Thanks @s.s.o but it’s not working.
Maybe @jeremy has a tip ? (sorry to use that @jeremy but I’m lost here).
Sorry, I’m just now starting V2 of the course to learn pytorch & the fast.ai libraries. Let us know if you fix it, otherwise I’ll keep a look out for a similar error if I hit one.
Has anyone else experimented with very large batch_sizes in this dataset? I’m asking because I achieved better results with very large (e.g. >100,000) batch_sizes. I normally try to speed things up by using more GPU memory.
In the background I run
nvidia-smi -l 1
On a terminal window to monitor my GPUs.
Here’s a post on Solution #8 (CPMP & Giba current rank#2, who won Blue Book for Bulddozers, among others).
They didn’t use “item_nbr” in their model…
2 Likes
This was a very interesting read, thanks for sharing!
I’m trying to figure out how they managed not to use “item_nbr” in their model, CPMP confirmed it on KN “using items led to overfit” so " item_nbr is not one of the features we use." 
Also I’d really like to make my model work with Fastai, that m.predict() error drove me nuts with all the time I spent building from Rossmann (which was a fabulous learning XP as several of you said already).
Failing to make a submission to check its performance vs the Leaderboard: Grrrr…
It was a difficult challenge for me but I learn a lot. At the beginning the memory hungry merging was the real bottleneck, which, I needed for roseman like embedding. Than, I noticed that the continuous data was not enough to make good model even I was below the mean model. Later, I start to use mean data with new features as in public kernels. Pitty that I had no enough time to add embeddings to mean model … I spend a lot of time and stack with multi-indexing and merging problem with pandas.
Kevin use it and shared given above. I didn’t use myself fastai lib. it’s on my to do list.
I checked Kevin’s DataPrep.ipynb notebook where he has shared the data-preparation not the modeling part using fastai. @kevindewalt Thank you for sharing. Also is p2.xlarge good enough to run the notebook?
1 Like
I had a very similar experience… In general seems that IO is a major, major area to figure out - I have been having issues across multiple projects to the point where I started doing some research and writing a monster post on it  (it’s still in the works).
(it’s still in the works).
With regards to this specific pandas issue, I solved it doing this (basically just used an NVME drive as swap): https://twitter.com/radekosmulski/status/953596228838752256
1 Like
Here’s how I handled memory limitations:
- Watch dtypes. Convert to the smallest integers that work. Convert booleans to int8. Run df.info() periodically.
- Keep track of big dataframes, keep deleting them. Especially ones in loops.
- Buy more RAM.
 I upgraded to 64 GB.
I upgraded to 64 GB. - Increase swap space on NVME drive.
- Within a tmux pane keep
toprunning. Track CPU and %Mem usage.
I always have top running in a tmux pane and alias nvidia-smi -l 1 running in another. That lets me track system utilization at a glance.
Hope it helps!
3 Likes
FYI I’ve been having RAM issues for my NLP work recently, so have started using the chunklen param in pandas when reading the CSV, to process it a chunk at a time. It adds complexity and code, but it’s a good approach for large datasets.
5 Likes
Pandas also have a nice parameter ‘downcast’ for numeric types eg. pd.to_numeric(series, downcast=‘float’) When downcasted the resulting data to the smallest numerical dtype possible. As explained in the docs it follows below rules:
- ‘integer’ or ‘signed’: smallest signed int dtype (min.: np.int8)
- ‘unsigned’: smallest unsigned int dtype (min.: np.uint8)
- ‘float’: smallest float dtype (min.: np.float32)
Hey @jeremy,
You mentioned in one of the videos that you would post your Fastai notebook for Favorita, AFTER the competition ends, due to regulations and ethics for Kaggle rules 
Any chance you could do so ?
There might be more than my humble self looking for it, especially how you went from training (I think I got that right) to predicting/submitting (I failed that part with Fastai library).
/kudos !
Jeremy,
If you’re looking for porting a Favorita top solution to Fastai library as you did with Rossmann 3rd Place: one of the 1st Place team members in Favorita posted a single Keras+Tensorflow kernel.
https://www.kaggle.com/shixw125/1st-place-nn-model-public-0-507-private-0-513/code
I tested it and it works “out of the box” with Keras: takes about 10hours to run on a 1080Ti and achieves 0.513 on Private LB (3rd place).
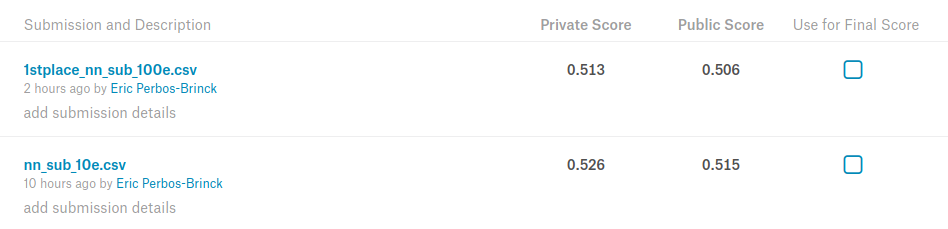
Here’s the Favorita Private Leaderboard
Took up to 48 Gb of RAM though during the Join_Tables & Feature Engineering phase (the swap file helped a lot).
6 Likes
Thanks for posting … I hope to dig through this in detail this weekend and port to fast.ai library if I have time.
1 Like
The two useful things to know here would be what is the shape of X_train?
I wonder what this layer returns, what dimensionality is the output:
model.add(LSTM(512, input_shape=(X_train.shape[1],X_train.shape[2])))
@EricPB, if you would have this already on your computer and it wouldn’t be too much of a problem, would you be so kind and check these two things?
I am thinking that output from model.summary() might also provide some insights.
I was planning to implement @Lingzhi’s model and looked at the code for quite a while where I now think I understand what it does. Am caught up with a lot of other things ATM and the 2nd part of the course is just around the corner… (still crossing my fingers I’ll get in  ).
).
The cool thing with this kernel is that we could literally copy the code to line 232 and this should give us the dataset… should be a great starting point for messing around with this.
1 Like
X_train.shape
(1340120, 1, 561)
model.summary()
Layer (type) Output Shape Param #
=================================================================
lstm_16 (LSTM) (None, 512) 2199552
_________________________________________________________________
batch_normalization_106 (Bat (None, 512) 2048
_________________________________________________________________
dropout_106 (Dropout) (None, 512) 0
_________________________________________________________________
dense_106 (Dense) (None, 256) 131328
_________________________________________________________________
p_re_lu_91 (PReLU) (None, 256) 256
_________________________________________________________________
batch_normalization_107 (Bat (None, 256) 1024
_________________________________________________________________
dropout_107 (Dropout) (None, 256) 0
_________________________________________________________________
dense_107 (Dense) (None, 256) 65792
_________________________________________________________________
p_re_lu_92 (PReLU) (None, 256) 256
_________________________________________________________________
batch_normalization_108 (Bat (None, 256) 1024
_________________________________________________________________
dropout_108 (Dropout) (None, 256) 0
_________________________________________________________________
dense_108 (Dense) (None, 128) 32896
_________________________________________________________________
p_re_lu_93 (PReLU) (None, 128) 128
_________________________________________________________________
batch_normalization_109 (Bat (None, 128) 512
_________________________________________________________________
dropout_109 (Dropout) (None, 128) 0
_________________________________________________________________
dense_109 (Dense) (None, 64) 8256
_________________________________________________________________
p_re_lu_94 (PReLU) (None, 64) 64
_________________________________________________________________
batch_normalization_110 (Bat (None, 64) 256
_________________________________________________________________
dropout_110 (Dropout) (None, 64) 0
_________________________________________________________________
dense_110 (Dense) (None, 32) 2080
_________________________________________________________________
p_re_lu_95 (PReLU) (None, 32) 32
_________________________________________________________________
batch_normalization_111 (Bat (None, 32) 128
_________________________________________________________________
dropout_111 (Dropout) (None, 32) 0
_________________________________________________________________
dense_111 (Dense) (None, 16) 528
_________________________________________________________________
p_re_lu_96 (PReLU) (None, 16) 16
_________________________________________________________________
batch_normalization_112 (Bat (None, 16) 64
_________________________________________________________________
dropout_112 (Dropout) (None, 16) 0
_________________________________________________________________
dense_112 (Dense) (None, 1) 17
=================================================================
Total params: 2,446,257
Trainable params: 2,443,729
Non-trainable params: 2,528
2 Likes