Using the Youtube transcript or generating a Whisper transcript might also be useful for getting the exact timestamps where sections start.
1 Like
Not a bad idea. The only other idea I had was to parallelize the workflow. One person does the timestamps from beginning to break time. The other does it for after the break to end
1 Like
Lesson 11 is done. It is a Google Doc in .vtt format.
Lesson 11: Deep Learning Foundations to Stable Diffusion, 2022
Here the “raw” Whisper output:
Lesson_11_2022.vtt
2 Likes
Whisper output for lesson 12:
EDIT: Sorry, this was done for the “Stream” version:
Stream - Lesson 12_Deep Learning Foundations to Stable Diffusion, 2022.vtt
Whisper output for lesson 13:
Lesson 13_Deep Learning Foundations to Stable Diffusion, 2022.vtt
1 Like
@jeremy Lesson 12 done. @andreilys would you like me to do half of Lesson 13 or would you like to try marking the whole lesson out for yourself?
1 Like
Transcriptions for Lesson 11 and 12 are done:
Lesson 11: Deep Learning Foundations to Stable Diffusion, 2022
Lesson 12: Deep Learning Foundations to Stable Diffusion, 2022
The transcriptions were based on the following Whisper outputs:
Lesson_11_2022.vtt
Lesson_12_2022.vtt
3 Likes
Wow champion! ![]()
Done
Lesson 13
0:00 - Introduction
2:54 - Linear models & rectified lines (ReLU) diagram
10:15 - Multi Layer Perceptron (MLP) from scratch
18:15 - Loss function from scratch - Mean Squared Error (MSE)
23:14 - Gradients and backpropagation diagram
31:30 - Matrix calculus resources
33:27 - Gradients and backpropagation code
38:15 - Chain rule visualized + how it applies
49:08 - Using Python’s built in debugger
1:00:47 - Refactoring the code
1:15:13 - PyTorch’s implementation
1:18:10 - Improving loss function from mean squared error (MSE) to softmax
1:25:25 - Log/exponent rules
1:33:33 - LogSumExp and negative log likelihood
1:38:42 - Training loop implementation
2 Likes
Done
Lesson 14
0:00:00 - Introduction
0:00:30 - Review of code and math from Lesson 13
0:07:40 - f-Strings
0:10:00 - Re-running the Notebook - Run All Above
0:11:00 - Starting code refactoring: torch.nn
0:12:48 - Generator Object
0:13:26 - Class MLP: Inheriting from nn.Module
0:17:03 - Checking the more flexible refactored MLP
0:17:53 - Creating our own nn.Module
0:21:38 - Using PyThorch’s nn.Module
0:23:51 - Using PyThorch’s nn.ModuleList
0:24:59 - reduce()
0:26:49 - PyThorch’s nn.Sequential
0:27:35 - Optimizer
0:29:37 - PyTorch’ optim and get_model()
0:30:04 - Dataset
0:33:29 - DataLoader
0:35:53 - Ramdom sampling, batch size, collation
0:40:59 - What does collate do?
0:45:17 - fastcore’s store_attr()
0:46:07 - Multiprocessing DataLoader
0:50:36 - PyThorch’s Multiprocessing DataLoader
0:53:55 - Validation set
0:56:11 - Hugging Face Datasets, Fashion-MNIST
1:01:55 - collate function
1:04:41 - transforms function
1:06:47 - decorators
1:09:42 - itemgetter
1:11:55 - PyTorch’s default_collate
1:15:38 - Creating a Python library with nbdev
1:18:53 - Plotting images
1:21:14 - **kwargs and fastcore’s delegates
1:28:03 - Computer Science concepts with Python: callbacks
1:33:40 - Lambdas and partials
1:36:26 - Callbacks as callable classes
1:37:58 - Multiple callback funcs; *args and **kwargs
1:43:15 - __dunder__ thingies
1:47:33 - Wrap-up
Contributors:
fmussari
2 Likes
Transcription for Lesson 13 is ready:
Lesson 13: Deep Learning Foundations to Stable Diffusion, 2022
For this lesson Whisper gave some repeated fragments and time stamps out of synch, so I remove those lines and all the timestamps. Here the original Whisper output:
Lesson_13.vtt
2 Likes
Can you describe what process you’re using for creating these? I’d be very interested to hear about what you’ve discovered and come up with.
Hi Jeremy, I’m going to start saying that the process, when starting from youtube closed captions took me about 1 hour per 10 min of video. Now with Whisper I think it takes about 4 hours for the entire lesson. Which is great. Whisper is very impressive in terms of accuracy both in words and punctuations. I think the time could be less, but I change lots of things that, maybe, are not essential for the understanding.
The process I take
-
Using the library from repository Automatic YouTube subtitle generation.
-
I Created this simple Colab Notebook Generate .vtt from Youtube.ipynb. There you can see the code for getting Whisper transcriptions from Lesson 11 to Lesson 14.
-
Then copy and paste the
.vttfile to Google Docs and edit it.
Some things I have edited
Lesson 11 and 12 were pretty accurate in terms of transcription.
The changes were mostly styling. I found it difficult to keep a defined style, so I’m trying to “stablish” one. There are things that I simply change because of personal preference, or because I think is more clear for understanding.
Some corrections:
-
Corrected user names or names. For this, sometimes I searched in the streamed version to see the exact user name or name in the chat. Examples: Maribou → mariboo, Tanishk → Tanishq, Michelage → Mikołaj
-
Sometimes I change numbers that are transcribed as words to actual numbers. In some cases I added thousand separators.
-
I try to keep variable names equals to the video. Capital or small letters. Added underscores.
-
When you talked about fastai lessons, I wrote them starting with capital teller followed by numbers like this: Lesson 10. And same with parts: Part 1, or Part 2.
-
Sometimes I found clearer to write formulas. Sometimes I added, like, “[None, :, None]” instead of the “none comma colon comma none”. Or “(a < b).float().mean()” instead of “A less than B dot float dot mean”, “gaussian??” instead of “Gaussian question mark, question mark”.
-
Added quotes when you were literally reading from a paper.
-
Added parenthesis at the end when you were naming a caller, also add underscores to its names when they have them in the code.
-
Although Whisper is great with punctuation, I added some commas or points or dashes. Few of those additions were, I think, a considerable improvement for the understanding. Some of them weren’t essential.
-
Sometimes the models removes some “you know’s”, or similars.
Some words that were edited (sometimes the model got them right):
- Archive → arXiv, diffedit → DiffEdit. Pix2Tech → pix2tex. CoLab → Colab. detectify → Detexify. number → Numba. a race → arrays. access → axis. main → mean. Clip → CLIP. blip → BLIP. insum, onesum, ionsum, einsam → einsum. admit → omit. map model, mapmole → matmul. plot funk → plot_func. funk tools → functools. carrying → currying. Oopsie dokie → Oopsie-Daisy. two JSHTML → to_jshtml(). two HTML five video → to_html5_video(). attraction → substraction. the Y to U, the YDU → dY/dU. Simpei → SimPy, unscrews → unsqueeze.
In Lesson 13 there were some segments that were not in the video, or that were somehow repetitions, so I had to delete them:
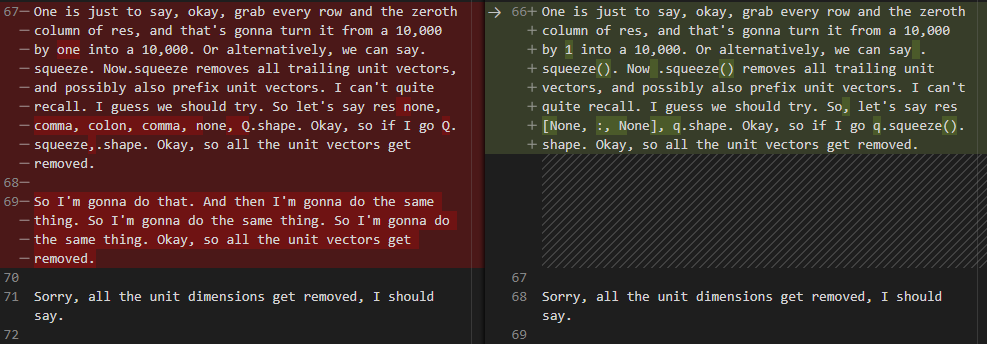
I was thinking that the script was somehow downloading the non edited version of the video. But this happened only in Lesson 13.
Conclusions
- There are many corrections that are very subtle and that require some decisions.
- Some things I change are simply personal preferences, and maybe are not essential for the understanding.
- There are aspects that would be great to standardize. (Variable and functions naming, operations, numbers).
- The errors in sync in Lesson 13 make me wonder if there were sync problems on Lesson 11 and 12 where I kept the timestamps. I’m sure there weren’t blocks of text that weren’t in the video (or that were repetitions ofsome line), like in Lesson 13. I wonder, given that youtube syncs the CC, if it would be better to remove timestamps generated by the library I use.
- If we take into account that the text is not supposed to be self contained, and that it is an addition to the video, many of the manual edits are not essential for understanding, but they give some styling and consistency, although, even for a human (me), consistency hasn’t been easy to achieve and I keep stablishing new standards and styles on the go.
6 Likes
Chapters and transcription are ready.
Transcription:
Lesson 14: Deep Learning Foundations to Stable Diffusion, 2022
2 Likes
While I was waiting for the edited video of Lesson 15 -to start transcribing it, I did something related with transcriptions of fastai’s YouTube playlists. It’s something that I sometimes find useful.
It is a web app done with Streamlit that allows to do a Full-Text Search of fastai Youtube Playlists.
The process and code is documented in these two posts:
Building a Full-Text Search Engine for fastai YouTube channel
Part 1. Extracting transcriptions and creating SQLite’s searchable index
Part 2. Deploying the web app to Streamlit
Example search
This is how a search like «fastcore OR parallel» looks like:

5 Likes
I’ve actually been working on for a little while now. I should have a website available for this in the next week or so.
Nice! Do you have a tweet about this that I can share?
1 Like
Done
Lesson 15
0:00:00 - Introduction
0:00:51 - What are convolutions?
0:06:52 - Visualizing convolutions
0:08:51 - Creating a convolution with MNIST
0:17:58 - Speeding up the matrix multiplication when calculating convolutions
0:22:27 - Pythorch’s F.unfold and F.conv2d
0:27:21 - Padding and Stride
0:31:03 - Creating the ConvNet
0:38:32 - Convolution Arithmetic. NCHW and NHWC
0:39:47 - Parameters in MLP vs CNN
0:42:27 - CNNs and image size
0:43:12 - Receptive fields
0:46:09 - Convolutions in Excel: conv-example.xlsx
0:56:04 - Autoencoders
1:00:00 - Speeding up fitting and improving accuracy
1:05:56 - Reminding what an auto-encoder is
1:15:52 - Creating a Learner
1:22:48 - Metric class
1:28:40 - Decorator with callbacks
1:32:45 - Python recap
Contributors:
Raymond-Wu, fmussari
3 Likes
Thanks Jeremy, I recovered an old personal account and mentioned you in a tweet.
Chapters and transcription are ready.
Transcription:
Lesson 15: Deep Learning Foundations to Stable Diffusion, 2022
4 Likes
Could you please share a link here? I’m not able to see all the mentions I get on Twitter unfortunately.