I have no clue why the first layer is an LSTM nor what it does. I do not think his statement in the comments is correct that it is equivalent to a Dense layer.
It’s really cool though. Could it be that the remember / forget gates are still learned? Sort of like we are using the LSTM cell to take a look at the data and keep only the parts that are important?
Well, this is crazy. Don’t think I will be able to wrap my head around this as I don’t want to explore that keras layer further.
One way to find out would be rerunning the training with the Dense layer instead.
Either way, this is really helpful Thanks a lot @EricPB! I also find the part where the 561 vector is being fed into the model quite mind boggling. Intuitively feeding it something of shape [type_of_data x days_in_train] makes more sense. For instance, I think Lighzi stacked a vector of unit_sales and a vector of promo_days and some statistics I think to form something of dimensionality [3 x days_in_train]
I’m working (or my PC is ) on a lighter/faster version, with less epochs per step (15 max, so Callbacks probably can’t kick in), to experiment with different parameters, including the “why choose LSTM over Dense in the first layer”.
I’ll post a revised Jupyter Notebook on GitHub so everyone can experiment as well.
But:
As it is, you’ll still need at least 50Gb RAM to run it, due to the “Preparing Dataset” cells #24 to #27.
On my rig, this is not a big issue because I have 32Gb “real” RAM and allocated 140Gb “SWAP File” from the 1Tb Samsung 960 NVMe, so it’s rather painless. But if you don’t have a SWAP helping, the notebook may crash.
The whole kernel is without any comment, so expect some reverse-engineering work to figure out what is done by each cell.
The current open question for me: why did he choose to run 16 networks -or steps- ? Is it related to the duration of the Test set (ie 16 days) ? If I were to use his template for another project with a Test set of 25 days, should I need 25 networks ? Or just a coincidence ?
Errr… I’m pretty sure if you asked in the comments section on Kaggle, or on KaggleNoobs, someone will find the original culprit and get you an answer.
This is my humble opinion but I agree with it.
This kernel is based on senkin13’s kernel: https://www.kaggle.com/senkin13/lstm-starter. You can replace model.add(LSTM(512, input_shape=(X_train.shape[1],X_train.shape[2]))) with model.add(Dense(512, input_dim=X_train.shape[1])), I think there is no difference.
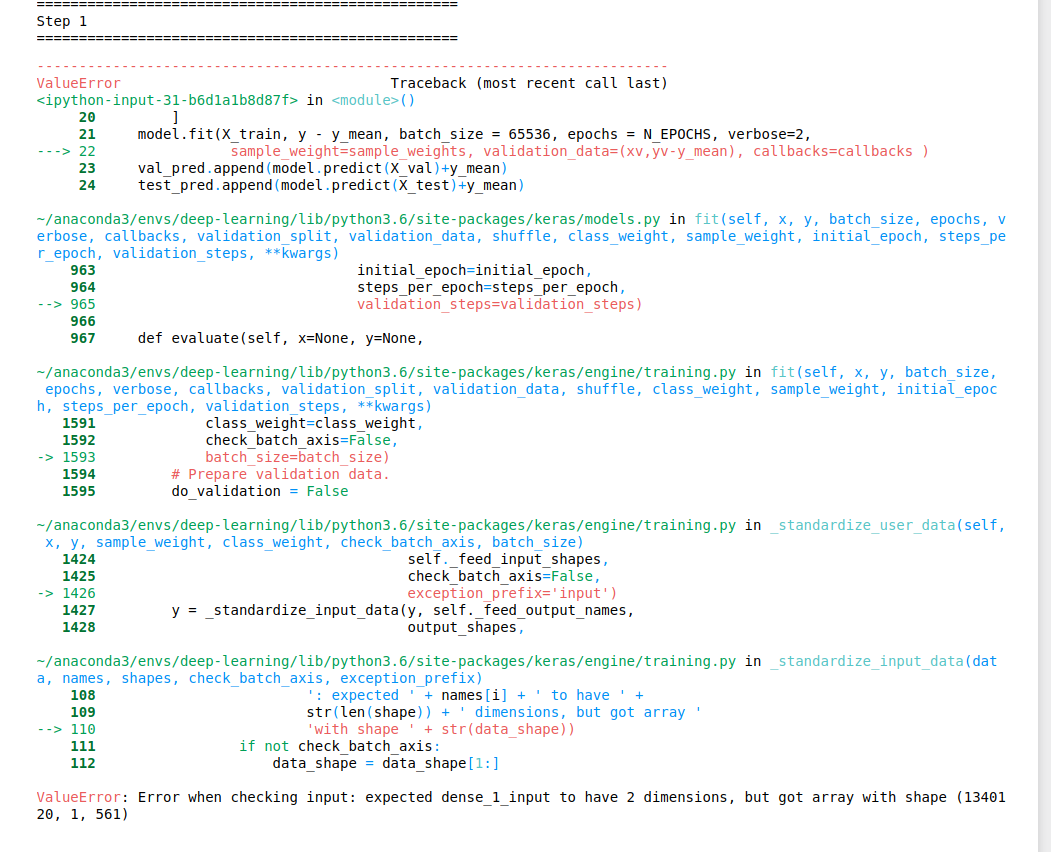
Generates the following error (I didn’t try to investigate, just pasted it and run the code).
Thanks a lot for your help @s.s.o but it didn’t work (not you to blame, just my noobish debugging skills).
It’s pretty late in Stockholm now, maybe 02:00, so I’ll give it a try again tomorrow.
In any case, the basic Jupyter Notebook should be working fine so I’ll try and post it on GitHub,
Here’s an edited Jupyter Notebook for the 1st place solution.
This version, running on 15 epochs per set, 40sec per epoch on 1080Ti, scores 0.519 on the Private LB to get a Silver Medal.
With @radek’s comment, I got the “But of course !” moment about the 16 networks, each one dedicated to forecasting a single day of the 16 days in Test
Another thing I found very neat is his careful choice of validation dates: he didn’t go for the last 16 days before the Test starting date (2017-8-16) , bluntly that should be 2017-7-31 -> 8-15.
He chose instead the latest 16 days’ Train bracket which most resembled the 16 days’ Test, that is 2017-7-26 -> 8-9.
Doing so, he made sure the two sets had the same number of respective weekdays (like 3 medium sales volume Wednesdays/Thursdays, vs 3 low volume Mondays/Tuesdays.) + it fully captured the end-of-month week-end where payroll is about to drop but is a banking holiday for payment with credit/Visa cards, so people won’t be charged until next Monday (a validation starting on Monday July 31 would miss the boost of previous final friday/saturday of July).
I’m working on porting my simple NN from keras to fastai.
I ran into a problem with the apply_cats method. I created the categories on my training set but the test set has some item_nbr values not present in the training set.
I refactored to add an optional null_check. Since this has potential performance implications I left it as an optional check.
Posting here first to see if anyone has comments/feedback before submitting a pull request. This method is looking a bit awkward, probably ways to refactor.
def apply_cats(df, trn, null_check=False):
for n,c in df.items():
if (n in trn.columns) and (trn[n].dtype.name=='category'):
df[n] = pd.Categorical(c, categories=trn[n].cat.categories, ordered=True)
if null_check and df[n].isnull().values.any():
raise ValueError(f'Target dataframe has null values for column {n}. This can occur if the target dataframe has category values not present in original.')
(I left out the data prep because it is the same.)
I tried to create the same model, loss functions, embeddings, etc. to see if I could get the same results.
It’s worth noting that this is an unusual dataset - so don’t draw any sweeping conclusions from the comparisons. I only have 4, features, 20K trainable params. There 37 million training examples.
Plus I could have made a mistake. Maybe @jeremy will see something I missed.
Observations
Fastai is much, much easier to use than Keras.
I had to write much less code to prep for training. Building a custom loss function was trivially easy. Fastai has lots of helping functions that just makes it easier.
No way I’m going back to Keras.
Unfortunately my loss in the fastai model is about 2x worse than what I achieved in Keras.
Here is what I checked.
Feature engineering is the same. I ran the same python code as previously to get the 3 category and 1 continuous features.
The models have the same number of trainable parameters.
The models have the same loss function, MAE.
I normalized both targets using the same function.
Training the fastai model is 10-20x slower than Keras.
I think Keras is copying the entire dataset to the GPU and then doing the training. Since I’m using gigantic batch sizes it runs very fast in Keras, about 22 secs. Takes >5 mins in fastai.
A bit of a long shot but the difference in training speed might be due to not using multiple cores for loading the data. Could you please check your CPU saturation using something like htop?
Slightly doubt this might be the culprit but was the best idea I got thus far.
(another thing would be pinning the memory - I think it might be an argument to one of the methods for dataset creation, maybe check the signatures and see if you can set it to true?)
Sorry for such far fetched ideas but that is all I have at this point… If the loss is twice as high then whatever other thing is amiss here might be causing the slowdown as well (some difference in architecture, etc).
A bit of a long shot but the difference in training speed might be due to not using multiple cores for loading the data. Could you please check your CPU saturation using something like htop?
I think that’s it. IIRC training under Keras would max my CPUs. With fastai it barely got above 1%. I’ll try to go back and test.
At the moment I’m digging through this mess looking for other features.
Pardon the rant … but I’m annoyed at the level of cutting-and-pasting by Kagglers who don’t actually understand what the code is doing. The level of rigor between the fastai community and Kaggle is astounding.
At the moment I’m digging through this mess looking for other features.
Exactly the challenging part for me to understand from the whole competition Than I sit and study the multi indexing and grouping in pandas again
Also thank you for sharing the code… I think batch size bigger than usual was some how not a big problem for time series. Even it may score better… I tried it also for Recruit Restaurant Visitor Forecasting challenge and it was not problem two.
The winner took 3 key steps to generate the features:
Build dataframes indexed on store/item with dates as columns.
Pick a single date and build time-based features on that date.
Pick another date, build the same feature, and concatenate with the previous date.
90% of the code expands on these 3 steps. I created simple, 1-feature example in the notebook above which illustrates it.
The target variable is simply a prediction of the sales for a store/item combination on any number of subsequent days. 16 days is used in this example because the test set is 16 days long.
Genius or madness?
I can’t decide if I hate or love this approach. There is a lot I don’t like about it. Removing “date” as the organizing principle for the training data makes the entire workflow complex and unintuitive. There also seems to be enormous feature redundancy.
On the positive side it is more “pythonic” (and much faster) to generate the time-based features by running functions across DataFrame columns rather than looping through date rows as in the Rossman example. Presumably you could follow the same technique for weather data or anything else date related.
In any case, I’ll have to spend some more time with it to see if I can beat the winning entry with a simpler approach.
An early hypothesis on why it may have won …
It may be that simply training each example against 16 targets (the dates) makes a more robust example than training against 1 date. The loss functions can be more accurate because they capture more information than from a single example.
Hopefully if I keep writing about this and showing off the efficiency of the efficiency of the fastai library @jeremy will weigh in with an opinion.


 ) on a lighter/faster version, with less epochs per step (15 max, so Callbacks probably can’t kick in), to experiment with different parameters, including the “why choose LSTM over Dense in the first layer”.
) on a lighter/faster version, with less epochs per step (15 max, so Callbacks probably can’t kick in), to experiment with different parameters, including the “why choose LSTM over Dense in the first layer”.
 Than I sit and study the multi indexing and grouping in pandas again
Than I sit and study the multi indexing and grouping in pandas again 
