While discussing our Semantic Transfer demo, @Even brought to my attention Mask R-CNN, a new paper from Facebook AI. A few of you have expressed interest in trying to implement this (@Matthew, @sravya8, @jeremy), so I wanted to use this thread to share our progress toward an implementation. This post is a wiki, so feel free to make updates as our understanding improves.
Here are my initial notes on the various components we need to understand and implement.
Key Links
- Mask R-CNN Paper
- Great survey paper of current techniques for object detection
- CS231 Object Detection Slides and Video
- CS231 Segementation Slides and Video
Related Papers
The building blocks of Mask R-CNN. Papers and Githubs (I have not closely reviewed the code).
- ResNet - Paper, Keras, Pytorch
- ResNext - Paper, Github (Not required, but improves performance)
- R-CNN - Paper
- Fast R-CNN - Paper, Slides, Pycaffe, Tensorflow
- Faster R-CNN - Paper, Slides, Pycaffe, Pytorch, Tensorflow
- RoIPooling - Pytorch, Theano
- R-FCN - Paper, Pycaffe
- FPN (Feature Pyramid Network) - Paper
- Spacial Transformer Networks - Paper, PyTorch, Tensorflow, Tutorial
Key Mask R-CNN Improvements
- RoIAlign Layer - Improved version of RoIPool Layer
- Mask Branch - Segmentation prediction on Region on Interest in parallel with classification/detection
- Decouple Mask and Class Prediction using Binary Sigmoid Activations vs Multi-class Softmax
Implementation Details
Quick facts I was able to extract from a cursory review
Two part architecture
- Feature Extraction (processing image and save activation at specific layer)
- Segmentation (bounding box, class, mask prediction on a “Region of Interest”)
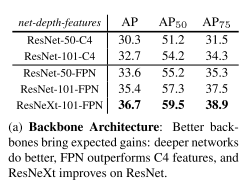
Feature Extraction Models They Tried
- ResNet and ResNext at depths of 50 or 101. Extracted the activations at the final convolutional layer at the 4th stage: “C4”
- Feature Pyramid Network (FPN) in combination with ResNet
Training Parameters
- Training Set: 80K, Validation Set: 35K, MiniValidation Set (Ablations): 5K
- 160K training iterations (160K mini-batches)
- Training time: 32 hours, 8 GPU machine, with ResNet-50-FPN architecture
- Learning Rate 0.02 until 120K iterations, then reduced to 0.002
- Single Image Segmentation time: 200ms on 1 Tesla M40 GPU
- Weight decay: .0001
- Momentum: 0.9
- Mini-batches of 2 images per GPU
- Resized inputs so shorted edge (width/height) was 800 pixels.
Loss Function
- Loss Function = Loss_class + Loss_box + Loss_mask
- Mask loss only considered for the ground truth label
- Average Binary Cross-Entropy Loss
- Per-Pixel Sigmoid Activation
- Decision Boundary 0.5 (for class prediction)
Dataset
Coco Objects in Context
http://mscoco.org/dataset
Paper explaining dataset
200K annotated images
80 instance categories
1.2M instances
Torrent Download?



{kind=link}