast_compile’. If that does not work, Theano optimizations can be disabled with ‘optimizer=None’.
HINT: Use the Theano flag ‘exception_verbosity=high’ for a debugprint and storage map footprint of this apply node.