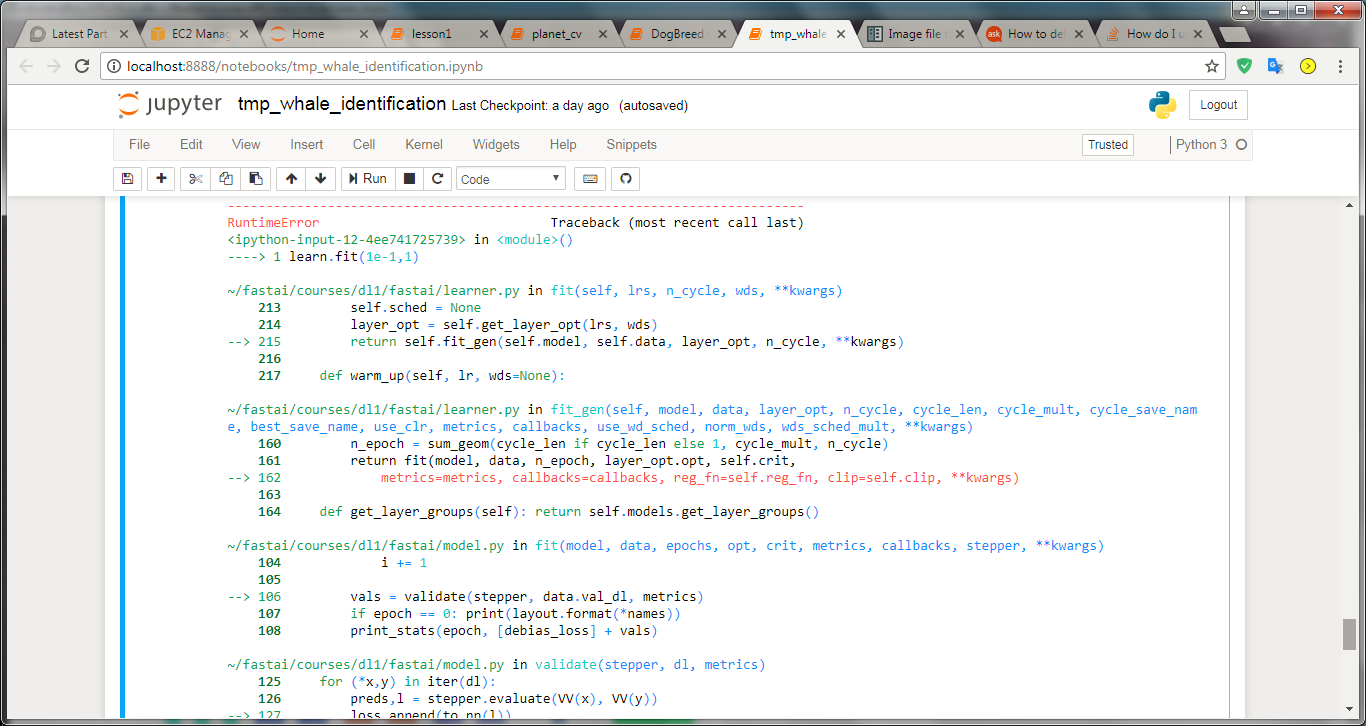
Hi All - I’m also getting this error and have tried reducing the batch size & image size with no luck. I’m using the “whale-categorization-playground” dataset from Kaggle and get this error when I run the line below with bs=26, sz=224 arch=reznext101_64.
Thank you!
learn = ConvLearner.pretrained(arch, data, precompute=True)
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-62-3bf7b4e76984> in <module>()
1 # run first pass
----> 2 learn = ConvLearner.pretrained(arch, data, precompute=True)
~/fastai/courses/dl1/fastai/conv_learner.py in pretrained(cls, f, data, ps, xtra_fc, xtra_cut, custom_head, precompute, **kwargs)
106 def pretrained(cls, f, data, ps=None, xtra_fc=None, xtra_cut=0, custom_head=None, precompute=False, **kwargs):
107 models = ConvnetBuilder(f, data.c, data.is_multi, data.is_reg,
--> 108 ps=ps, xtra_fc=xtra_fc, xtra_cut=xtra_cut, custom_head=custom_head)
109 return cls(data, models, precompute, **kwargs)
110
~/fastai/courses/dl1/fastai/conv_learner.py in __init__(self, f, c, is_multi, is_reg, ps, xtra_fc, xtra_cut, custom_head)
47 else: fc_layers = self.get_fc_layers()
48 self.n_fc = len(fc_layers)
---> 49 self.fc_model = to_gpu(nn.Sequential(*fc_layers))
50 if not custom_head: apply_init(self.fc_model, kaiming_normal)
51 self.model = to_gpu(nn.Sequential(*(layers+fc_layers)))
~/fastai/courses/dl1/fastai/core.py in to_gpu(x, *args, **kwargs)
43 USE_GPU=True
44 def to_gpu(x, *args, **kwargs):
---> 45 return x.cuda(*args, **kwargs) if torch.cuda.is_available() and USE_GPU else x
46
47 def noop(*args, **kwargs): return
~/anaconda3/envs/fastai/lib/python3.6/site-packages/torch/nn/modules/module.py in cuda(self, device)
214 Module: self
215 """
--> 216 return self._apply(lambda t: t.cuda(device))
217
218 def cpu(self):
~/anaconda3/envs/fastai/lib/python3.6/site-packages/torch/nn/modules/module.py in _apply(self, fn)
144 def _apply(self, fn):
145 for module in self.children():
--> 146 module._apply(fn)
147
148 for param in self._parameters.values():
~/anaconda3/envs/fastai/lib/python3.6/site-packages/torch/nn/modules/module.py in _apply(self, fn)
150 # Variables stored in modules are graph leaves, and we don't
151 # want to create copy nodes, so we have to unpack the data.
--> 152 param.data = fn(param.data)
153 if param._grad is not None:
154 param._grad.data = fn(param._grad.data)
~/anaconda3/envs/fastai/lib/python3.6/site-packages/torch/nn/modules/module.py in <lambda>(t)
214 Module: self
215 """
--> 216 return self._apply(lambda t: t.cuda(device))
217
218 def cpu(self):
~/anaconda3/envs/fastai/lib/python3.6/site-packages/torch/_utils.py in _cuda(self, device, async)
67 else:
68 new_type = getattr(torch.cuda, self.__class__.__name__)
---> 69 return new_type(self.size()).copy_(self, async)
70
71
RuntimeError: cuda runtime error (59) : device-side assert triggered at /opt/conda/conda-bld/pytorch_1518244421288/work/torch/lib/THC/generic/THCTensorCopy.c:20