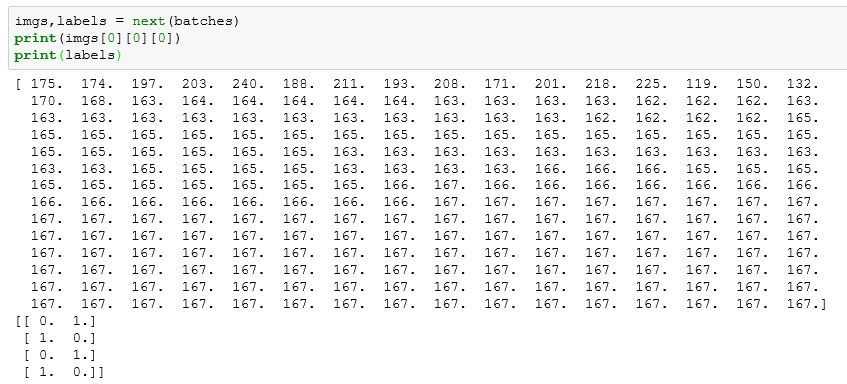
Unable to load the weights.
Getting the following error.
IOError Traceback (most recent call last)
in ()
----> 1 vgg = Vgg16()
C:\Users\Sai Kiran\courses\deeplearning1\nbs\vgg16.pyc in init(self)
31 def init(self):
32 self.FILE_PATH = ‘http://www.platform.ai/models/’
—> 33 self.create()
34 self.get_classes()
35
C:\Users\Sai Kiran\courses\deeplearning1\nbs\vgg16.pyc in create(self)
81
82 fname = ‘vgg16.h5’
—> 83 model.load_weights(get_file(fname, self.FILE_PATH+fname, cache_subdir=‘models’))
84
85
C:\Users\Sai Kiran\Anaconda2\lib\site-packages\keras\engine\topology.pyc in load_weights(self, filepath, by_name)
2693 ‘’'
2694 import h5py
-> 2695 f = h5py.File(filepath, mode=‘r’)
2696 if ‘layer_names’ not in f.attrs and ‘model_weights’ in f:
2697 f = f[‘model_weights’]
C:\Users\Sai Kiran\Anaconda2\lib\site-packages\h5py_hl\files.py in init(self, name, mode, driver, libver, userblock_size, swmr, **kwds)
270
271 fapl = make_fapl(driver, libver, **kwds)
–> 272 fid = make_fid(name, mode, userblock_size, fapl, swmr=swmr)
273
274 if swmr_support:
C:\Users\Sai Kiran\Anaconda2\lib\site-packages\h5py_hl\files.py in make_fid(name, mode, userblock_size, fapl, fcpl, swmr)
90 if swmr and swmr_support:
91 flags |= h5f.ACC_SWMR_READ
—> 92 fid = h5f.open(name, flags, fapl=fapl)
93 elif mode == ‘r+’:
94 fid = h5f.open(name, h5f.ACC_RDWR, fapl=fapl)
h5py_objects.pyx in h5py._objects.with_phil.wrapper (C:\Minonda\conda-bld\h5py_1474482483473\work\h5py_objects.c:2705)()
h5py_objects.pyx in h5py._objects.with_phil.wrapper (C:\Minonda\conda-bld\h5py_1474482483473\work\h5py_objects.c:2663)()
h5py\h5f.pyx in h5py.h5f.open (C:\Minonda\conda-bld\h5py_1474482483473\work\h5py\h5f.c:1951)()
IOError: Unable to open file (Truncated file: eof = 41140224, sblock->base_addr = 0, stored_eoa = 553482496)