You’re doing great! Here’s the thing to think about: regularization penalizes coeffs that are larger. By using NB features, we don’t have to use such large coeffs to get the same result, compared to using plain binary features.
Once you’ve understood that, you’ll soon realize that NB-SVM still isn’t ideal - since we’d really like a zero coeff to represent our prior expectation as to the behavior of that feature. At that point, we can start to talk about the extension I made to NB-SVM which is the current state of the art in linear models for sentiment analysis! (Which no-one has written up yet - so if you get to the point you understand this bit, you can be the first person to put it down in writing… You’re well on the way to being there.)
is there a way to follow you on twitter without being on twitter? rss to email or somesuch?
you know … just while I’m spending all my time on here learning like crazy and already being distracted by so much to read
Hi all,
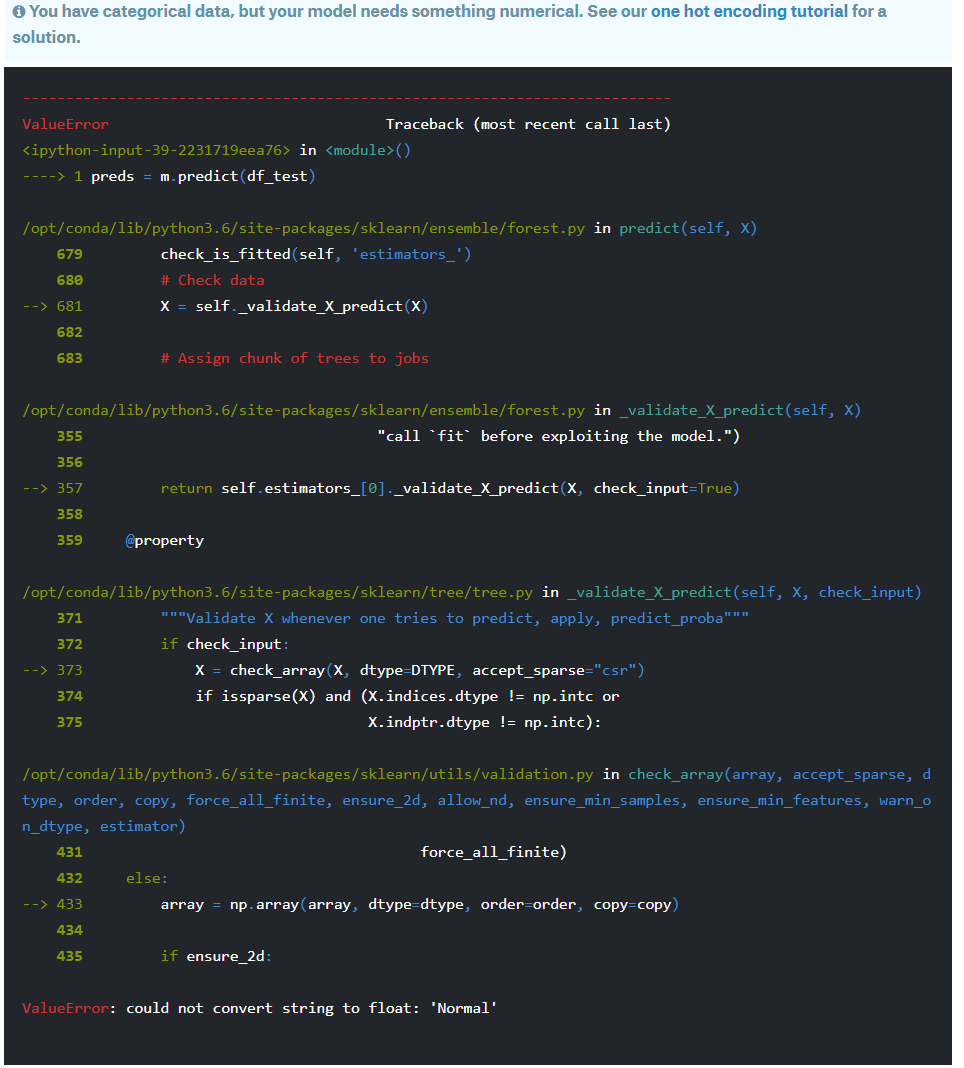
I’m while attempting the Kaggle competition[1] “House Prices: Advanced Regression Techniques”. I pretty much follow the exact same approach and I managed to obtain a score of 0.94 with RandomForestRegressor. My next step was to use test data set (this competition provides both training and test data separately). I pretty much did the exact same things to the test data before using predict() function to predict the values. When I try to apply the predict function to test set I get the following error “ValueError: could not convert string to float: ‘Normal’”
Does it make sense now to have a ML part on the forum (like DL part1 , DL part2)?
It seems like ML could have at least 4 wiki style posts for topic based questions, rather than them all coming as comments here
Me too man, perhaps we should enroll in USF master program next academic year, haha.
Ah anyway, did anyone of you guys tried Random Forest Classifier using fastai?
Or any resource to read, any implementation, any notebook sample I could see?
Just finish Random Forest Regressor for my own problem, now I had classification problem for structured data, wanna give Random Forest Classifier a shot, but, lost direction, haha, please advise.
Where can I find a notebook used in lesson 3?
Lessons 2 and 3 from github contain buldozers data set while Lesson 3 on youtube is focused on groceries data.
Could you please update github with the missing notebook?
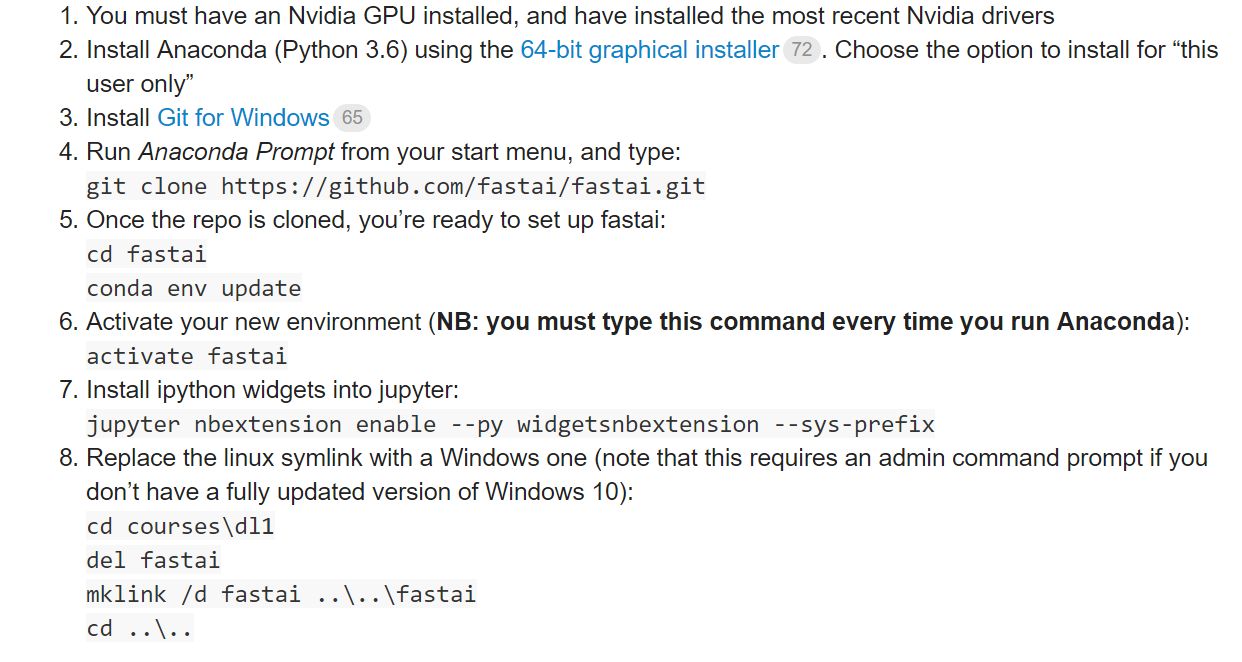
I have made it to Lesson 8 and everything in the fastai repo has worked perfectly up to this point. I have a windows 10 machine with 64 bits. I have read many forums that this maybe something that will work once pytorch comes out with a windows version. I have a paperspace account, where this works fine, but would love to be able to have it work on my machine locally.
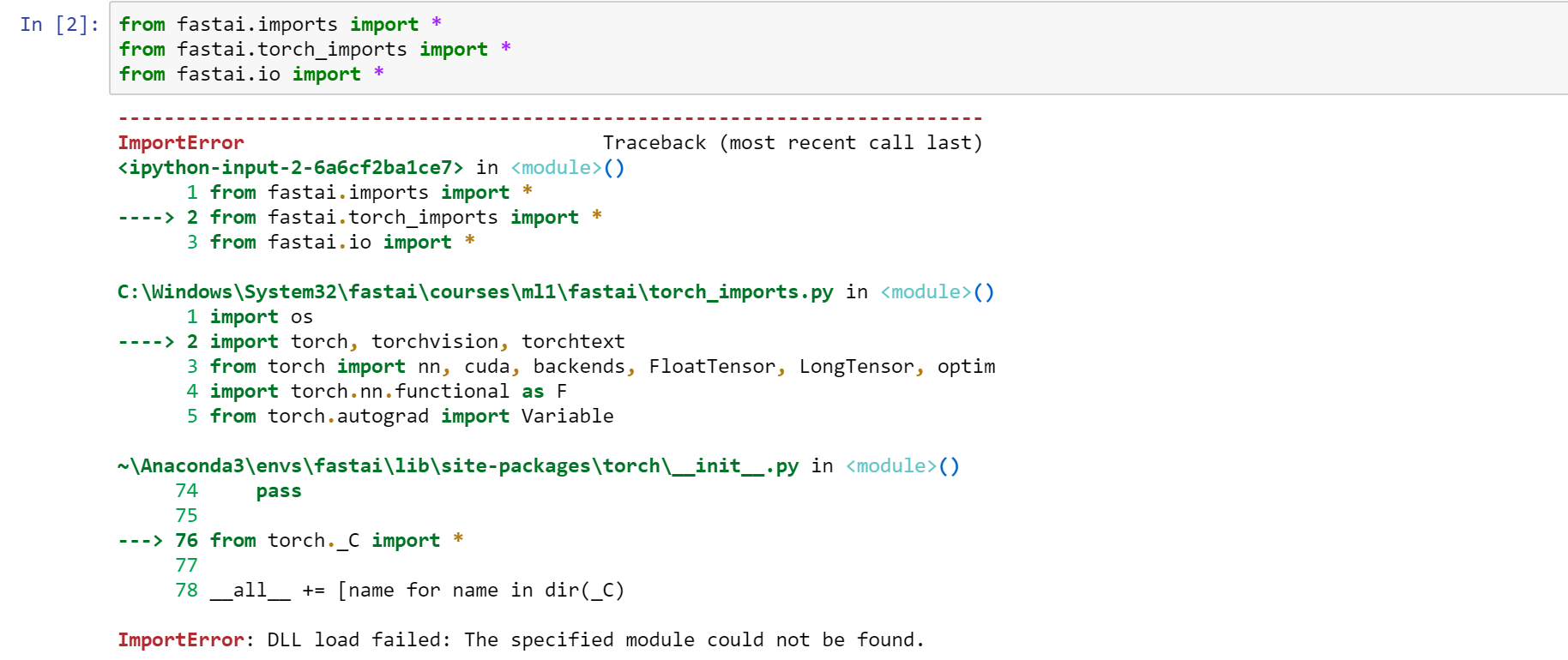
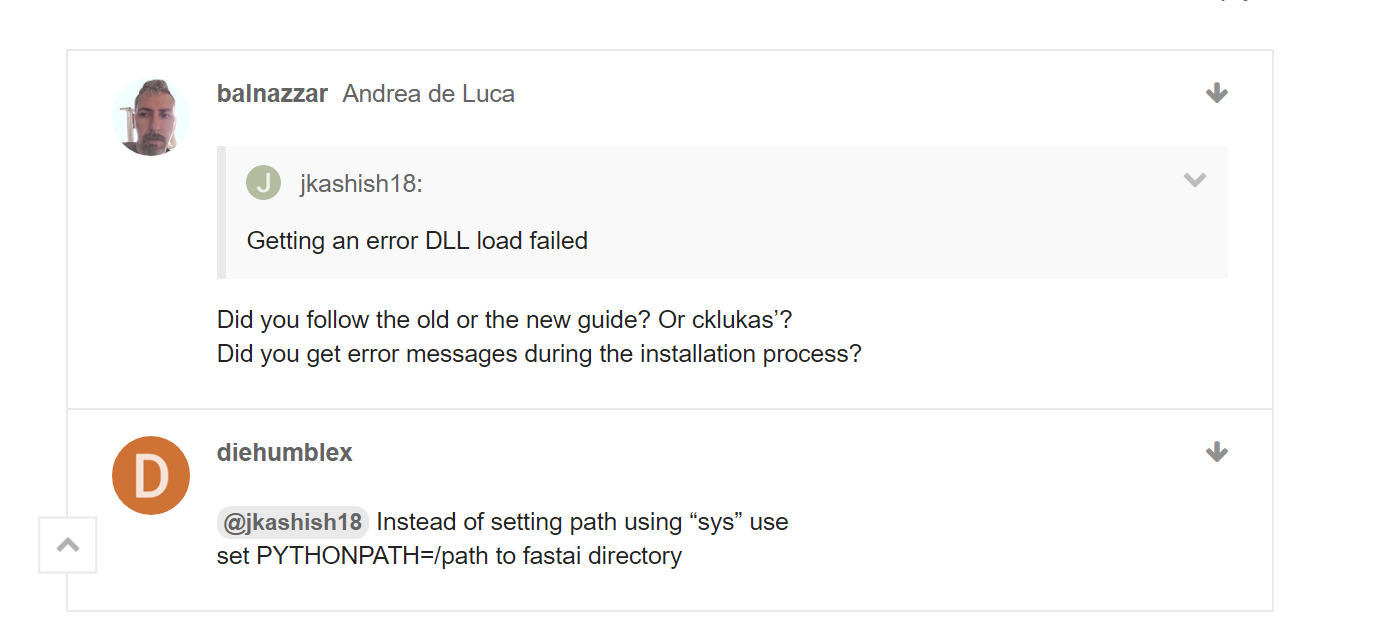
I have come across an issue of: DLL Load Failed and this has to do with torch_imports and the fastai.io import
I also have spacy downloaded, but i am not sure if thats the answer because i don’t know how to use the spacy environment.
There was a similar question to this on an installation page and these were to the two answers and i am unsure on how to set PYTHONPATH=/path to the fastai directory
 Here’s the thing to think about: regularization penalizes coeffs that are larger. By using NB features, we don’t have to use such large coeffs to get the same result, compared to using plain binary features.
Here’s the thing to think about: regularization penalizes coeffs that are larger. By using NB features, we don’t have to use such large coeffs to get the same result, compared to using plain binary features.