OK sounds like we need to do both! Let’s see how many people are around, and we can either go in parallel or serial.
I don’t think I can teach something where we just implement something on top of a black box, so I’d want to fully understand what we’re building on and be able to reimplement it!
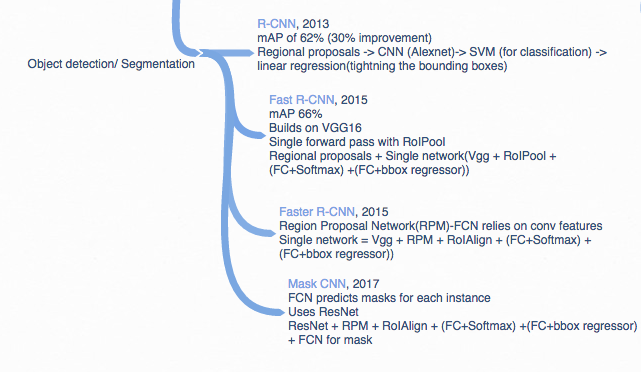
Looking at the Faster R-CNN implementations (PyTorch, Tensorflow, Caffee), they only include bounding box predictions, unlike the paper describes. I don’t think anyone has coded the segmentations part? In that case instance segmentation would also have to be implemented and adds to the difficulty. https://github.com/rbgirshick/py-faster-rcnn/issues/327
Considering the above, let’s call Friday an “implementation day” and let people work on something they’re interested in. We can use each other for support, but work on different projects if desired.
I just realized that I met @brendan yesterday during explaining the paper! (nice to meet/e-meet you, we should talk next time, this time I had to leave early)
@jeremy: Yes, I can complete the 100 layers of Tirmasu and I will perhaps fix it this weekend, 2 big issues:
the theano has recursion limit issues, which I will change to Tensorflow.
Building a ConvNet with 103 layers requires about 10 minutes to debug often times.
I review that paper while back, personal notes here and code
For the Mask-R-CNN, I’m about to post my notes tomorrow, since I went through all the other 8 Papers from introducing R-CNN >> Fast RCNN, Faster RCNN >> Faster RCNN + Pyramind >> Faster RCNN for real-time Object detcion.
Also, for the code, I have an incomplete implantation of the that model too (just not open source yet), I’m reaching out to the authors to explain to me how the RoI Align actually work and gets computed. (Since as I was asking the rest of the 30 people from study group, leveling Pixel-To-Pixel Segmentation with a parallel ConvNet doesn’t seem to add up together. the FCN or FPN have different loss + input style from the ConvNet in Parallel.
In terms of the theoretical understanding, let me know if you have questions:
Since there isn’t exactly much difference from the previous work that those 2, Tirmasu and the Mask R-CNN have changed, except re-arrangement of tasks + network overlays.
The 100-Tirmasu-Layers, aka FC-DenseNets, learn very very low level features in the manner of this Encode-Decode model, where the Decode is manly using DeconvNets, most of the previous work were using mostly Pooling + Subsampling alone.
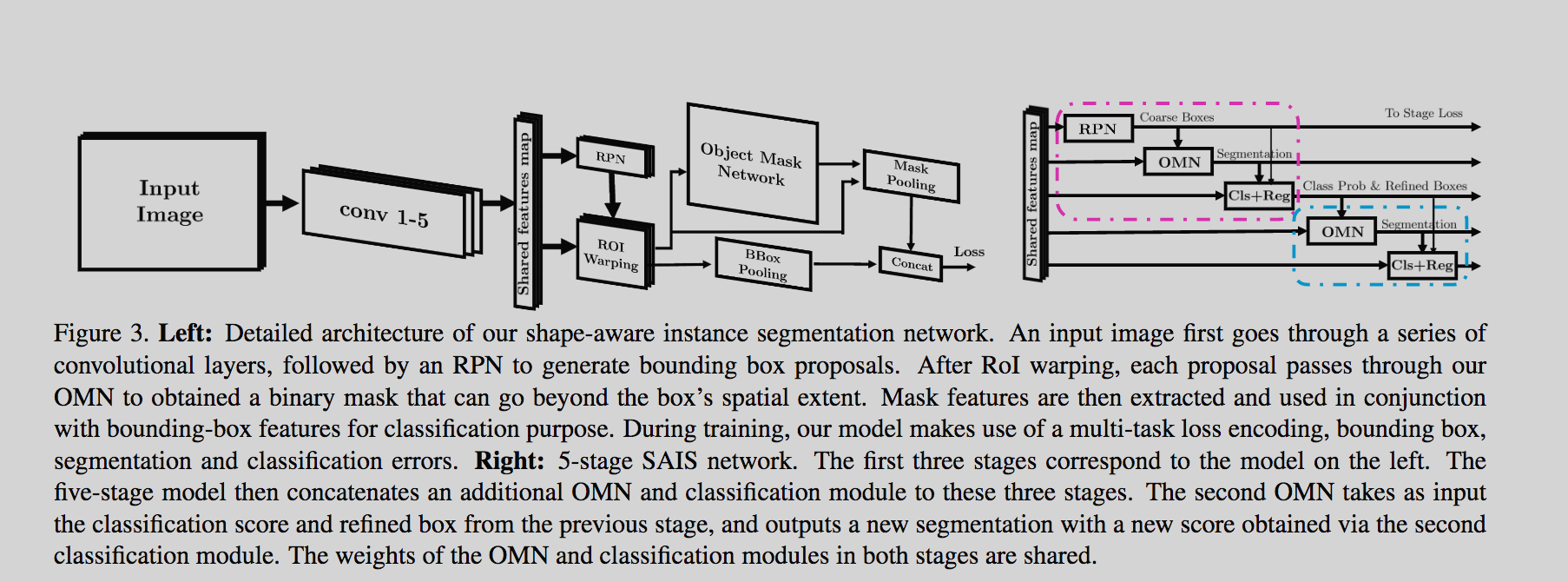
For Mask R-CNN: the creme de la creme is the 3rd masking task being ran in parallel to object detection as a classification problem and bounding box prediction as a regression problem. Meanwhile, the 3rd branch, Task known here as the masking goes through another series of ConvNets and then making it’s mind up. (Rest of the details can be distracting, but that’s one main way to arrange the information in the series)
I notice that the Mask R-CNN paper doesn’t mention the FC-DenseNet paper, and that the FC-DenseNet authors didn’t test their architecture on MSCOCO (although they mentioned MSCOCO in the paper). Is this because Mask R-CNN and MSCOCO are about instance segmentation while FC-DenseNets only do semantic segmentation?
Mask R-CNN focuses on the COCO challenge here, Which essentially follows a certain criteria of measuring Error Rate per the tasks given. Meanwhile, The FC-Densenet (100 Layers Tirmasu) paper focuses on the urban scene benchmark datasets such as CamVid and Gatech,
The dataset MSCOCO itself can be used for wide range challenges and often introduced as benchmark against other datasets (if the paper is not about the COCO challenge)
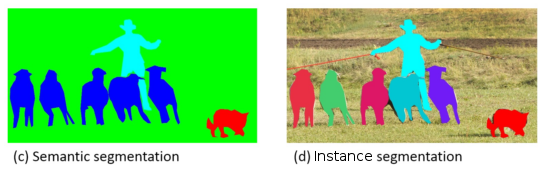
The process of doing Semantic Segmentation can be a prior task to do Instance segmentation, since finding an instance of a class ( as in dog 1, dog 2, … dog n) in the picture requires some level of semantic understanding of the image.
After all, the Mask R-CNN is an evident result for having a simpler model that one task can help the other out to accomplish the full
@jeremy I’ll help you with Tiramisu in PyTorch. I think it’s doable and will be more fun. Mask R-CNN is a great paper, but it is significantly more complex and we would only be able to tackle a very tiny part.
We can build on the PyTorch DenseNet model and the author’s Tiramisu implementation in Lasange.
@matthew Tiramisu is designed for semantic segmentation. Mask R-CNN is more extensible, but I haven’t been able to find an implementation of instance segmentation among its predecessors (Fast, Faster, RCNN)
@brendan awesome! Are you free on the weekend? I am - so I’m hoping to keep hacking throughout the weekend. That might be enough time to do both properly…
Yep! I’ve been reading and Densenets look really promising. Should be easier/faster to train given the fewer parameters. I’ll start another wiki thread for Tiramisu later today so we can share notes.
As you can see, it does Instance Segmentation and uses almost the same network:
DeepConvs + RPNs to pick the Region of Interest + Bounding box and lastly the Instance Segmentation.
The Mask R-CNN uses a much simpler and modular network to do the task. Modular as in, the ResNeXt can be swapped out and swapped in, meanwhile the layers of Instance Segmentation can be increases and reduced without making it effect the Object Detection + Bounding Box.
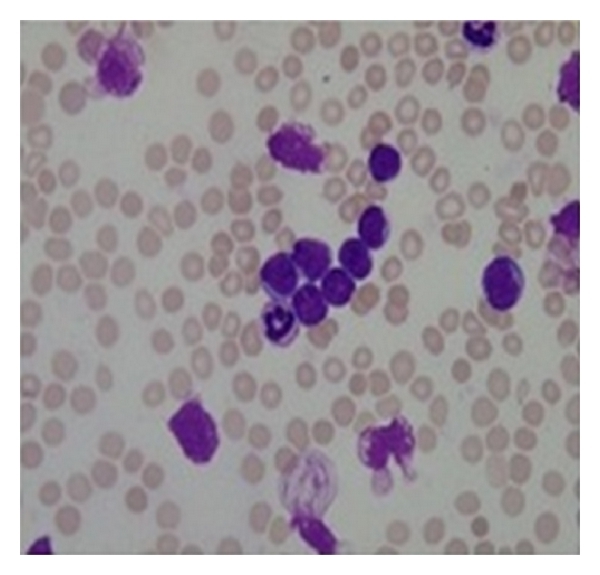
What technique Should I use to Identify White Blood Cells(Purple color) in a Blood Smear using Deep Learning …I Have To show Bounding Boxes and Also Count the Numbers…

 often times.
often times.